
一月一日 等待变化等待机会
| pair | tuple | variant | optional |
| product type | product type | sum type | sum type |
| Year | C++ Standard | Informal name |
|---|---|---|
| 1998 | ISO/IEC 14882:1998 | C++98 |
| 2003 | ISO/IEC 14882:2003 | C++03 |
| 2011 | ISO/IEC 14882:2011 | C++11,C++0x |
| 2014 | ISO/IEC 14882:2014 | C++14,C++1y |
| 2017 | ISO/IEC 14882:2017 | C++17,C++1z |
| 2020 | ISO/IEC 14882:2020 | C++20,C++2a |
一月二日 等待变化等待机会
一月三日 等待变化等待机会
1,2,3,4,5,而不是通常的make_integer_sequence的从0开始了。
一月四日 等待变化等待机会
可执行文件尽量采用静态链接,包括libgcc和libstdc++,可以减轻部署的复杂性,减少对编译器升级的负担。让人有些启发,不过我曾经经历过静态库的循环依赖,在link过程中很痛苦的调整库之间的顺序,甚至一个库要反复出现,也许是我的编译方法有问题,但是编译静态库显然要复杂的多吧,就是要把所有的依赖库都编译一遍压力可想而知,难怪编译速度是大问题。
1;201709;gccTest.cpp;3228;Jan 4 2021;05:20:07;1;里为什么__cplusplus定义为2017呢?我的编译器明明已经指向了gcc-10.2.0了?这里有位大侠这么解释
实际上我看到有人指出标准委员会的网页,其实并没有提到c++20,今天已经2021年了,已经通过的新标准还没有被委员会接受吗? 这个是所谓的标准(它的出处我还需要再查询),那么源代码怎么说的呢?我搜索gcc-10.2.0的源代码,在changelog里有这样的log: 看来我的编译文件没有错误,这个的确是gcc-10.2.0的情况,进一步查询这个
- The 199711L stands for Year=1997, Month = 11 (i.e., November of 1997) -- the date when the committee approved the standard that the rest of the ISO approved in early 1998.
- For the 2003 standard, there were few enough changes that the committee (apparently) decided to leave that value unchanged.
- For the 2011 standard, it's required to be defined as 201103L, (again, year=2011, month = 03) again meaning that the committee approved the standard as finalized in March of 2011.
- For the 2014 standard, it's required to be defined as 201402L, interpreted the same way as above (February 2014).
- For the 2017 standard, it's required to be defined as 201703L (March 2017).
- For the 2020 standard, the value has been updated to 202002L (February 2020).
- Before the original standard was approved, quite a few compilers normally defined it to 0 (or just an empty definition like #define __cplusplus) to signify "not-conforming". When asked for their strictest conformance, many defined it to 1.
init.c可以看到
这个说明了什么呢?这个CLK_CXX2A显然是c++20的代号,至于是否是最终代号我不知道,也许是某个过渡?但是也许就是最终的。但是无论如何对于gcc-10.2.0它就是定义的201709。
| initials | full flag |
|---|---|
| c99 | c99 |
| c++ | cplusplus |
| xnum | extended_numbers |
| xid | extended_identifiers |
| c11 | c11_identifiers |
| std | std |
| digr | digraphs |
| ulit | uliterals |
| rlit | rliterals |
| udlit | user_literals |
| bincst | binary_constants |
| digsep | digit_separators |
| trig | trigraphs |
| u8chlit | utf8_char_literals |
| vaopt | va_opt |
| scope | scope |
| dfp | dfp_constants |
0,1,2,
一月五日 等待变化等待机会
/home/nick/opt/gcc-10.2.0/bin/c++ ${FLAGS} -E -P -v -dD "${INPUTS}" -std=c++20
其次似乎不是很必要吧在CDT GCC Builtin Output parser修改为(g?cc)|([gc]\+\+)|(clang) -std=c++20这样子可以自动产生编译器的默认设置。
一月六日 等待变化等待机会
一月七日 等待变化等待机会
这个是什么意思呢?是说inline无效吗?inline难道不是我们理解的inline吗?The three types of inlining behave similarly in two important cases: when the
inlinekeyword is used on astaticfunction, like the example above, and when a function is first declared without using theinlinekeyword and then is defined withinline, like this:extern int inc (int *a); inline int inc (int *a) { return (*a)++; }In both of these common cases, the program behaves the same as if you had not used the
inlinekeyword, except for its speed.
When a function is both inline and static, if all calls to the function are integrated into the caller, and the function's address is never used, then the function's own assembler code is never referenced. In this case, GCC does not actually output assembler code for the function, unless you specify the option -fkeep-inline-functions.这个当然是我们理解的,那么为什么无效呢?这里我对于gcc的声称也是半信半疑,实际上我确实看到了函数体的汇编代码,即便是static(就是local function)但是似乎在没有优化的情况下没有变化的。也许说的是优化以后的情况吧?我做了一下-O2/-O1的编译的实验结果inc函数的代码彻底就被优化掉了,因为他们本身就没有存在的价值,所以看不出来这个被优化成了我们希望的inline的模式。inline有和没有确实没有区别!
000000000000066a <main>: 66a: 55 push %rbp 66b: 48 89 e5 mov %rsp,%rbp 66e: 48 83 ec 10 sub $0x10,%rsp 672: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax 679: 00 00 67b: 48 89 45 f8 mov %rax,-0x8(%rbp) 67f: 31 c0 xor %eax,%eax 681: c7 45 f4 00 00 00 00 movl $0x0,-0xc(%rbp) 688: 48 8d 45 f4 lea -0xc(%rbp),%rax 68c: 48 89 c7 mov %rax,%rdi 68f: e8 16 00 00 00 callq 6aa <inc(int*)> 694: 48 8b 55 f8 mov -0x8(%rbp),%rdx 698: 64 48 33 14 25 28 00 xor %fs:0x28,%rdx 69f: 00 00 6a1: 74 05 je 6a8 <main+0x3e> 6a3: e8 98 fe ff ff callq 540 <__stack_chk_fail@plt> 6a8: c9 leaveq 6a9: c3 retq 00000000000006aa <inc(int*)>: 6aa: 55 push %rbp 6ab: 48 89 e5 mov %rsp,%rbp 6ae: 48 89 7d f8 mov %rdi,-0x8(%rbp) 6b2: 48 8b 45 f8 mov -0x8(%rbp),%rax 6b6: 8b 00 mov (%rax),%eax 6b8: 8d 48 01 lea 0x1(%rax),%ecx 6bb: 48 8b 55 f8 mov -0x8(%rbp),%rdx 6bf: 89 0a mov %ecx,(%rdx) 6c1: 5d pop %rbp 6c2: c3 retq这里在main里我们看到了调用inc的语句
00000000000006aa w F .text 0000000000000019 inc(int*)
所以,这个inline的确无效。不过我们注意到这个inc是一个"weak" symbol。而且我即便把源代码的extern或者static都去掉也是一样,该调用函数还是条用函数,就是说函数的压栈出栈一点也没有少。
但是如果我们把extern改为static iniline呢?注意编译器警告不能或者不应该同时,extern或者static只能二选一。
inline static int inc (int *a){000000000000066a l F .text 0000000000000019 inc(int*)inline int inc (int *a) __attribute__ ((always_inline)); mov -0x8(%rbp),%rdxmov -0x10(%rbp),%rax000000000000066a <main>: 66a: 55 push %rbp 66b: 48 89 e5 mov %rsp,%rbp 66e: 48 83 ec 20 sub $0x20,%rsp 672: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax 679: 00 00 67b: 48 89 45 f8 mov %rax,-0x8(%rbp) 67f: 31 c0 xor %eax,%eax 681: c7 45 ec 00 00 00 00 movl $0x0,-0x14(%rbp) 688: 48 8d 45 ec lea -0x14(%rbp),%rax 68c: 48 89 45 f0 mov %rax,-0x10(%rbp) 690: 48 8b 45 f0 mov -0x10(%rbp),%rax 694: 8b 00 mov (%rax),%eax 696: 8d 48 01 lea 0x1(%rax),%ecx 699: 48 8b 55 f0 mov -0x10(%rbp),%rdx 69d: 89 0a mov %ecx,(%rdx) 69f: 48 8b 75 f8 mov -0x8(%rbp),%rsi 6a3: 64 48 33 34 25 28 00 xor %fs:0x28,%rsi 6aa: 00 00 6ac: 74 05 je 6b3 <main+0x49> 6ae: e8 8d fe ff ff callq 540 <__stack_chk_fail@plt> 6b3: c9 leaveq 6b4: c3 retq
一月八日 等待变化等待机会
毛泽东 一九六三年五月
人的正确思想是从哪里来的?是从天上掉下来的吗?不是。是自己头脑里固 有的吗?不是。人的正确思想,只能从社会实践中来,只能从生产斗争、阶级斗 争和科学实验这三项实践中来。人们的社会存在,决定人们的思想。而代表先进 阶级的正确思想,一旦被群众掌握,就会变成改造社会、改造世界的物质力量。 人们在社会实践中从事各项斗争,有了丰富的经验,有成功的,有失败的。无数 客观外界的现象通过人的眼、耳、鼻、身这五个官能反映到自己的头脑中来,开 始是感性认识。这种感性认识的材料积累多了,就会产生一个飞跃,变成了理性 认识,这就是思想。这是一个认识过程。这是整个认识过程的第一个阶段,即由 客观物质到主观精神的阶段,由存在到思想的阶段。这时候的精神、思想(包括 理论、政策、计划、办法)是否正确地反映了客观外界的规律,还是没有证明的 ,还不能确定是否正确,然后又有认识过程的第二个阶段,即由精神到物质的阶 段,又思想到存在的阶段,这就是把第一个阶段得到的认识放到社会实践中去, 看这些理论、政策、计划、办法等等是否能得到预期的成功。其实在我看来人是否需要正确的思想这个基本问题很多人都没有搞明白,或者不屑于肯定。为什么呢?人的思想是否正确要由谁来评判?各个人内心自己创造出的灵魂主宰命名之为神的精神存在来裁决吗?一个人平常并不需要有什么正确的思想,因为一个人很多时候可以按照他的意愿相信任何他愿意相信的理论,只要他不和时间和世界发生碰撞他可以永远生活在自己的世界里相信任何他自己愿意相信的理论与信仰。唯一能够检验与校验的是现实世界的碰撞,只有当他受到了自然规律的惩罚他才有可能有机会选择采取正确的思想来解释来应对。当然这里仅仅是有机会,因为他的头脑也可以采取另一种策略将一切的现实的惩罚与挫折当作神迹的考验与磨难从而更加坚定自己的信仰与信念。而更加困难的是,同样的正确的思想很多时候也是以概率规律来表现的,并非每一次的负反馈都是现实的正确反应,有时候需要长期的反复的应证才能揭开自然规律的真实面目。这个认识过程是如此的复杂与困难,而当前的人工智能希望透过几个简单的小范围的反复就证明他们的算法已经接近了真理的边缘是不现实的,很多人透过一生的试错都不一定能够积累出足够的数据来正确的解释世界,而我们能够期待人工智能能够这么快就取代人类吗?
一月九日 等待变化等待机会
thread t3(HelloFunction());编译器是会报错的,对于错误的具体所指我不是很明了因为lambda的类型一般很难理解也基本上不希望程序员非常清楚,因为是编译器产生的也许也可以变化,总之程序员不应当依赖于它的类型来操作,这个相比于functor来说是一个进步因为限制了定义functor的随心所欲就能够防止一些莫名其妙的副作用。比如对于打印出来的这个lambda HelloFunction的类型我就是不理解
似乎你还是能够强制做到,但是这个已经最大限度的防止了错误发生了。比如我故意定义个错误的函数
这个函数是怎么调用的我都不理解因为参数要怎么传递呢?从这个t1的类型打印出来看也看不清楚std::thread (test298_namespace::HelloFunction::{lambda()#1} (*)())我知道它的返回值是thread,但是参数是一个函数指针,我只好这么调用它
总之,在thread初始化中使用lambda比直接的functor来的好。
一月十日 等待变化等待机会
C++ source files conventionally use one of the suffixes ‘.C’,
‘.cc’, ‘.cpp’, ‘.CPP’, ‘.c++’, ‘.cp’, or
‘.cxx’; C++ header files often use ‘.hh’, ‘.hpp’,
‘.H’, or (for shared template code) ‘.tcc’; and
preprocessed C++ files use the suffix ‘.ii’. GCC recognizes
files with these names and compiles them as C++ programs even if you
call the compiler the same way as for compiling C programs (usually
with the name gcc).
这个解释了我当时的一些疑惑,因为有的时候好像根本改变编译器宏的定义并不起作用,当时我并没有意识到有些库是c和c++代码混合的产物,尤其是我们自己包装了c的库的结果。
不过这个转折就难说了
However, the use ofgccdoes not add the C++ library.g++is a program that calls GCC and automatically specifies linking against the C++ library. It treats ‘.c’, ‘.h’ and ‘.i’ files as C++ source files instead of C source files unless -x is used. This program is also useful when precompiling a C header file with a ‘.h’ extension for use in C++ compilations. On many systems,g++is also installed with the namec++.
-fvisibility-inlines-hidden选项让我联想起了前几天做的关于inline实验。
The effect of this is that GCC may, effectively, mark inline methods with
__attribute__ ((visibility ("hidden"))) so that they do not
appear in the export table of a DSO and do not require a PLT indirection
when used within the DSO.
我觉得我应该没有设定这个选项,似乎它是异曲同工吧?
std::is_lvalue_reference_v因为我创建的subrange实际上用的是这个ctor
也就是说要满足borrowed_range这个concept,而它是要求is_lvalue_reference的
。至此似乎又回到了起点,难道不是吗?我们能够简单的说所有的view必须要lvalue才行?如果参数本身不是一个view或者它的reference的话。这个结论似乎很简单,但是我这一趟探求原因真的很不容易。至少我现在明白了所谓的views都是基于这个subrange来转化的,而这个subrange的要求还真的很复杂,其中sentinel是一个相当复杂的东西,我记得range的作者曾经提到过他的演示的calendar的程序的问答的时候提到sentinel不应该要求和begin iterator一样。这个很深奥的,因为无限的range怎么实现我一点也不敢去想。
如果你明确要求subrange的move ctor的参数是lvalue reference,那么何必要定义个move ctor ?为什么不直接delete掉呢?所以这里不是允许你传入rvalue reference,必须是lvalue reference那么这里的&&其实是universal reference的意思,也就是说我不能看到这个&&的参数类型就以为函数允许你传入rvalue。不过这个确实有些逻辑上的困难。
一月十一日 等待变化等待机会
__attribute__ ((__symver__ ("foo@VERS_1"))) int foo_v1 (void){}
这里的VERS_1和实际的代码怎么联系呢?
objdump -p libstdc++.so有两个部分是我感兴趣的, 一个是.gnu.version_d This section holds the version symbol definitions, a table of ElfN_Verdef structures. This section is of type SHT_GNU_verdef. The attribute type used is SHF_ALLOC.而elf的program header的另一部分是这个
.gnu.version_r This section holds the version symbol needed elements, a table of ElfN_Verneed structures. This section is of type SHT_GNU_versym. The attribute type used is SHF_ALLOC.那么这个在编译过程是怎么做的呢?找到了原始的Makefile里引用一个版本定义的脚本“libstdc++-symbols.ver”这个脚本定义了复杂的类似于regex的形式,而在Makefile里用到了一个linker的命令:-Wl,--version-script=libstdc++-symbols.ver 从libstdc++-symbols.ver的复杂程度猜想不大可能是手工打造的,果然在源代码里是没有这个文件的,它是自动产生的。搜索makefile的配置确实很复杂,我放弃了,总之这个不是一个普通的自然的过程,需要配合其他的版本文件比如glibcxx的版本等等。
__attribute__ ((__symver__ ("sayhello@VERS_1"))) int sayhello(){return 42;}
结果这个编译命令g++ -fPIC -shared lib.cpp -o libtest.so报出警告我的attribute无效,当然实际的DSO自然不会有version这个部分。查看linker的文档是很痛苦的,很难懂。更新我自己的本地版本吧。libc++ is not 100% complete on GNU/Linux, and there's no real advantage to using it when libstdc++ is more complete. Also, if you want to link to any other libraries written in C++ they will almost certainly have been built with libstdc++ so you'll need to link with that too to use them.难道只有mac os才会有人要用它吗?查看官方网页目前c++14是完全支持的,c++17还在进行中。于此对应目前gcc/libstdc++对于c++17的支持是"almost full support"我花了一点时间比较两者对于c++各个标准的实现情况似乎差距不是那么的大,对于以上说法里其他库链接的是libstdc++而你必须再次链接我觉得可能是最大的原因。我一开始想libcxx有包含所有的symbol不就行了吗?转念一想不行因为链接DSO是写在elf里的无法改变,这个不是symbol级别的问题。所以,作为llvm的封闭系统苹果最喜欢这么另搞一套让你不兼容了。苹果是统一大环境的最大的公敌!
一月十二日 等待变化等待机会
ifstream in(__FILE__);
string str(istream_iterator<char>(in), istream_iterator<char>());
istream_iterator<char>(in)被解读成了什么?in被当作了istream_iterator的变量,这个在str整个被编译器当作函数之后它的型参这种临时变量是不会被编译器计较的,因为我们没有开放-Wshadow-compatible-local的警告,对于参数的重复声明的警告是不会有的。
string str((istream_iterator<char>(in)), istream_iterator<char>());
string str(istream_iterator<char>{in}, istream_iterator<char>());
#line 23 "cfns.gperf"
看来这个是一个固定log输出的一个好办法。
一月十三日 等待变化等待机会
The view concept specifies the requirements of a range type that has constant time copy, move, and assignment operations (e.g. a pair of iterators, or a generator Range that creates its elements on-demand. Notably, the standard library containers are ranges, but not views)这段话的信息量很多的,view是一个range的特殊形式要求constant time的copy/move/assignment,这个实现起来有两个途径,或者是用一对iterator或者是create on demand,或者lazy的方式创建。相比之下range只有很简单的要求,就是支持begin/end操作就可以了。那么view的实现是否仅仅是继承自view_interface就能自动实现吗?我以为不然,这个取决于两种途径,如果是两个iterator的形式,自然的就是满足了constant time的copy/move/assignment。但是如果是一个什么generator的形式呢?这个我还没有看到例子,不敢说怎么实现。因为大部分的view都是用range的begin/end这两个iterator。所以成本很低的就实现了。注意到view_interface要实现这么些个方法我一开始没有找到这个view_interface在cppreference的链接。
一月十四日 等待变化等待机会
一月十五日 等待变化等待机会
A name (identifier) consists of a sequence of letters and digits. The first character must be a letter. The underscore character,_, is considered a letter.至此我才明白我又闹了一个笑话,这个根本就不是什么c++17的新feature,这个是从大师定义c/c++语言的第一天就存在的!这个让我联想起在boost的lambda广泛的使用underscore的场景,这个压根儿就是一个一直存在的现象,因为_的独一无二的命名特性,它可以作为一个理想的局部变量的命名,因为每个人都会担心自己的变量名被人重复使用于是任何正常的程序员都不会在广大范围内命名自己的变量名为_,因为太容易重复了,但是并不等于你不可以!这就是我惊讶莫名的原因,这个叫做少见多怪!所以我现在才理解为什么有上述论文希望禁止它作为变量名,也才明白为什么那篇论文没有被接受,因为对于任何改变_的地位特性的做法可能都是某种灾难,因为谁知道有多少代码依赖于它?
reinterpret_cast<long long>(std::addressof(ary))+4*sizeof(std::ptrdiff_t)一月十六日 等待变化等待机会
template<T> struct add_lvalue_reference<void>{using type=void;};,这里你是不能再使用T了,为什么呢?因为speicialization是使用了实际类型void,你没有可能去做适配了,我使用适配这个词因为我也不知道要怎么说明。总之编译器报错说是用substitution的时候出错。这里还有一个小小的疑惑就是对于const volatile void如果我换成volatile const void,或者void const volatile等等会怎么样呢?事实上是编译器会把他们都归结为一个顺序,你不需要为了不同顺序再去speicialization否则真的就是噩梦了。
template<class T>struct add_value_reference<T, void_t<T&>>{using type=T&;};里的class T总是吃不准什么时候算是speicialization。看到这里我都快吐了,而就算写出来结果是不是我所期待的呢?这个debug的结果让我又吃了一惊。究竟模板参数是怎么替换的呢?
一月十七日 等待变化等待机会
一月二十日 等待变化等待机会
| prefix letter | type | size of character | remark |
|---|---|---|---|
| L | Wide string literal. | 4 | "...n code units of the execution wide encoding"这个是不是说不同的code point有不同的wide encoding?也就是说size是不确定的? |
| u8 | UTF-8 encoded string literal. | 1 | 其实和char没有区别,但是类型不同强制要求你去针对性的处理? |
| u | UTF-16 encoded string literal. | 2 | 是否有人真的使用它呢?我对于它的原理还是不清楚 |
| U | UTF-32 encoded string literal. | 4 | 同上 |
| R | Raw string literal | 1? | 它实际上可以和以上组合,所以它的长度依赖于以上的类型,当然默认是char吧 |
inline constexpr __copy_fn copy{};普通的parser对于一个函数首先去找我们熟悉的c函数,对于这种functor可能是放在比较靠后吧? 这个可能是一个难题,除非gtags里的parser能够与时俱进的话,我猜想这个比较困难,比如eclipse for c++还不认识consteval这个关键字,vscode也是一样,这个是太新的语法了。
一月二十一日 等待变化等待机会
一月二十二日 等待变化等待机会
In this case, there is a better option than making the plus lazy. We can use a greedy plus and a negated character class. The reason why this is better is because of the backtracking. When using the lazy plus, the engine has to backtrack for each character that it is trying to match.
 这个自动机要好好看看
这个自动机要好好看看Backtracking Control Verbs
This library has partial support for Perl's backtracking control verbs, in particular (*MARK) is not supported. There may also be detail differences in behaviour between this library and Perl, not least because Perl's behaviour is rather under-documented and often somewhat random in how it behaves in practice. The verbs supported are:
(*PRUNE)Has no effect unless backtracked onto, in which case all the backtracking information prior to this point is discarded.(*SKIP)Behaves the same as(*PRUNE)except that it is assumed that no match can possibly occur prior to the current point in the string being searched. This can be used to optimize searches by skipping over chunks of text that have already been determined can not form a match.(*THEN)Has no effect unless backtracked onto, in which case all subsequent alternatives in a group of alternations are discarded.(*COMMIT)Has no effect unless backtracked onto, in which case all subsequent matching/searching attempts are abandoned.(*FAIL)Causes the match to fail unconditionally at this point, can be used to force the engine to backtrack.(*ACCEPT)Causes the pattern to be considered matched at the current point. Any half-open sub-expressions are closed at the current point.
Lexing a source file is a good job for regexes. But for such a task, let's use a better regex engine than std::regex. Let's use PCRE (or boost::regex) at first. At the end of this post, I'll show what you can do with a less feature-packed engine.
We only need to do partial lexing, ignoring all unrecognized tokens that won't affect string literals. What we need to handle is:
We'll be using the extended (x) option, which ignores whitespace in the pattern.
Here's what [lex.comment] says:
The characters
/*start a comment, which terminates with the characters*/. These comments do not nest. The characters//start a comment, which terminates immediately before the next new-line character. If there is a form-feed or a vertical-tab character in such a comment, only white-space characters shall appear between it and the new-line that terminates the comment; no diagnostic is required. [ Note: The comment characters//,/*, and*/have no special meaning within a//comment and are treated just like other characters. Similarly, the comment characters//and/*have no special meaning within a/*comment. — end note ]
# singleline comment
// .* (*SKIP)(*FAIL)
# multiline comment
| /\* (?s: .*? ) \*/ (*SKIP)(*FAIL)
Easy peasy. If you match anything there, just (*SKIP)(*FAIL) - meaning that you throw away the match. The (?s: .*? ) applies the s (singleline) modifier to the . metacharacter, meaning it's allowed to match newlines.
Here's the grammar from [lex.ccon]:
character-literal: encoding-prefix(opt) ’ c-char-sequence ’ encoding-prefix: one of u8 u U L c-char-sequence: c-char c-char-sequence c-char c-char: any member of the source character set except the single-quote ’, backslash \, or new-line character escape-sequence universal-character-name escape-sequence: simple-escape-sequence octal-escape-sequence hexadecimal-escape-sequence simple-escape-sequence: one of \’ \" \? \\ \a \b \f \n \r \t \v octal-escape-sequence: \ octal-digit \ octal-digit octal-digit \ octal-digit octal-digit octal-digit hexadecimal-escape-sequence: \x hexadecimal-digit hexadecimal-escape-sequence hexadecimal-digit
Let's define a few things first, which we'll need later on:
(?(DEFINE)
(?<prefix> (?:u8?|U|L)? )
(?<escape> \\ (?:
['"?\\abfnrtv] # simple escape
| [0-7]{1,3} # octal escape
| x [0-9a-fA-F]{1,2} # hex escape
| u [0-9a-fA-F]{4} # universal character name
| U [0-9a-fA-F]{8} # universal character name
))
)
prefix is defined as an optional u8, u, U or Lescape is defined as per the standard, except that I've merged universal-character-name into it for the sake of simplicityOnce we have these, a character literal is pretty simple:
(?&prefix) ' (?> (?&escape) | [^'\\\r\n]+ )+ ' (*SKIP)(*FAIL)
We throw it away with (*SKIP)(*FAIL)
They're defined in almost the same way as character literals. Here's a part of [lex.string]:
string-literal: encoding-prefix(opt) " s-char-sequence(opt) " encoding-prefix(opt) R raw-string s-char-sequence: s-char s-char-sequence s-char s-char: any member of the source character set except the double-quote ", backslash \, or new-line character escape-sequence universal-character-name
This will mirror the character literals:
(?&prefix) " (?> (?&escape) | [^"\\\r\n]+ )* "
The differences are:
* instead of +)Here's the raw string part:
raw-string: " d-char-sequence(opt) ( r-char-sequence(opt) ) d-char-sequence(opt) " r-char-sequence: r-char r-char-sequence r-char r-char: any member of the source character set, except a right parenthesis ) followed by the initial d-char-sequence (which may be empty) followed by a double quote ". d-char-sequence: d-char d-char-sequence d-char d-char: any member of the basic source character set except: space, the left parenthesis (, the right parenthesis ), the backslash \, and the control characters representing horizontal tab, vertical tab, form feed, and newline.
The regex for this is:
(?&prefix) R " (?<delimiter>[^ ()\\\t\x0B\r\n]*) \( (?s:.*?) \) \k<delimiter> "
[^ ()\\\t\x0B\r\n]* is the set of characters that are allowed in delimiters (d-char)\k<delimiter> refers to the previously matched delimiterThe full pattern is:
(?(DEFINE)
(?<prefix> (?:u8?|U|L)? )
(?<escape> \\ (?:
['"?\\abfnrtv] # simple escape
| [0-7]{1,3} # octal escape
| x [0-9a-fA-F]{1,2} # hex escape
| u [0-9a-fA-F]{4} # universal character name
| U [0-9a-fA-F]{8} # universal character name
))
)
# singleline comment
// .* (*SKIP)(*FAIL)
# multiline comment
| /\* (?s: .*? ) \*/ (*SKIP)(*FAIL)
# character literal
| (?&prefix) ' (?> (?&escape) | [^'\\\r\n]+ )+ ' (*SKIP)(*FAIL)
# standard string
| (?&prefix) " (?> (?&escape) | [^"\\\r\n]+ )* "
# raw string
| (?&prefix) R " (?<delimiter>[^ ()\\\t\x0B\r\n]*) \( (?s:.*?) \) \k<delimiter> "
See the demo here.
boost::regexHere's a simple demo program using boost::regex:
#include <string>
#include <iostream>
#include <boost/regex.hpp>
static void test()
{
boost::regex re(R"regex(
(?(DEFINE)
(?<prefix> (?:u8?|U|L) )
(?<escape> \\ (?:
['"?\\abfnrtv] # simple escape
| [0-7]{1,3} # octal escape
| x [0-9a-fA-F]{1,2} # hex escape
| u [0-9a-fA-F]{4} # universal character name
| U [0-9a-fA-F]{8} # universal character name
))
)
# singleline comment
// .* (*SKIP)(*FAIL)
# multiline comment
| /\* (?s: .*? ) \*/ (*SKIP)(*FAIL)
# character literal
| (?&prefix)? ' (?> (?&escape) | [^'\\\r\n]+ )+ ' (*SKIP)(*FAIL)
# standard string
| (?&prefix)? " (?> (?&escape) | [^"\\\r\n]+ )* "
# raw string
| (?&prefix)? R " (?<delimiter>[^ ()\\\t\x0B\r\n]*) \( (?s:.*?) \) \k<delimiter> "
)regex", boost::regex::perl | boost::regex::no_mod_s | boost::regex::mod_x | boost::regex::optimize);
std::string subject(R"subject(
std::cout << L"hello" << " world";
std::cout << "He said: \"bananas\"" << "...";
std::cout << "";
std::cout << "\x12\23\x34";
std::cout << u8R"hello(this"is\a\""""single\\(valid)"
raw string literal)hello";
"" // empty string
'"' // character literal
// this is "a string literal" in a comment
/* this is
"also inside"
//a comment */
// and this /*
"is not in a comment"
// */
"this is a /* string */ with nested // comments"
)subject");
std::cout << boost::regex_replace(subject, re, "String\\($&\\)", boost::format_all) << std::endl;
}
int main(int argc, char **argv)
{
try
{
test();
}
catch(std::exception ex)
{
std::cerr << ex.what() << std::endl;
}
return 0;
}
(I left syntax highlighting disabled because it goes nuts on this code)
For some reason, I had to take the ? quantifier out of prefix (change (?<prefix> (?:u8?|U|L)? ) to (?<prefix> (?:u8?|U|L) ) and (?&prefix) to (?&prefix)?) to make the pattern work. I believe it's a bug in boost::regex, as both PCRE and Perl work just fine with the original pattern.
Note that while this pattern technically uses recursion, it never nests recursive calls. Recursion could be avoided by inlining the relevant reusable parts into the main pattern.
A couple of other constructs can be avoided at the price of reduced performance. We can safely replace the atomic groups (?>...) with normal groups (?:...) if we don't nest quantifiers in order to avoid catastrophic backtracking.
We can also avoid (*SKIP)(*FAIL) if we add one line of logic into the replacement function: All the alternatives to skip are grouped in a capturing group. If the capturing group matched, just ignore the match. If not, then it's a string literal.
All of this means we can implement this in JavaScript, which has one of the simplest regex engines you can find, at the price of breaking the DRY rule and making the pattern illegible. The regex becomes this monstrosity once converted:
(\/\/.*|\/\*[\s\S]*?\*\/|(?:u8?|U|L)?'(?:\\(?:['"?\\abfnrtv]|[0-7]{1,3}|x[0-9a-fA-F]{1,2}|u[0-9a-fA-F]{4}|U[0-9a-fA-F]{8})|[^'\\\r\n])+')|(?:u8?|U|L)?"(?:\\(?:['"?\\abfnrtv]|[0-7]{1,3}|x[0-9a-fA-F]{1,2}|u[0-9a-fA-F]{4}|U[0-9a-fA-F]{8})|[^"\\\r\n])*"|(?:u8?|U|L)?R"([^ ()\\\t\x0B\r\n]*)\([\s\S]*?\)\2"
And here's an interactive demo you can play with:
function run() {
var re = /(\/\/.*|\/\*[\s\S]*?\*\/|(?:u8?|U|L)?'(?:\\(?:['"?\\abfnrtv]|[0-7]{1,3}|x[0-9a-fA-F]{1,2}|u[0-9a-fA-F]{4}|U[0-9a-fA-F]{8})|[^'\\\r\n])+')|(?:u8?|U|L)?"(?:\\(?:['"?\\abfnrtv]|[0-7]{1,3}|x[0-9a-fA-F]{1,2}|u[0-9a-fA-F]{4}|U[0-9a-fA-F]{8})|[^"\\\r\n])*"|(?:u8?|U|L)?R"([^ ()\\\t\x0B\r\n]*)\([\s\S]*?\)\2"/g;
var input = document.getElementById("input").value;
var output = input.replace(re, function(m, ignore) {
return ignore ? m : "String(" + m + ")";
});
document.getElementById("output").innerText = output;
}
document.getElementById("input").addEventListener("input", run);
run();<h2>Input:</h2>
<textarea id="input" style="width: 100%; height: 50px;">
std::cout << L"hello" << " world";
std::cout << "He said: \"bananas\"" << "...";
std::cout << "";
std::cout << "\x12\23\x34";
std::cout << u8R"hello(this"is\a\""""single\\(valid)"
raw string literal)hello";
"" // empty string
'"' // character literal
// this is "a string literal" in a comment
/* this is
"also inside"
//a comment */
// and this /*
"is not in a comment"
// */
"this is a /* string */ with nested // comments"
</textarea>
<h2>Output:</h2>
<pre id="output"></pre>prefix(optional) R"delimiter(raw_characters)delimiter"这里的prefix是其中任意一个L, u8, u, U一月二十三日 等待变化等待机会
(?(DEFINE)never-exectuted-pattern) Defines a block of code that is never executed and matches no characters: this is usually used to define one or more named sub-expressions which are referred to from elsewhere in the pattern.所以,很明显的它是一个定义不要执行,不要执行,不要执行!
You can create a named subexpression using:所以,这个是一个named定义。(?<NAME>expression)
所以,它是一个无名的定义,如果我们不需要index它的话。Non-marking groups
(?:pattern) lexically groups pattern, without generating an additional sub-expression.
// .* (*SKIP)(*FAIL)
翻译成人话就是说SKIP制止了backtracking,这个和lazy有什么不同呢?FAIL也是制止了backtrack,那么他们有什么不同呢?
- (*PRUNE) Has no effect unless backtracked onto, in which case all the backtracking information prior to this point is discarded.
- (*SKIP) Behaves the same as (*PRUNE) except that it is assumed that no match can possibly occur prior to the current point in the string being searched. This can be used to optimize searches by skipping over chunks of text that have already been determined can not form a match.
- (*FAIL) Causes the match to fail unconditionally at this point, can be used to force the engine to backtrack.
| /\* (?s: .*? ) \*/ (*SKIP)(*FAIL)
翻译成人话就是说要做改变,改什么呢?Modifiers
(?imsx-imsx ... )alters which of the perl modifiers are in effect within the pattern, changes take effect from the point that the block is first seen and extend to any enclosing). Letters before a '-' turn that perl modifier on, letters afterward, turn it off.
(?imsx-imsx:pattern)applies the specified modifiers to pattern only.
Wildcard
The single character '.' when used outside of a character set will match any single character except:
- The NULL character when the flag
match_not_dot_nullis passed to the matching algorithms.- The newline character when the flag
match_not_dot_newlineis passed to the matching algorithms.
\s stands for “whitespace character”. Again, which characters this actually includes, depends on the regex flavor. In all flavors discussed in this tutorial, it includes [ \t\r\n\f]. That is: \s matches a space, a tab, a carriage return, a line feed, or a form feed. Most flavors also include the vertical tab, with Perl (prior to version 5.18) and PCRE (prior to version 8.34) being notable exceptions.
/\* (?s: .*?) \*/ (*SKIP)(*FAIL)究竟是什么意思?关键在于理解?s:是什么意思!single line modifier引出了无穷多的内容!
- makes the regex case insensitive.
- makes the regex case sensitive. Only supported by Tcl.
- turn on free-spacing mode.
- turn off free-spacing mode. Only supported by Tcl.
- turn on free-spacing mode, also in character classes. Supported by Perl 5.26 and PCRE2 10.30.
- for “single line mode” makes the dot match all characters, including line breaks. Not supported by Ruby or JavaScript. In Tcl, also makes the caret and dollar match at the start and end of the string only.
- for “multi-line mode” makes the caret and dollar match at the start and end of each line in the subject string. In Ruby, makes the dot match all characters, without affecting the caret and dollar which always match at the start and end of each line in Ruby. In Tcl, also prevents the dot from matching line breaks.
- in Tcl makes the caret and dollar match at the start and the end of each line, and makes the dot match line breaks.
- in Tcl makes the caret and dollar match only at the start and the end of the subject string, and prevents the dot from matching line breaks.
- turns all unnamed groups into non-capturing groups. Only supported by .NET, XRegExp, and the JGsoft flavor. In Tcl, is the same as .
- allows duplicate group names. Only supported by PCRE and languages that use it such as Delphi, PHP and R.
- turns on “ungreedy mode”, which switches the syntax for greedy and lazy quantifiers. So a* is lazy and a*? is greedy. Only supported by PCRE and languages that use it. It’s use is strongly discouraged because it confuses the meaning of the standard quantifier syntax.
- corresponds with UNIX_LINES in Java, which makes the dot, caret, and dollar treat only the newline character \n as a line break, instead of recognizing all line break characters from the Unicode standard. Whether they match or don’t match (at) line breaks depends on and .
- makes Tcl interpret the regex as a POSIX BRE.
- makes Tcl interpret the regex as a POSIX ERE.
- makes Tcl interpret the regex as a literal string (minus the (?q) characters).
- makes escaping letters with a backslash an error if that combination is not a valid regex token. Only supported by PCRE and languages that use it.
| /\* (?s: .*? ) \*/ (*SKIP)(*FAIL)
Non greedy repeats
The normal repeat operators are "greedy", that is to say they will consume as much input as possible. There are non-greedy versions available that will consume as little input as possible while still producing a match.
- *? Matches the previous atom zero or more times, while consuming as little input as possible.
- +? Matches the previous atom one or more times, while consuming as little input as possible.
- ?? Matches the previous atom zero or one times, while consuming as little input as possible.
- {n,}? Matches the previous atom n or more times, while consuming as little input as possible.
- {n,m}? Matches the previous atom between n and m times, while consuming as little input as possible.
| (?&prefix)? ' (?> (?&escape) | [^'\\\r\n]+ )+ ' (*SKIP)(*FAIL)
也就是说 (?&prefix)代表“recurses to named sub-expression prefix”?这个是什么意思呢?它后面的?当然是non-greedy,可是什么叫做递归到它为止?是不是就是说这个定义不要再翻译了,像很多脚本语言定义可以再定义,变量可以再定义???Recursive Expressions
(?N) (?-N) (?+N) (?R) (?0) (?&NAME)
- (?R) and (?0) recurse to the start of the entire pattern.
- (?N) executes sub-expression N recursively, for example (?2) will recurse to sub-expression 2.
- (?-N) and (?+N) are relative recursions, so for example (?-1) recurses to the last sub-expression to be declared, and (?+1) recurses to the next sub-expression to be declared.
- (?&NAME) recurses to named sub-expression NAME.
这里的简单粗暴比对不允许backtrack和末尾添加了(*SKIP)(*FAIL)是什么关系?似乎作者反反复复的不遗余力的防止backtracking,已经到了无所不用其极的地步了,这个只有专家和对于效率极其敏感的高手才如此行事。 看到这里我才对于作者定义的escape这个定义有了一些理解,原来它是一个c++的escape\和所有literal可能的组合,这个多么的浅显我一开始却不理解。Independent sub-expressions
(?>pattern) pattern is matched independently of the surrounding patterns, the expression will never backtrack into pattern. Independent sub-expressions are typically used to improve performance; only the best possible match for pattern will be considered, if this doesn't allow the expression as a whole to match then no match is found at all.
(?&prefix)? R " (?<delimiter>[^ ()\\\t\x0B\r\n]*) \( (?s:.*?) \) \k<delimiter> "
这个\k是什么意思?
所以这里的\k<delimiter>就是reference之前定义的delimiter。 而这里要提醒一下\x0B是所谓的vertical tab在c/c++里几乎不会遇到,但是它只不过是delimiter的定义不能包含而已,这个似乎是c++ standard定义的吧?Back references
- An escape character followed by a digit n, where n is in the range 1-9, matches the same string that was matched by sub-expression n. For example the expression: ^(a*)[^a]*\1$
You can also use the \g escape for the same function, for example:
Escape
Meaning
\g1Match whatever matched sub-expression 1
\g{1}Match whatever matched sub-expression 1: this form allows for safer parsing of the expression in cases like
\g{1}2or for indexes higher than 9 as in\g{1234}
\g-1Match whatever matched the last opened sub-expression
\g{-2}Match whatever matched the last but one opened sub-expression
\g{one}Match whatever matched the sub-expression named "one"
- Finally the \k escape can be used to refer to named subexpressions, for example \k<two> will match whatever matched the subexpression named "two".
一月二十四日 等待变化等待机会
\\begin\{bnf\}(?s:.+?)\\end\{bnf\}
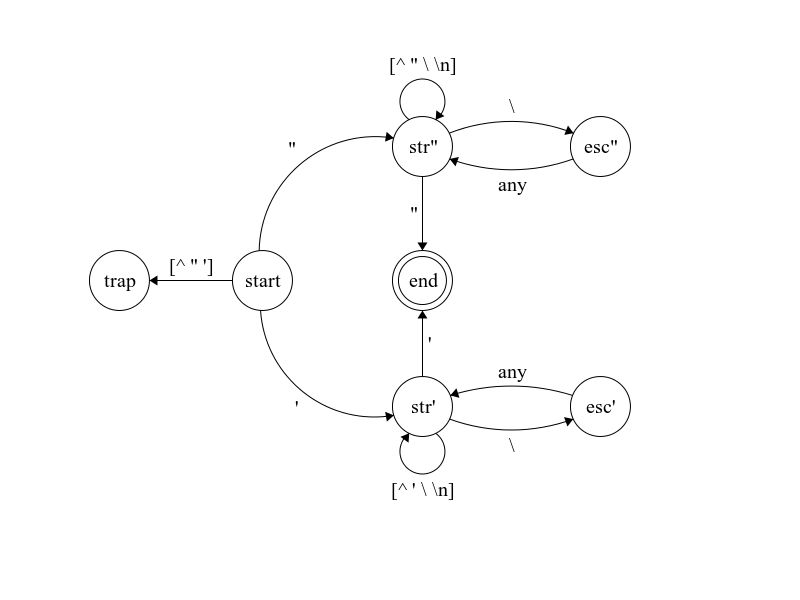
是否有sub_match,我自然而然的认为有。难道这个()不是可以作为sub_match吗?结果不是的,我必须再加一对((?s:.+?))才行。这个真的是让人无语。
一月二十五日 等待变化等待机会
Invalid back reference: specified capturing group does not exist. The error occurred while parsing the regular expression fragment: '(?:\w+)\w?>>>HERE>>>\1我随后发现了错误改造成了这个(?<name>\w+)\w?\1可是这个只能match最短的palindrom,比如我的输入是
this is a palindromordnilal andna结果只有
一月二十六日 等待变化等待机会
一月二十七日 等待变化等待机会
一月二十八日 等待变化等待机会
一月二十九日 等待变化等待机会
一月三十日 等待变化等待机会
The precedence of operators is not directly specified, but it can be derived from the syntax.这个是从何说起呢?难道从这个operator-or-punctuator庞然大物里能够推理出来吗? 这里有一些有趣的操作符我是从来没有见到过的,比如<:,这个是
孟子曰:“爱人不亲,反其仁;治人不治,反其智;礼人不答,反其敬——行有不得者皆反求诸己,其身正而天下归之。《诗》云:‘永言配命,自求多福。’”孟子的话真的好感人啊,漂亮国的领导人真的应该好好学习一下。
“仁者如射:射者正己而后发;发而不中,不怨胜己者,反求诸己而已矣。”我觉得这个应该反省,对于.tex这么一个简单的文本文件,我不求诸己反而搜寻无数的不着四六的小程序来参考是注定失败的。也许根本就是一个简单的小问题。我根本就不知道这个bnf语法是用什么工具生成的,仅仅有个别的符号被使用了latex的escape方法我去掉它们不就行了吗?值得这么大惊小怪的吗?
“其身正,不令而行;其身不正,虽令不从。”(《论语·子路》)
“爱人者,人恒爱之;敬人者,人恒敬之。”“人必自侮,而后人侮之;家必自毁,而后人毁之。”中国古人对于做人的道理讲的实在是太透彻了,这真的是世界人民的财富啊。
“各自责,天清地宁;各相责,天翻地覆。”
一月三十一日 等待变化等待机会
二月一日 等待变化等待机会
Also, unlike standard C, trigraphs have no special meaning in Bison character literals, nor is backslash-newline allowed.这句话让我感到惶恐,为什么我不知道标准C语言有支持trigraph呢?对于此我是闻所未闻啊。 对于这个大侠的引用我觉得有必要保存一下
我赶快搜了一下,还好在我的语法输入文件里没有这些??前缀。总结一下我阅读大侠们的解释就是c/c++编译器应当会把这一类的“三元符”替换吧? 实践的是检验真理的唯一标准 当我编译printf( "What??!\n" );的时候gcc报出了警告:三元符 ??! 被忽略,请使用 -trigraphs 来启用 [-Wtrigraphs]Before any other processing takes place, each occurrence of one of the following sequences of three characters (“trigraph sequences”) is replaced by the single character indicated in Table 1.
---------------------------------------------------------------------------- | trigraph | replacement | trigraph | replacement | trigraph | replacement | ---------------------------------------------------------------------------- | ??= | # | ??( | [ | ??< | { | | ??/ | \ | ??) | ] | ??> | } | | ??’ | ˆ | ??! | | | ??- | ˜ | ----------------------------------------------------------------------------
二月二日 等待变化等待机会
二月三日 等待变化等待机会
| alternative token | primary token |
|---|---|
| <% | { |
| %> | } |
| <: | [ |
| :> | ] |
| %: | # |
| %:%: | ## |
这段时间我最重要的“发现”就是一个基本的疑惑的解答:为什么标准没有给出c++语法的[AE]?BNF的形式?为什么我满世界搜索找不到任何人的尝试?因为不可能!
Below is my (current) favorite demonstration of why parsing C++ is (probably) Turing-complete, since it shows a program which is syntactically correct if and only if a given integer is prime.
So I assert that C++ is neither context-free nor context-sensitive.
If you allow arbitrary symbol sequences on both sides of any production, you produce an Type-0 grammar ("unrestricted") in the Chomsky hierarchy, which is more powerful than a context-sensitive grammar; unrestricted grammars are Turing-complete. A context-sensitive (Type-1) grammar allows multiple symbols of context on the left hand side of a production, but the same context must appear on the right hand side of the production (hence the name "context-sensitive"). [1] Context-sensitive grammars are equivalent to linear-bounded Turing machines.
In the example program, the prime computation could be performed by a linear-bounded Turing machine, so it does not quite prove Turing equivalence, but the important part is that the parser needs to perform the computation in order to perform syntactic analysis. It could have been any computation expressible as a template instantiation and there is every reason to believe that C++ template instantiation is Turing-complete. See, for example, Todd L. Veldhuizen's 2003 paper.
Regardless, C++ can be parsed by a computer, so it could certainly be parsed by a Turing machine. Consequently, an unrestricted grammar could recognize it. Actually writing such a grammar would be impractical, which is why the standard doesn't try to do so. (See below.)
The issue with "ambiguity" of certain expressions is mostly a red herring. To start with, ambiguity is a feature of a particular grammar, not a language. Even if a language can be proven to have no unambiguous grammars, if it can be recognized by a context-free grammar, it's context-free. Similarly, if it cannot be recognized by a context-free grammar but it can be recognized by a context-sensitive grammar, it's context-sensitive. Ambiguity is not relevant.
But in any event, like line 21 (i.e.
auto b = foo<IsPrime<234799>>::typen<1>();) in the program below, the expressions are not ambiguous at all; they are simply parsed differently depending on context. In the simplest expression of the issue, the syntactic category of certain identifiers is dependent on how they have been declared (types and functions, for example), which means that the formal language would have to recognize the fact that two arbitrary-length strings in the same program are identical (declaration and use). This can be modelled by the "copy" grammar, which is the grammar which recognizes two consecutive exact copies of the same word. It's easy to prove with the pumping lemma that this language is not context-free. A context-sensitive grammar for this language is possible, and a Type-0 grammar is provided in the answer to this question: https://math.stackexchange.com/questions/163830/context-sensitive-grammar-for-the-copy-language .If one were to attempt to write a context-sensitive (or unrestricted) grammar to parse C++, it would quite possibly fill the universe with scribblings. Writing a Turing machine to parse C++ would be an equally impossible undertaking. Even writing a C++ program is difficult, and as far as I know none have been proven correct. This is why the standard does not attempt to provide a complete formal grammar, and why it chooses to write some of the parsing rules in technical English.
What looks like a formal grammar in the C++ standard is not the complete formal definition of the syntax of the C++ language. It's not even the complete formal definition of the language after preprocessing, which might be easier to formalize. (That wouldn't be the language, though: the C++ language as defined by the standard includes the preprocessor, and the operation of the preprocessor is described algorithmically since it would be extremely hard to describe in any grammatical formalism. It is in that section of the standard where lexical decomposition is described, including the rules where it must be applied more than once.)
The various grammars (two overlapping grammars for lexical analysis, one which takes place before preprocessing and the other, if necessary, afterwards, plus the "syntactic" grammar) are collected in Appendix A, with this important note (emphasis added):
This summary of C++ syntax is intended to be an aid to comprehension. It is not an exact statement of the language. In particular, the grammar described here accepts a superset of valid C++ constructs. Disambiguation rules (6.8, 7.1, 10.2) must be applied to distinguish expressions from declarations. Further, access control, ambiguity, and type rules must be used to weed out syntactically valid but meaningless constructs.
Finally, here's the promised program. Line 21 is syntactically correct if and only if the N in
IsPrime<N>is prime. Otherwise,typenis an integer, not a template, sotypen<1>()is parsed as(typen<1)>()which is syntactically incorrect because()is not a syntactically valid expression.template<bool V> struct answer { answer(int) {} bool operator()(){return V;}}; template<bool no, bool yes, int f, int p> struct IsPrimeHelper : IsPrimeHelper<p % f == 0, f * f >= p, f + 2, p> {}; template<bool yes, int f, int p> struct IsPrimeHelper<true, yes, f, p> { using type = answer<false>; }; template<int f, int p> struct IsPrimeHelper<false, true, f, p> { using type = answer<true>; }; template<int I> using IsPrime = typename IsPrimeHelper<!(I&1), false, 3, I>::type; template<int I> struct X { static const int i = I; int a[i]; }; template<typename A> struct foo; template<>struct foo<answer<true>>{ template<int I> using typen = X<I>; }; template<> struct foo<answer<false>>{ static const int typen = 0; }; int main() { auto b = foo<IsPrime<234799>>::typen<1>(); // Syntax error if not prime return 0; }
[1] To put it more technically, every production in a context-sensitive grammar must be of the form:
αAβ → αγβwhere
Ais a non-terminal andα,βare possibly empty sequences of grammar symbols, andγis a non-empty sequence. (Grammar symbols may be either terminals or non-terminals).This can be read as
A → γonly in the context[α, β]. In a context-free (Type 2) grammar,αandβmust be empty.It turns out that you can also restrict grammars with the "monotonic" restriction, where every production must be of the form:
α → βwhere|α| ≥ |β| > 0(|α|means "the length ofα")It's possible to prove that the set of languages recognized by monotonic grammars is exactly the same as the set of languages recognized by context-sensitive grammars, and it's often the case that it's easier to base proofs on monotonic grammars. Consequently, it's pretty common to see "context-sensitive" used as though it meant "monotonic".
二月四日 等待变化等待机会
二月五日 等待变化等待机会
[Software]Design pattern is a repeatable, commonly recognized and understood solution to a design problem commonly occurring in software engineering.这说明什么?
- Design problem
- Common occurring
- Widely accepted solution
- Known advantages and trade-offs
二月六日 等待变化等待机会
The dragon book [Aho86] recognises that the boundaries between lexical, syntactic and semantic analysis are not clear cut.
Traditional C++ approaches seek a correct high resolution parse. As a result, the boundary between syntactic and semantic analysis has to be shifted to exploit semantic information during syntactic analysis by the parser and to leak semantic information through to the lexer. Use of semantic information during syntactic analysis requires very tight coupling to ensure that scope context is honoured and that changes of name visibility in mid-statement are correct.
bin/bash^M: 坏的解释器: 没有那个文件或目录
由于在Windows下换行是\n\r,在Linux下打开多了\r,所以需要删除。删除命令 :sed -i 's/\r$//' filename
二月七日 等待变化等待机会
二月九日 等待变化等待机会
回过头来看在preprocessing的部分的说明module-import-declaration: import-keyword module-name attribute-specifier-seq opt ; import-keyword module-partition attribute-specifier-seq opt; import-keyword header-name attribute-specifier-seq opt ;
这里说到这些xxx-keyword是怎么来的,可是我感到很难理解,这个是说preprocessor怎么产生的token要被parser来使用吗?感觉类似flex定义的token被bison使用一样。那么这种语法我要怎么定义呢?也放在flex里?pp-import: exportopt import header-name pp-tokensopt ; new-line exportopt import header-name-tokens pp-tokensopt ; new-line exportopt import pp-tokens ; new-line
我尝试理解就是import/export这些在preprocessor directive之后能够得以保存是归功于把它们重新定义为token就是说它们所跟随的是在preprossor里处理因为有包含头文件等等,但是也包含了类和函数,所以,这些import/export随后还必须在parser里分析语义不能像#include一样被去除掉?In all three forms of pp-import, the import and export (if it exists) preprocessing tokens are replaced by the import-keyword and export-keyword preprocessing tokens respectively.
[Note 1: This makes the line no longer a directive so it is not removed at the end of phase 4. — end note]
二月十日 等待变化等待机会
a b c d e f g h i j k l m n o p q r s t u v w x y z
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
0 1 2 3 4 5 6 7 8 9
_ { } [ ] # ( ) < > % : ; . ? * + - / ^ & | ~ ! = , \ " '
原来所谓的ISO/IEC 10646就是我们常说的 Universal Coded Character Set (UCS)\u hex-quad \U hex-quad hex-quad
这里让我不清楚GB18030是否在这个65536之内还是之外呢?The UCS has over 1.1 million possible code points available for use/allocation, but only the first 65,536, which is the Basic Multilingual Plane (BMP), had entered into common use before 2000. This situation began changing when the People's Republic of China (PRC) ruled in 2006 that all software sold in its jurisdiction would have to support GB 18030. This required software intended for sale in the PRC to move beyond the BMP.
UCS-2 thereby permits a binary representation of every code point in the BMP that represents a character. UCS-2 cannot represent code points outside the BMP.这里说的很明白就是UCS-4是真正能够解决所有的UCS定义的code point:
UCS-4 allows representation of each value as exactly four bytes (one 32-bit word). UCS-4 thereby permits a binary representation of every code point in the UCS, including those outside the BMP.我的疑问也许可以通过编码的比较事实上空洞的规定必须有具体的实现来承载,否则空谈code point让人无所适从,不如拿出干货让程序员明白具体的是什么。来回答,因为GB18030是中国标准,虽然兼容但不是相同,是有一些特殊的地方的。编码和标准是两个概念,任何一种标准都需要实现,可以简单的naive的直接用一个shorti nteger来实现UCS-2,也可以有很多其他编码比如UTF-8/16等等以及古老的其他编码方式。我觉得这个表有必要拷贝下来,因为它的信息量很大这个表里其实说的就很清楚了GB18030里把所有的英文字母数字标点符号又都重新定义了一遍,这个就是我天天打字最头疼的地方,有些时候看不清楚是汉字的标点还是ASCII的,在代码里有时候要费很大劲儿去除。
对于所谓的Seven-bit environments我不是很理解究竟指的是什么。 这里还有一个插曲,就是有人搞笑的提出所谓的Eight-bit environments
Code range (hexadecimal) UTF-8 UTF-16 UTF-32 UTF-EBCDIC GB 18030 000000 – 00007F 1 2 4 1 1 000080 – 00009F 2 2 for characters inherited from
GB 2312/GBK (e.g. most
Chinese characters) 4 for
everything else.0000A0 – 0003FF 2 000400 – 0007FF 3 000800 – 003FFF 3 004000 – 00FFFF 4 010000 – 03FFFF 4 4 4 040000 – 10FFFF 5
第一阶段就是编码的整理,可是怎么做我还是一头雾水,单单预处理的第一阶段就是这么的复杂啊。我的问题是我怎么知道是什么编码方式呢?应该说不可能也不需要知道不是我的责任去猜测或者尝试因为不可靠!,只有用户指定。
怎么实现标准里说的很明白An implementation may use any internal encoding, so long as an actual extended character encountered in the source file, and the same extended character expressed in the source file as a universal-character-name (e.g., using the \uXXXX notation), are handled equivalently except where this replacement is reverted ([lex.pptoken]) in a raw string literal.这里重点是我之前感到疑惑的raw string的处理,算法是revert所作的mapping。这个是实现的细节,也许这个是说起来最容易的。即便是如此简单的任务也让人感到头疼!标准提出这个算法是有原因的,因为你不在全部处理完毕之前很有可能是无法准确定位raw string的吧?总之最简单的也是最可靠的。可是有时候所谓的是看上去如此而已,你难道要记录你怎么处理raw string的吗?有没有可靠的revert的方式?
5.2 [lex.phases] paragraph 1, phase 2: a universal-character-name resulting from a line splice.我一开始看这个例子不明所以然,后来实际编译才看到玄机,比如这个字符串
const char* p = "\\
u0041";const char* p = "\\u0041";
这中间的玄机我一时还是有些模糊不清。
我即便不能深刻领会也能看出来三种方式都有隐患,没有完美的解决方案。这就是根源。
- Convert everything to UCNs in basic source characters as soon as possible, that is, in translation phase 1.
- Use native encodings where possible, UCNs otherwise.
- Convert everything to wide characters as soon as possible using an internal encoding that encompasses the entire source character set and all UCNs.
Implementations, as well as the specification in a language standard, can employ any of the three, but it must be impossible for a well-defined program to determine which model was actually employed by implementation. The implication of this “equivalence principle” is that any construct that would give different results under the different models must be classified as undefined behavior.现在总算是crystal clear了吧?真的很不容易,我看了一早上才看到第二步,总共有九步!
#define R "x" const char* s = R"y"; // ill-formed raw string, not "x" "y"这个例子会编译错误:error: invalid character ' ' in raw string delimiter这个错误让人摸不着头脑。因为如果按照下面把R"看作raw string的开始,那么就不应该做宏替换那么为什么会有空格字符的错误呢?比如作为raw string里的。现在我使用这个g++ -E -fpreprocessed给出了一样的错误,这个-fpreprocessed
Indicate to the preprocessor that the input file has already been preprocessed. This suppresses things like macro expansion,...所以结论是不存在宏替换了,但是为什么报错会提到这个空格字符呢?invalid character ' ' in raw string delimiter 比如这个d-char是不允许space的preprocessor应该在期待(作为休止符,所以我认为y会被当作d-char,但是...??? 值得注意的是我刚刚才意识到raw string的那个R和后面的"之间是不能有空格的,
If the next character begins a sequence of characters that could be the prefix and initial double quote of a raw string literal, such as R", the next preprocessing token shall be a raw string literal.所以在preprocessing的时候whitespace是很重要的分隔符。
朋友,你知道C语言的精髓是什么吗?
- Trust the programmer.
不要像java一样把程序员当小孩子,没有保姆!- Don't prevent the programmer from doing what needs to be done.
自由!自由!自由!重要的事情说三编!- Keep the language small and simple.
举重若轻,大巧不工。- Provide only one way to do an operation.
人无法做出正确的选择的原因是因为有选择。- Make it fast, even if it is not guaranteed to be portable.
C不是C++,不需要一致性与移植性。
二月十一日 等待变化等待机会
二月十二日 等待变化等待机会
二月十三日 等待变化等待机会
Table 9: Character literals [tab:lex.ccon.literal]
Encoding prefix Kind Type Associated character encoding Example none ordinary character literal char encoding of execution character set 'v' non-encodable ordinary character literal int '\U0001F525' ordinary multicharacter literal int 'abcd' L wide character literal wchar_t encoding of execution wide-character set L'w' non-encodable wide character literal wchar_t L'\U0001F32A' wide multicharacter literal wchar_t L'abcd' u8 UTF-8 character literal char8_t UTF-8 u8'x' u UTF-16 character literal char16_t UTF-16 u'y' U UTF-32 character literal char32_t UTF-32 U'z'
/usr/bin/clang-11 -E ill.cpp
ill.cpp:1:22: error: invalid character ' ' character in raw string delimiter; use PREFIX( )PREFIX to delimit raw string
const char* s = R"y"; // ill-formed raw string, not "x" "y"
^
二月十四日 等待变化等待机会
clang可以使用的linker有这么些,让我惊讶的是,难道只有Linker才是体现操作系统的独特性吗?这一点仔细一想其实不言自明,不然为什么有wine来实现windows?所以linker实现了操作系统相关的部分。Clang provides all of these pieces other than the linker.
- Preprocessor: This performs the actions of the C preprocessor: expanding #includes and #defines. The -E flag instructs Clang to stop after this step.
- Parsing: This parses and semantically analyzes the source language and builds a source-level intermediate representation (“AST”), producing a precompiled header (PCH), preamble, or precompiled module file (PCM), depending on the input. The -precompile flag instructs Clang to stop after this step. This is the default when the input is a header file.
- IR generation: This converts the source-level intermediate representation into an optimizer-specific intermediate representation (IR); for Clang, this is LLVM IR. The -emit-llvm flag instructs Clang to stop after this step. If combined with -S, Clang will produce textual LLVM IR; otherwise, it will produce LLVM IR bitcode.
- Compiler backend: This converts the intermediate representation into target-specific assembly code. The -S flag instructs Clang to stop after this step.
- Assembler: This converts target-specific assembly code into target-specific machine code object files. The -c flag instructs Clang to stop after this step.
- Linker: This combines multiple object files into a single image (either a shared object or an executable).
The compiler runtime library provides definitions of functions implicitly invoked by the compiler to support operations not natively supported by the underlying hardware (for instance, 128-bit integer multiplications), and where inline expansion of the operation is deemed unsuitable.能不能这么理解有一些和运行环境相关的操作比如浮点数大整数等等也许运行期可以使用特殊的cpu的指令集,
...the object code interfaces between different user-provided C++ program fragments and between those fragments and the implementation-provided runtime and libraries. This includes the memory layout for C++ data objects, including both predefined and user-defined data types, as well as internal compiler generated objects such as virtual tables. It also includes function calling interfaces, exception handling interfaces, global naming, and various object code conventions.换句话说,在实现层面如果不同的c++模块要想“互联互通”必须要遵守一些基本的二进制码层面的规则,一个当然是对象的内存分布,这个直接影响到成员变量的偏移量;另一个就是异常处理和函数名字装饰,这个非常的重要,这个是一个约定成俗的规定,一旦确定要遵守才有可能不但做到向后兼容而且不同的c++库的兼容。因为这些部分和c语言也是无关的,纯粹c++的特性。这里我保存一个本地拷贝。
二月十五日 等待变化等待机会
Phase Inputs Outputs Options Preprocessing
- Source Language File
- Source Language File
- -E
- Stops the compilation after preprocessing
Translation
- Source Language File
- LLVM Assembly
- LLVM Bytecode
- LLVM C++ IR
- -c
- Stops the compilation after translation so that optimization and linking are not done.
- -S
- Stops the compilation before object code is written so that only assembly code remains.
Optimization
- LLVM Assembly
- LLVM Bytecode
- LLVM Bytecode
- -Ox
- This group of options controls the amount of optimization performed.
Linking
- LLVM Bytecode
- Native Object Code
- LLVM Library
- Native Library
- LLVM Bytecode Executable
- Native Executable
- -L
- Specifies a path for library search.
- -l
- Specifies a library to link in.
New Feature: Link Time Optimization这个ppt是十几年前的文档,是否反映今天的现实呢?原来这个是作者当年的宣言啊。我找到作者Chris Lattner也许是最早的ppt。 作者反复提到SSA:
- Optimize (e.g. inline, constant fold, etc) across files with -O4
- Optimize across language boundaries too!
这里each variable be assigned exactly once对于同一个变量的多次赋值重用要给它们赋予独特的别名吧?这个从逻辑上来看是最清晰与容易管理的,只有古早时代才有节约变量名的“人为”优化,那个年代程序员以最少的代码与变量名来“炫耀”自己的头脑。如今编译器代替了人脑来做这个优化的工作了?下面这个解释其实倒是很直观的,听上去也不难。static single assignment form
In compiler design, static single assignment form (often abbreviated as SSA form or simply SSA) is a property of an intermediate representation (IR), which requires that each variable be assigned exactly once, and every variable be defined before it is used. Existing variables in the original IR are split into versions, new variables typically indicated by the original name with a subscript in textbooks, so that every definition gets its own version. In SSA form, use-def chains are explicit and each contains a single element.
Converting ordinary code into SSA form is primarily a matter of replacing the target of each assignment with a new variable, and replacing each use of a variable with the "version" of the variable reaching that point.不过已经是新变量了何必还要“version”呢?彷佛在回到我的疑问一样wiki举例在使用这个变量的时候你不知道到底是哪一个"version"被使用了,如果有多条路径的话。这里又引入了Φ (Phi) function和所谓的“dominance frontiers"。好了,打住吧,我不是来学习编译原理的优化部分的。
The LLVM project has grown beyond its initial scope as the project is no longer focused on traditional virtual machines.怎么理解啊?
LLVM and the GNU Compiler Collection (GCC) are both compilers. The difference is that GCC supports a number of programming languages while LLVM isn't a compiler for any given language. LLVM is a framework to generate object code from any kind of source code.无意中闯入这个OmniSci Render,据说是使用了LLVM。
二月十六日 等待变化等待机会
The three techniques are link-time interprocedural optimization, run-time dynamic optimization, and profile-driven optimization.然后我们就只看标题
Traditional Approaches to Link-Time Interprocedural Optimization: ...gather as much of the program together into one place as possible, increasing the scope of analysis and transformation beyond a single translation unit.怎么解决这些传统的问题呢?以前的人不是不明白而是感觉根本做不到,而作者提出的方案我们今天依旧觉得是天方夜谭,我感觉就算知道它已经实现了依然是天方夜谭的夸夸其谈,天才就是这样子做到常人认为不可能的奇迹!Traditional Approaches to Run-Time Optimization: Run-time optimization and Just-In-Time (JIT) compilation are very common among the class of high-level language Virtual Machines (VMs). These VMs often target very dynamic languages ...use a machine-independent byte-code input which encodes these languages at a very high-level (effectively at the AST level). ...able to provide platform portability and security services in addition to reasonable performance.
- Very Low Level- Machine Code
- Very High Level- Abstract SyntaxTrees(AST)
Traditional Approaches to Compile-time Profile-Driven Optimization: ...uses the estimated run-time behavior of the application to improve its performance (often by optimizing common cases at the expense of uncommon cases)
- High Level Language Virtual Machines
- Architecture Level Virtual Machines and Dynamic Translators
- The first stage of compilation compiles the program, but inserts profiling instrumentation into the program to cause it to gather some form of profile information at run-time.
- The second stage links these instrumented object files into an instrumented executable.
- The third stage of profile-driven optimization requires the developer of the application to run the generated executable through a series of test runs, which are used to generate the profile information for the application.
- Finally, the fourth and fifth stages recompile the program (often from source) and relink it, using the collected profile information to optimize the program.
this approach has many suboptimal features:- First, profile information is only useful if it is accurate: realistic programs vs benchmarks.
- The larger problem, however, is that developers are often not even willing to use profile guided optimization at all because it is too cumbersome.
the static compilers in the LLVM system compile source code down to a low-level representation that includes high-level type information...At link time, the program is combined into a single unit of LLVM virtual instruction set code...This executable is native machine code, but it also includes a copy of the program's LLVM bytecode for later stages of optimization...The LLVM run-time optimizer simply monitors the execution of the running program, gathering profile information... either direct modification of the already optimized machine code or new code generation from the attached LLVM bytecode.也许我对于JIT的无知让我认为这是天方夜谭,但是在运行期不停地优化代码是否可以认为程序不再是一成不变的了呢?听上去编译永远在路上,程序的整个生命周期都在不停的优化,因为profile-driven意味着用户的使用也会改变程序的优化与执行。
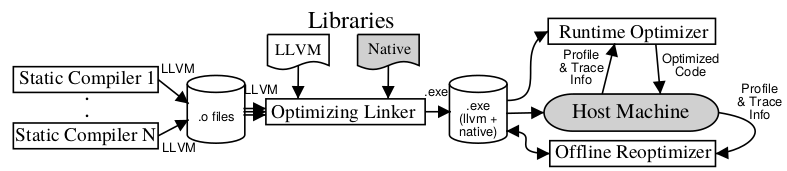 我以前对于llvm使用原系统的linker的原因依然不是很理解,也许是没有必要,或者不现实,因为你部署自己的linker相当于改变了整个操作系统的完整性,这个和自己创建虚拟机有什么不同?但是部署自己的虚拟机如jvm那样是对于用户的大的负担吧?但是要去动态修改代码那肯定是要部署自己作为虚拟机了吧?
我以前对于llvm使用原系统的linker的原因依然不是很理解,也许是没有必要,或者不现实,因为你部署自己的linker相当于改变了整个操作系统的完整性,这个和自己创建虚拟机有什么不同?但是部署自己的虚拟机如jvm那样是对于用户的大的负担吧?但是要去动态修改代码那肯定是要部署自己作为虚拟机了吧?
LLVM bytecode is contained in a special section of the executable, so it is only paged into memory when and if accessed by the runtime optimizer.这段话的理解也许是打开大门的钥匙
Key to the design of the LLVM virtual instruction set is the ability to support arbitrary source languages through a common low-level type system. Unlike high-level virtual machines, the LLVM type system does not specify an object model, memory management system, or specific exception semantics that each language must use. Instead, LLVM only directly supports the lowest-level type constructors, such as pointers, structures, and arrays, relying on the source language to map the high-level type system to the low-level one. In this way, LLVM is language independent in the same way a microprocessor is: all high-level features are mapped down to simpler constructs.但是我还是不太能够理解什么是all high-level features are mapped down to simpler constructs.
A programming language is said to have First-class functions when functions in that language are treated like any other variable. For example, in such a language, a function can be passed as an argument to other functions, can be returned by another function and can be assigned as a value to a variable.是不是可以理解就是这里的函数都是不可再细分的所谓的“原子”,比如当你把运行期动态库的函数当作是first-class function的时候,这个语言就是first-class languange了,因为这里的虚拟指令集就包含了这些“原子”函数。
LLVM provides an infinite set of typed virtual registers which can hold values of primitive types (integral, floating point, or pointer values). The virtual registers are in Static Single Assignment (SSA) form就是说为了实现这个所谓的SSA,你不能限制这种寄存器的数量。
LLVM programs transfer values between virtual registers and memory solely via load and store operations using typed pointers然后,就和普通的c语言很像的内存分global/stack/heap等等的细节,我想这个设计的原理就在于这句话:
The LLVM virtual instruction set is designed as a low-level representation with high-level type information.最大的特点是保留了高级语言的类型,同时尽可能贴近c语言。这个和它优化的原理有直接关系,因为它是要依靠SSA来把每一个变量作为一个“原子”来操作,所以,这里虽然是一个寄存器的指针但是代表的是一个类的实例,必须要保留它的类型信息才行吧? 至于说采用三地址码的原因就是这个实际上是RISC架构的必然选择,而且从根本上说现今Intel在移动设备的失败的根本原因是三地址码导致译码器的设计简单从而降低功耗,很明显的
Three-address code can be easily compressed从长远来看指令集的设计肯定也是走这条道路,因为CISC的选择是一个早期的机会主义,在指令集本身长度导致用户内存占用实在是一个非常非常小的因素,除了在计算机发展的早期阶段。我记得一个例子就是教授说当时为了节省指令里用到的literal要去动脑筋以便少打几个纸孔,这个都是极端的例子,再比如3G手机刚出世的时候高通还有所谓的“彩虹码”似乎是把编译好的机器码再压缩以便节省手机运行内存占用,可是很快的手机使用的内存甚至超过了一般的台式机,这些机会主义的做法都是很短暂的。
classes in C++ with inheritance and virtual methods can be represented using structures for the data values and a typed function table with indirect function calls for inheritance. This permits many high-level language-independent optimizations (e.g., virtual function resolution) to be performed on the LLVM code.这个似乎是不言自明的吧?
...an LLVM program to be type-safe if no cast instruction converts a non-pointer type to a pointer type or a pointer of one type to a pointer of another type既然是类型导向,那么程序员的cast就是破坏这个系统的潜在问题,所以,排除这个隐患就是必须的。什么是安全的呢?因为POD就那么几个基本类型大家对于它们之间的cast是有着深入认识的,用户定义的数据类型是不允许cast的,因为指针类型不能cast,所以,就堵住了这个隐患。llvm完全可以依赖变量的声明类型因为没有中途改变的cast。 这里看到一个例子说明细节有魔鬼就是我们不允许任何非指针cast成指针,那么合法的指针运算怎么办呢?就非法了吗?比如int*p=&i; p++;这里p作为指针在计算地址累加的时候要先转化为整数然后再转回指针类型那么这个不就违反了以上的法则了吗?所以,这里使用这个特别指令getelementptr才能避免这种违约。
The LLVM virtual instruction set is also unique in the manner it handles memory.In LLVM, all addressable objects (stack allocated locals, global variables, functions, and dynamically allocated memory) are all explicitly allocated, giving a unified memory model. Stack allocated locals (“automatic” variables and source-level alloca() calls) are all explicitly allocated using the alloca instruction. Heap allocated memory is allocated with the malloc instruction.就是说保留了变量的内存模型这个对于分析是至关重要的,java都是一种内存模型所以没有必要,但是llvm
二月十八日 等待变化等待机会
...PLT entries are normally relocated lazily by the dynamic linker...by default, the dynamic linker will not actually apply a relocation to the PLT until some code actually calls the function in question... In order to make this work, the program linker initializes the PLT entries to load an index into some register or push it on the stack, and then to branch to common code. The common code calls back into the dynamic linker, which uses the index to find the appropriate PLT relocation, and uses that to find the function being called.我当然理解就是以前看到的所谓的stub,在每个entry填写一个假地址就是所谓的类似于interrupt fault一样的做法,只有真的被调用了采取“解决”到达lazy的效果。我觉得还是要去看那本书,这个博客作为原理高屋建瓴的理解是足够了,但是不及细节的披露吧,至少现在还没有看到。
There's no instruction to obtain the value of the instruction pointer on x86。此外如果你没有读懂上面的就不理解前面说的这一段话的结论怎么来的
The program linker will create a relocation for the PLT entry which tells the dynamic linker which symbol is associated with that entry. This process reduces the number of dynamic relocations in the shared library from one per function call to one per function called.英语就是这样子的,一字之差蕴含了很多的意思,一目十行是很难理解这个差别吧,至少对于非英语母语的人来说。
For an ordinary defined symbol, the section is some section in the file (specifically, the symbol table entry holds an index into the section table). For an object file the value is relative to the start of the section. For an executable the value is an absolute address. For a shared library the value is relative to the base address.这个常识值得注意。
For an undefined reference symbol, the section index is the special value SHN_UNDEF which has the value 0. A section index of SHN_ABS (0xfff1) indicates that the value of the symbol is an absolute value, not relative to any section.我忘了section的数目上限是不是就是0xffff?
A section index of SHN_COMMON (0xfff2) indicates a common symbol...used for uninitialized global variables in C
Weak symbols come in two flavors. A weak undefined reference is like an ordinary undefined reference, except that it is not an error if a relocation refers to a weak undefined reference symbol which has no defining symbol. Instead, the relocation is computed as though the symbol had the value zero.这里就体现了我不明白weak的问题,以前看见同事使用attribute_weak,但是不明其所以然,现在就更糊涂了。
On Solaris, a weak defined symbol followed by a non-weak defined symbol is handled by causing all references to attach to the non-weak defined symbol, with no error. This difference in behaviour is due to an ambiguity in the ELF ABI which was read differently by different people. The GNU linker follows the Solaris behaviour.什么意思呢?难道说我同时定义了weak和non_weak,那么最后就都算是non_weak?这么做的意义是什么?是为了避免ODR的错误吗?我以前的理解是weak是为了不淹盖系统的定义,比如如果运行期系统库函数有定义就使用系统的,如果没有才使用我们自己的,这个对不对呢?这个例子可能能够说明,但是相当复杂,我还没有看懂。 这个结论值得记录,这个回答的帖子太长了。
基本的原则还是要理解的,就是.o是无条件的linking,而.a是选择性的
When a weak reference to
foo(i.e. a reference to weakly declaredfoo) is linked in a program, the linker need not find a definition offooanywhere in the linkage: it may remain undefined. If a strong reference tofoois linked in a program, the linker needs to find a definition offoo.A linkage may contain at most one strong definition of
foo(i.e. a definition offoothat declares it strongly). Otherwise a multiple-definition error results. But it may contain multiple weak definitions offoowithout error.If a linkage contains one or more weak definitions of
fooand also a strong definition, then the linker chooses the strong definition and ignores the weak ones.If a linkage contains just one weak definition of
fooand no strong definition, inevitably the linker uses the one weak definition.If a linkage contains multiple weak definitions of
fooand no strong definition, then the linker chooses one of the weak definitions arbitrarily.
When an object file is input to a linkage, the linker unconditionally links it into the output file.这里又引出了一个我长久以来的困惑,我究竟要怎么对付.a?我目前编译指令是把.a当作.o一样的编译而不是链接,这样子是否是正确的呢?对于.a是否不应该这样子呢?archive多个.o而成的.a究竟是否会失去什么?可能不会,但是是否会多出了很多不必要的代码呢?这个可能才是我担心的吧?不过从上文来看即使一个函数的reference也是要把整个obj都拷贝过去的。所以,我觉得把.a当作和.o一样的输入是正确的选择,而不是传统的想法里把.a和.so等量齐观的做法。因为本质上.a和.so的链接不是一回事儿。这里引出的结论是这么做的后果是.o/.a的顺序变得非常重要。 很重要的一点就是如果在编译的时候一个函数被定义为undefined weak reference的话,随后linker压根儿不屑于再去resolve它,尤其是你的.a里有定义也没有用了,因为.a并不是绝对必须链接的,linker压根不需要去解决。这么做的好处是什么呢?我一点也看不出。gnu-gcc的定义是这样子的When static library is input to a linkage, the linker examines the archive to find any object files within it that provide definitions it needs for unresolved symbol references that have accrued from input files already linked. If it finds any such object files in the archive, it extracts them and links them into the output file, exactly as if they were individually named input files and the static library was not mentioned at all.
The weak attribute causes the declaration to be emitted as a weak symbol rather than a global. This is primarily useful in defining library functions which can be overridden in user code, though it can also be used with non-function declarations.就是说用户定义自己的overridden的函数不会造成链接时候的重定义错误。这个应该在动态库里才有用吧?静态库里是无效的。或者在声明的时候不能使用,只能在定义的时候才使用,这个是基本原则。
-DLLVM_ENABLE_PROJECTS="..."总是编译失败,作者写的这个解决的算法相当的好,我是不是应该收藏一下呢?
- The symbol name
- The symbol version.
- Whether the symbol is the default version or not.
- Whether the symbol is a definition or a reference or a common symbol.
- The symbol visibility.
- Whether the symbol is weak or strong (i.e., non-weak).
- Whether the symbol is defined in a regular object file being included in the output, or in a shared library.
- Whether the symbol is thread local.
- Whether the symbol refers to a function or a variable.
- If A has a version:
- If B has a version different from A, they are actually different symbols.
- If B has the same version as A, they are the same symbol; carry on.
- If B does not have a version, and A is the default version of the symbol, they are the same symbol; carry on.
- Otherwise B is probably a different symbol. But note that if A and B are both undefined references, then it is possible that A refers to the default version of the symbol but we don’t yet know that. In that case, if B does not have a version, A and B really are the same symbol. We can’t tell until we see the actual definition.
- If A does not have a version:
- If B does not have a version, they are the same symbol; carry on.
- If B has a version, and it is the default version, they are the same symbol; carry on.
- Otherwise, B is probably a different symbol, as above.
- If A is thread local and B is not, or vice-versa, then we have an error.
- If A is an undefined reference:
- If B is an undefined reference, then we can complete the resolution, and more or less ignore B.
- If B is a definition or a common symbol, then we can resolve A to B.
- If A is a strong definition in an object file:
- If B is an undefined reference, then we resolve B to A.
- If B is a strong definition in an object file, then we have a multiple definition error.
- If B is a weak definition in an object file, then A overrides B. In effect, B is ignored.
- If B is a common symbol, then we treat B as an undefined reference.
- If B is a definition in a shared library, then A overrides B. The dynamic linker will change all references to B in the shared library to refer to A instead.
- If A is a weak definition in an object file, we act just like the strong definition case, with one exception: if B is a strong definition in an object file. In the original SVR4 linker, this case was treated as a multiple definition error. In the Solaris and GNU linkers, this case is handled by letting B override A.
- If A is a common symbol in an object file:
- If B is a common symbol, we set the size of A to be the maximum of the size of A and the size of B, and then treat B as an undefined reference.
- If B is a definition in a shared library with function type, then A overrides B (this oddball case is required to correctly handle some Unix system libraries).
- Otherwise, we treat A as an undefined reference.
- If A is a definition in a shared library, then if B is a definition in a regular object (strong or weak), it overrides A. Otherwise we act as though A were defined in an object file.
- If A is a common symbol in a shared library, we have a funny case. Symbols in shared libraries must have addresses, so they can’t be common in the same sense as symbols in an object file. But ELF does permit symbols in a shared library to have the type
STT_COMMON(this is a relatively recent addition). For purposes of symbol resolution, if A is a common symbol in a shared library, we still treat it as a definition, unless B is also a common symbol. In the latter case, B overrides A, and the size of B is set to the maximum of the size of A and the size of B.
Versions can also be used in an object file (this is a GNU extension to the original Sun implementation). This is useful for specifying versions without requiring a version script. When a symbol name containts the
@character, the string before the@is the name of the symbol, and the string after the@is the version. If there are two consecutive@characters, then this is the default version.
二月十九日 等待变化等待机会
~/Downloads/cmake-3.18.4/bin/cmake -DLLVM_ENABLE_PROJECTS="clang;clang-tools-extra;compiler-rt;libc;libclc;libcxx;libcxxabi;libunwind;lld;lldb" -DLLVM_ENABLE_SPHINX=ON -DLLVM_PARALLEL_LINK_JOBS=1 -DLLVM_USE_LINKER=gold -G "Unix Makefiles" ../llvm
编译clang花了好几天才成功,看来是内存的问题,当使用默认配置linking的时候经常会失败就是因为并行需要大量内存,所以只能在并行编译成功链接阶段失败的时候再次是用单线编译才链接成功。
二月二十日 等待变化等待机会
-fno-rtti,这个简直要把人逼疯了。而静态库的链接是如此的麻烦因为顺序有很大的关系,变成我经常要尝试不同的顺序,而clang的静态库又依赖于llvm的静态库,有的时候但看名字还猜不出来是哪一个目录下的静态库,因为有时候一个目录下还会一分为二甚至三,这个时候我只能通过ar t *.a来查找.o文件来判断是哪一个,这个时候又有一个问题就是nm -C *.a里看到的函数symbol必须看仔细了有时候一个虚函数可能有destructor但是没有constructor,你以为它就定义在这个库里面了,实际上是在别的库里实现的。这个时候粗略看类的名字并不管用,还是要更仔细。此外还遇到这些系统函数的定义问题比如setupterm未定义这个库-ltinfo我还是很多年前遇到过一两次的链接。总之,我对于llvm的大图景越来越表示怀疑,它的代码结构固然有不错的架构,可是它的文档似乎停留在很多年前了。二月二十一日 等待变化等待机会
二月二十二日 等待变化等待机会
Link-time optimization(LTO) typically works on intermediate representation (IR) ...there are no more high-level language constructs, so link-time-optimization is language-agnostic.
The bootstrapping process will complete the following steps:
- Build tools necessary to build the compiler.
- Perform a 3-stage bootstrap of the compiler. This includes building three times the target tools for use by the compiler such as binutils (bfd, binutils, gas, gprof, ld, and opcodes) if they have been individually linked or moved into the top level GCC source tree before configuring.
- Perform a comparison test of the stage2 and stage3 compilers.
- Build runtime libraries using the stage3 compiler from the previous step.
For a native build, the default configuration is to perform a 3-stage bootstrap of the compiler when ‘make’ is invoked ...In special cases, you may want to perform a 3-stage build even if the target and host triplets are different. This is possible when the host can run code compiled for the target (e.g. host is i686-linux, target is i486-linux).
二月二十三日 等待变化等待机会
LTO is not a default language, but is built by default because --enable-lto is enabled by default.
--enable-default-pieTurn on -fPIE and -pie by default.
换句话说就是我能够实用gdb全依赖于开始的时候gdb自动的帮我做了很多工作,这其中的机制非常的复杂我一时还领悟不了,大概就是The following values are supported:
- 0 – No randomization. Everything is static.
- 1 – Conservative randomization. Shared libraries, stack,
mmap(), VDSO and heap are randomized.- 2 – Full randomization. In addition to elements listed in the previous point, memory managed through
brk()is also randomized.
作者又自己发现了一个问题How is the address of the text section of a PIE executable determined in Linux? 这个问题就彻底超出了我的能力了,我只能知道这个是内核的一个设定值吧?By turning ASLR off (with either
randomize_va_spaceorset disable-randomization off), GDB always givesmainthe address:0x5555555547a9, so we deduce that the-pieaddress is composed from:0x555555554000 + random offset + symbol offset (79a)
结果我对于反复出现的canadian cross build感到困惑,原来这个比我想像的交叉编译还要多一些,我以前只是印象中是两个平台之间的交叉编译就是目标和结果编译器是同一个平台。--enable-nls--disable-nlsThe --enable-nls option enables Native Language Support (NLS), which lets GCC output diagnostics in languages other than American English. Native Language Support is enabled by default if not doing a canadian cross build. The --disable-nls option disables NLS.
The Canadian Cross is a technique for building cross compilers for other machines. Given three machines A, B, and C... When using the Canadian Cross with GCC, there may be four compilers involved在这里联想到之前的--enable-bootstrap的意义就是要求binutils这些工具都编译好了在各个stage的目录里,这个和交叉编译是有紧密关系的
- The proprietary native Compiler for machine A (1) (e.g. compiler from Microsoft Visual Studio) is used to build the gcc native compiler for machine A (2).
- The gcc native compiler for machine A (2) is used to build the gcc cross compiler from machine A to machine B (3)
- The gcc cross compiler from machine A to machine B (3) is used to build the gcc cross compiler from machine B to machine C (4)
GCC requires that a compiled copy of binutils be available for each targeted platform. Especially important is the GNU Assembler. Therefore, binutils first has to be compiled correctly with the switch --target=some-target sent to the configure script. GCC also has to be configured with the same --target option.这里的细节一直对我都是模糊的,比如
Cross-compiling GCC requires that a portion of the target platform's C standard library be available on the host platform. The programmer may choose to compile the full C library, but this choice could be unreliable. The alternative is to use newlib, which is a small C library containing only the most essential components required to compile C source code.这个newlib对我来说就是陌生的,我以前听说过所谓的alternative c library,不知道那些embeded用的是否就是这个newlib? 另一个细节我始终模糊就是gnu的这三个term。也许阅读这里更清楚一些吧。
换句话说,build/host/target好想祖孙三代的意思。
- --build=build
The system on which the package is built.
- --host=host
The system where built programs and libraries will run.
- --target=target
When building compiler tools: the system for which the tools will create output.
The names host and target are relative to the compiler being used and shifted like son and grand-son.
error=01;31:warning=01;35:note=01;36:caret=01;32:locus=01:quote=01This is because of the difference between assembler created symbols and compiler-generated symbols. When an assembler creates a symbol, all it really does is to provide a label that corresponds to a given address. Whereas when a compiler creates a symbol, it creates a space in the program's data, installs a value into that space, and then uses the symbol as an indirect reference to that value.
.pushsection and .popsectionThe program must not have a stack in an executable region of memory.这个是怎么检查的?
二月二十四日 等待变化等待机会
You can invoke the preprocessor either with the cpp command, or via gcc -E.当然是可以的了,只不过cpp的运行依赖于cc1/cc1plus取决于所选的语言:-x c/c++它们的关系是怎样的我还不理解,我看到libcpp完全可以实现所有的功能。那么cc1是前端的driver吗?我的猜想是之所以有这么多层的嵌套是因为gcc支持多种语言,所以它的前端的可执行程序也需要这样子的多层吧?
The cpp options listed here are also accepted by gcc and have the same meaning. Likewise the cpp command accepts all the usual gcc driver options...换言之就是gcc -E直接呼叫的是cc1或者cpp,现在它们之间的关系我还不清楚。
By contrast with LD_PRELOAD, the --preload option provides a way to perform preloading for a single executable without affecting preloading performed in any child process that executes a new program.这个要怎么理解呢?难道它们会被当作参数传递给子进程比如vfork之类的吗?这里我们再复习一下ld的解决方式
When resolving shared object dependencies, the dynamic linker first inspects each dependency string to see if it contains a slash (this can occur if a shared object pathname containing slashes was specified at link time). If a slash is found, then the dependency string is interpreted as a (relative or absolute) pathname, and the shared object is loaded using that pathname.就是说在链接的时候传递的动态库文件名本身有路径就制止了ld在动态加载时候的搜索策略而是直接使用。那么如果没有slash的话搜索策略我们再次复习一下 我现在要综合一下ld的manpage和在线版的manpage我觉得这个问题很复杂微妙的原因就是包含了链接期和动态运行期的两个阶段,互为因果而其中用户直接使用ld的可能性不是没有尽管通常都是系统自动调用,但是命令行参数无论如何都是支持的何况还有开发者debug的用途呢?
Using the directories specified in the DT_RPATH dynamic section attribute of the binary if present and DT_RUNPATH attribute does not exist. Use of DT_RPATH is deprecated.这叫怎么回事呢?首先寻找DT_RPATH然后又说它是deprecated?我随后查看原始的ld的manpage才明白英文是这么讲才让人明白
The "DT_RPATH" entries are ignored if "DT_RUNPATH" entries exist.
The linker uses the following search paths to locate required shared libraries:现在我们再来比较一下online manpage讨论的关于动态库运行期解决的问题
- Any directories specified by -rpath-link options.
- Any directories specified by -rpath options. The difference between -rpath and -rpath-link is that directories specified by -rpath options are included in the executable and used at runtime, whereas the -rpath-link option is only effective at link time. Searching -rpath in this way is only supported by native linkers and cross linkers which have been configured with the --with-sysroot option.
so, we are talking about ld.so used as cmd line executable.- On an ELF system, for native linkers, if the -rpath and -rpath-link options were not used, search the contents of the environment variable "LD_RUN_PATH".
This is the first time I heard so!- I don't care!
On SunOS, if the -rpath option was not used, search any directories specified using -L options.- For a native linker, search the contents of the environment variable "LD_LIBRARY_PATH".
- For a native ELF linker, the directories in "DT_RUNPATH" or "DT_RPATH" of a shared library are searched for shared libraries needed by it. The "DT_RPATH" entries are ignored if "DT_RUNPATH" entries exist.
See above comments! So, this is only for case of linking dso, not executable! because no such section for executable.- The default directories, normally /lib and /usr/lib.
- For a native linker on an ELF system, if the file /etc/ld.so.conf exists, the list of directories found in that file.
If a shared object dependency does not contain a slash, then it is searched for in the following order:这里有趣的是所谓的secure-execution mode
- Using the directories specified in the DT_RPATH dynamic section attribute of the binary if present and DT_RUNPATH attribute does not exist. Use of DT_RPATH is deprecated.
- Using the environment variable LD_LIBRARY_PATH, unless the executable is being run in secure-execution mode (see below), in which case this variable is ignored.
- Using the directories specified in the DT_RUNPATH dynamic section attribute of the binary if present. Such directories are searched only to find those objects required by DT_NEEDED (direct dependencies) entries and do not apply to those objects' children, which must themselves have their own DT_RUNPATH entries. This is unlike DT_RPATH, which is applied to searches for all children in the dependency tree.
- From the cache file /etc/ld.so.cache, which contains a compiled list of candidate shared objects previously found in the augmented library path. If, however, the binary was linked with the -z nodeflib linker option, shared objects in the default paths are skipped. Shared objects installed in hardware capability directories (see below) are preferred to other shared objects.
- In the default path /lib, and then /usr/lib. (On some 64-bit architectures, the default paths for 64-bit shared objects are /lib64, and then /usr/lib64.) If the binary was linked with the -z nodeflib linker option, this step is skipped.
Secure-execution mode For security reasons, if the dynamic linker determines that a binary should be run in secure-execution mode, the effects of some environment variables are voided or modified, and furthermore those environment variables are stripped from the environment, so that the program does not even see the definitions. Some of these environment variables affect the operation of the dynamic linker itself, and are described below. Other environment variables treated in this way include: GCONV_PATH, GETCONF_DIR, HOSTALIASES, LOCALDOMAIN, LOCPATH, MALLOC_TRACE, NIS_PATH, NLSPATH, RESOLV_HOST_CONF, RES_OPTIONS, TMPDIR, and TZDIR.它的实现方式是通过这个我不熟悉的领域getauxval我以前以为只有cap这种安全机制,没想到还有这种内核的安全机制。
If, however, the binary was linked with the -z nodeflib linker option, shared objects in the default paths are skipped. Shared objects installed in hardware capability directories (see below) are preferred to other shared objects.我们才能理解为什么/etc/ld.so.nohwcap会被查询,这个是硬件相关的动态库,这个也是头疼了,在同一个操作系统里安装的时候你难道要安装各种硬件相关的库吗?是为了交叉编译吗?为什么不单独放在工具链里呢?这些设计都让人难以理解。至于preload是否也要存在一个文件里,如果放得久了何必要preload,这个机制本来就是设计给特例的,特例多了不就是常例了吗?
echo $PATH
/home/nick/.local/bin:/home/nick/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
nick@nick-HP-Laptop:~/tmp/gcc-11-20210214_source/gcc-11-20210214/gcc$ ll /usr/bin/x86_64-linux-gnu-gcc-7 -rwxr-xr-x 1 root root 1047488 12月 4 2019 /usr/bin/x86_64-linux-gnu-gcc-7* nick@nick-HP-Laptop:~/tmp/gcc-11-20210214_source/gcc-11-20210214/gcc$ ll /usr/bin/x86_64-linux-gnu-cpp-7 -rwxr-xr-x 1 root root 1047488 12月 4 2019 /usr/bin/x86_64-linux-gnu-cpp-7*
二月二十五日 等待变化等待机会
The program collect2 works by linking the program once and looking through the linker output file for symbols with particular names
indicating they are constructor functions. If it finds any, it creates a new temporary ‘.c’ file containing a table of them,
compiles it, and links the program a second time including that file.
这个是一个什么样的骚操作啊?难道你的代码里没有constructor吗?难道这个constructor的代码不会被翻译成机器码吗?下面这个解释了__main和-nostdlib
The actual calls to the constructors are carried out by a subroutine called为什么linking要这么大费周张呢?为什么一次做不完要再来一次呢?是否。。。且慢,这个不是产生constructor的机器码,而是要在main运行起来之前先把所有用到的constructor先调用安排妥当,相当于initialization,我记得很久以前我曾经痛苦的debug经历,当时的程序还没有启动就直接退出了,最后落实到一个类的constructor,但是gdb是无法设断点在那个constructor的,为什么我也忘了,总之在进入main之前程序就退出了,看来就是这个main之前的__main,我唯一有印象的是最后只有在preprocessor下我看到了代码的宏展开有问题,因为无法使用gdb所以只能从代码去debug,这个真的是很痛苦的过程。__main, which is called (automatically) at the beginning of the body ofmain(providedmainwas compiled with GNU CC). Calling__mainis necessary, even when compiling C code, to allow linking C and C++ object code together. (If you use -nostdlib, you get an unresolved reference to__main, since it’s defined in the standard GCC library. Include -lgcc at the end of your compiler command line to resolve this reference.)
The program collect2 is installed as ld in the directory where the passes of the compiler are installed.什么叫做real-ld,我有吗?有的,我的ld是在这里/usr/bin/x86_64-linux-gnu-ld.bfd和它并排的是x86_64-linux-gnu-ld.gold,这个是"real-ld"。那么我的gcc在哪里?它的伴侣collect2和它在一起吗?我的gcc是一个symlink最终指向了/usr/bin/x86_64-linux-gnu-gcc-7而昨天我已经直到它最终是要呼叫cc1/cc1plus的,它们在这里/usr/lib/gcc/x86_64-linux-gnu/7/cc1, /usr/lib/gcc/x86_64-linux-gnu/7/cc1plus,和它们排排座的是/usr/lib/gcc/x86_64-linux-gnu/7/collect2,
The compiled code for certain languages includes constructors (also called initialization routines)—functions to initialize data in the program when the program is started. These functions need to be called before the program is “started”—that is to say, before main is called.这里就解释的很清楚为什么了?我之前还是想了半天才理解到这一层。
To make the initialization and termination functions work, the compiler must output something in the assembler code to cause those functions to be called at the appropriate time. When you port the compiler to a new system, you need to specify how to do this.这段话怎么理解呢?因为loader只知道我执行可执行程序就是入口__start,至少这个是assembler的做法,那么你现在要求它在执行之前再做什么呢?我现在还是不确定我直到谁做了这个调用__main的工作。阅读这个部分非常的困难,因为相当的复杂,共有四种变数,取决于不同操作系统和可执行文件动态库格式的支持情况。对于我的问题有一个最简单的办法就是在用户的main里插入第一个__main来执行我们的ctor/dctor,但是这个是多么的intrusive啊,你要修改用户的程序代码吗?当然不是,只不过汇编码自己插入一些而已,没人会注意的,哈哈。但是如果系统和动态库格式支持这些section那就容易了吧。总之不是做移植工作的人估计很难真正理解其中的奥妙。
John: (holds up the robot arm) Will this melt in there? Terminator: Yes, throw it in. John: Adios! (John throws the arm into the molten steel) Terminator: And the chip. Sarah: (in relief) It's over. Terminator: No. There is one more chip... (the Terminator points to his head)... and it needs to be destroyed, also. Here. I cannot self-terminate. You must lower me into the steel. John: No! You can't go! You can't go! No, it'll be okay, stay with us! Terminator: It has to end here. John: I order you not to go. I order you not to go, (yelling) I order you not to go! (he starts to cry) Terminator: I know now why you cry... (the Terminator wipes away John's tear) ...but it is something I can never do. (gives elevator controls to Sarah) Terminator: Good-bye. (Sarah lowers him into the molten steel. He gives a thumbs up as he is lowered) Terminator 2: Judgment Day T-850: You cannot self-terminate. John Connor: No, you can't. I can do anything I want. I'm a human being, not some god-damn robot. T-850: (correcting him) Cybernetic organism. John Connor: Whatever! Terminator 3: Rise of the Machines
There are three system names that the build knows about: the machine you are building on (build), the machine that you are building for (host), and the machine that GCC will produce code for (target). When you configure GCC, you specify these with --build=, --host=, and --target=.这个让我想起一个“三民主义”的翻译短语:
这些理解起来有些抽象,后面的部分我看不大懂。
- If build, host, and target are all the same, this is called a native.
- If build and host are the same but target is different, this is called a cross.
- If build, host, and target are all different this is called a canadian (for obscure reasons dealing with Canada's political party and the background of the person working on the build at that time).
- If host and target are the same, but build is different, you are using a cross-compiler to build a native for a different system. Some people call this a host-x-host, crossed native, or cross-built native.
- If build and target are the same, but host is different, you are using a cross compiler to build a cross compiler that produces code for the machine you're building on. This is rare, so there is no common way of describing it. There is a proposal to call this a crossback.
float.h stdalign.h stdatomic.h stddef.h stdint-gcc.h stdnoreturn.h unwind-arm-common.h iso646.h stdarg.h stdbool.h stdfix.h stdint-wrap.h tgmath.h varargs.h
二月二十六日 等待变化等待机会
‘#import’ is not a well designed feature. It requires the users of a header file to know that it should only be included once. It is much better for the header file’s implementor to write the file so that users don’t need to know this. Using a wrapper ‘#ifndef’ accomplishes this goal.这个让我感到混淆因为google到不少的地方称这个是gcc的deprecated feature,而且似乎语法中也看不到这个directive,我手动测试的确是这样子警告:
warning: #import is a deprecated GCC extension既然如此为什么文档不把它删除或者提醒呢?
A preprocessing directive of the form
#
searches a sequence of implementation-defined places for a header identified uniquely by the specified sequence between the < and > delimiters, and causes the replacement of that directive by the entire contents of the header. How the places are specified or the header identified is implementation-defined.include< h-char-sequence > new-line
这里让我吃惊的是...ignoring nonexistent directory "/usr/local/include/x86_64-linux-gnu" ignoring nonexistent directory "/usr/lib/gcc/x86_64-linux-gnu/7/../../../../x86_64-linux-gnu/include" #include "..." search starts here: #include <...> search starts here: /usr/lib/gcc/x86_64-linux-gnu/7/include /usr/local/include /usr/lib/gcc/x86_64-linux-gnu/7/include-fixed /usr/include/x86_64-linux-gnu /usr/include
/usr/local/include优先于
/usr/include,另一个值得注意的是之前我遇到gcc文档里提到的
include-fixed也体现在了搜索路径了。 在这个路径下有
limits.h和
syslimits.h,其中的内容实际上是有趣的,尽管我不是很理解。
How sequences in both forms of header names are mapped to headers or external source file names (C90 6.1.7, C99 and C11 6.4.7).我看了一下c语言的标准其实和c++是一样的,因为在preprocessor这一块两者是一致的。
二月二十七日 等待变化等待机会
uniquely就不是一件容易的事情。其次,为了和gcc兼容几乎是所有人的共识,这一点是不言自谕的,因为gcc就是工业标准,
incpath.c:merge_include_chains
canonical版本的比较了。这个都是细节,可是很有意义。
incpath.c:merge_include_chains的算法逻辑相当的复杂,我目前看的不是很理解,给定四个链表:quote,bracket,system,after如何做到去重呢?
heads[INC_SYSTEM] = remove_duplicates (pfile, heads[INC_SYSTEM], 0, 0, verbose);根本没有去重的动作,当然了system一般来说已经是保证去重了的吧?我现在对于after的来历还不知道,估计也是系统来的所以没有去重也许问题不大。所以这两个链表基本就是串接的动作。
register_include_chains
configure --enable-static --disable-dynamic --disable-bootstrap --enable-languages=c++ --disable-multilib现在我加上了--newlib因为报出了
configure-target-libstdc++-v3' failed很多时候着急就是找不到,这里的编译gcc的configure的官方网页。
../gcc-11-20210221/configure CFLAGS='-ggdb3 -O0' CXXFLAGS='-ggdb3 -O0' LDFLAGS=-ggdb3 --prefix=/home/nick/tmp/gcc-11-20210221_install --disable-bootstrap --disable-multilib --enable-languages=c++ --enable-gcc-debug使用这个编译配置gdb就完全没有问题了。
mkdir gcc-10.2.0 && cd gcc-10.2.0wget ftp://gcc.gnu.org/pub/gcc/releases/gcc-10.2.0/gcc-10.2.0.tar.gz
tar vxf gcc-10.2.0.tar.gzcd gcc-10.2.0./contrib/download_prerequisitesmkdir ../build && cd ../build
../gcc-10.2.0/configure CFLAGS='-ggdb3 -O0' CXXFLAGS='-ggdb3 -O0' LDFLAGS=-ggdb3 --prefix=/home/nick/Downloads/gcc-10.2.0/gcc-10.2.0-install --disable-bootstrap --disable-multilib --enable-languages=c++ --enable-gcc-debugmake -j$(nproc)
make install二月二十八日 等待变化等待机会
kind preprocessor c compiler c++ compiler linker assembler binary cpp cc1 cc1plus collect2 as
gcc -print-prog-name=cc1 /usr/lib/gcc/x86_64-linux-gnu/7/cc1
透视很多信息的地方,以后要多注意。
--with-tls=dialect的第一反应是tls难道是Thread Local Storage?const_cast不行吗?而且对于这里使用dl还要事先export global symbols from the executable by linking it with the "-E" flag
If you use我看得不是很明白但是如果我理解正确的话这个做法使用dl+dynamic_cast似乎脱裤子放屁一样的笨拙,肯定有别的办法避免吧?也许我是孤陋寡闻吧?dlopento explicitly load code from a shared library, you must do several things. First, export global symbols from the executable by linking it with the "-E" flag (you will have to specify this as "-Wl,-E" if you are invoking the linker in the usual manner from the compiler driver,g++). You must also make the external symbols in the loaded library available for subsequent libraries by providing theRTLD_GLOBALflag todlopen. The symbol resolution can be immediate or lazy.
libcc1plugin.so,libcp1plugin.so。但是我粗略的搜索代码感觉这个plugin已经废弃了。
gcc -print-file-name=plugin
三地址码
It was originally intended to be a sort of standard cross-platform library, ...However, the development of standards for C and POSIX took away some of the impetus for this, and libiberty came to be used primarily as a support library for the GNU toolchain. ... The name is a pun or word play on the word "liberty". On Unix-like operating systems, library files are always named "lib" + "the name of the library." But when they are linked to with a C compiler command (cc, gcc, etc.), the command line flag specifying the library is -l followed by the part of the library name after "lib". In libiberty's case it therefore becomes -liberty.这最后一段pun是今天早上最好的幽默。
三月一日 等待变化等待机会
familiar template lambda官方名称是
familiar template syntax for generic lambdas的概念的阻碍,而是对于
integer_sequence这个模板神器的运用的再次领悟,现在才更加深入的领会在meta-programming里如何把实参转化为型参的妙悟。型参本来是模板中对于实参的引领,可是在meta programming里有时候你需要把实参
牵引到型参来操作,那么怎么做到呢?只有领会到这一层才能理解integer_sequence的妙用。然而仅仅领会到什么和为什么并不能解决怎么办的问题,世间最难的往往也停留在实现的最后一公里,尽管开天辟地的革命式创举在人们心目中的地位是无比的荣光,彷佛那些金字塔的设计者往往立碑书传一系列的宏伟蓝图,但是对于怎么把一块块巨石从尼罗河搬运到塔顶的过程却语焉不详,这其中无数的奴隶肩挑手抗出力之余具体设计出了堆土成斜坡的构思却被僧侣们无视而不被记载从而淹没在历史的长河里成为谜题。这里的实现的最后一公里就是如此的微妙有时候仿佛就是一层窗户纸,你甚至已经可以看到对面婆娑的倩影却始终如梦魇般可望而不可及。这里我想仅仅把制作从一开始的数组做一个小小的扩展使之能够随心所欲的产生从任意数字开始的数列,听上去似乎就是一个很简单的玩意儿,也许我的驽钝竟然花费了超过半小时还无法想出来怎么使用
familiar template lambda,结果只好作罢,也许不太可能吧? 这里是验证程序及其结果 最后还是google解决了问题,我怎么可能想到一个我完全不知道的操作符template operator()呢?这个是改进的类似oneliner的
familiar template lambda的解决方案 结果当然是一样的了。
lambda,为什么我不知道有这个
template operator()的调用呢?这个在语法里有体现吗?首先看看"Familiar template syntax for generic lambdas"的起源,论文提到的定义generic_lambda
A lambda is a generic lambda if the lambda-expression has any generic parameter type placeholders ([dcl.spec.auto]), or if the lambda has a template-parameter-list.这个仅仅是基本的定义,那么关键的关键是理解lambda closure type,这里提到的这句话The function call operator template for a generic lambda can be an abbreviated function template我看了半天也不明所以然,再追踪下去看到这个例子我就吐了 天哪,这个lambda返回的是怎样一个lambda呢?
它的调用更加让人称奇,究竟返回的是lambda还是lambda的运行结果呢?吐完之后擦了擦嘴还是要继续看
p从
vglambda手里接过来的是什么呢?
libc++abi.a我只有模模糊糊的记得我又一个特殊的需求要单独编译libc++abi为静态库,原因也许是这个gcc自带的库是动态库而它又依赖于一些其他的glibc的高版本的运行库吧?所以我debug的时候不想设定LD_LIBRARY_PATH直接运行,这个也许就是编译
Libc++abi.a的原因吧,可是直接编译gcc的这个静态库我当时可能是没有找到办法,就借用了llvm自带的这个库,我当时的检查应该是说llvm并没有做什么改动仅仅是wrap了一下吧,也许是调用不同版本号的glibc?我记不得了,但是它的makefile能够顺利编译这个是最大的改进因为gcc下无法单独编译。然而现在我看到我的错误是
null returned from __cxa_demangle_llvm让我怀疑这个是llvm版本的问题,于是我回归本来的abi::__cxa_demangle接口而不是llvm的__cxxabiv1::__cxa_demangle,但是同样的返回null,然后我使用boost自带的
boost::typeindex::stl_type_index::type_id_runtime(t).pretty_name();vglambda返回的类型对于demangle函数来说是一个不可解的谜团,它的typeid::name()是这样子的ZZ7test361vENKUlT_E_clIZ7test361vEUlS_T0_T1_E0_EEDaS_EUlDpOT_E_这个std::bad_exception不是定义在<stdexcept>里的而是在<exception>里的,注释里有这样的提示
See comment in eh_exception.cc.,这样子仿佛在探案里的线索一样我来到了
eh_exception.cc这里赫然写着 原来如此,它返回了它的类型,而附近的注释里这样写着
作者指的是这个注释吗?// NB: Another elegant option would be returning typeid(*this).name() // and not overriding what() in bad_exception, bad_alloc, etc. In // that case, however, mangled names would be returned, PR 14493.
auto p = vglambda( [](auto v1, auto v2, auto v3)难道vglambda的类型也没有了?显然不是的,否则我早就注意到了这个问题,vglambda的类型是test361()::{lambda(auto:1)#1},那么我们比较一下它们的typeid看看吧:
typeid(vglambda).name() ==>Z7test361vEUlT_E_
typeid(p).name() ==>ZZ7test361vENKUlT_E_clIZ7test361vEUlS_T0_T1_E0_EEDaS_EUlDpOT_E_
bad_exception的定义原因的注解里有如下的话语
If an exception is thrown which is not listed in a function's exception specification, one of these may be thrown.这个就是
bad_exception的设计的使用场景,而对于这样一个空空荡荡的空定义异常的ctor的注释是这么说的
于是我跟随这个链接来到了古老的gcc的文档,这里又一次提到了我之前困惑的// This declaration is not useless: // http://gcc.gnu.org/onlinedocs/gcc-3.0.2/gcc_6.html#SEC118
vague linkage这里讨论的是三类情况
inline functions,
vtablesand
type_info objects,前两天我就没有看懂类似的部分甚至我怀疑这个是古老的实现细节也许过时了?我不确定,但是至少关于type_info我的理解是只有用到才定义吧?
注意到了吗?有多态的类的type_info才会无条件的和它的vtable一起被产生,对于其他类型都是有用到才产生。那么回过头来我们看看vtable是否会被写入机器码呢?
- type_info objects
- C++ requires information about types to be written out in order to implement `dynamic_cast', `typeid' and exception handling. For polymorphic classes (classes with virtual functions), the type_info object is written out along with the vtable so that `dynamic_cast' can determine the dynamic type of a class object at runtime. For all other types, we write out the type_info object when it is used: when applying `typeid' to an expression, throwing an object, or referring to a type in a catch clause or exception specification.
我的理解就是如果你第一个非纯虚函数没有定义的话就会导致整个虚表都没有产生。这个是否还是如此我需要做实验才能确定,我很担心gcc的文档年久失修,而且这个是很古老的版本的文档,我在最新的文档里
- VTables
- C++ virtual functions are implemented in most compilers using a lookup table, known as a vtable. The vtable contains pointers to the virtual functions provided by a class, and each object of the class contains a pointer to its vtable (or vtables, in some multiple-inheritance situations). If the class declares any non-inline, non-pure virtual functions, the first one is chosen as the "key method" for the class, and the vtable is only emitted in the translation unit where the key method is defined.
Note: If the chosen key method is later defined as inline, the vtable will still be emitted in every translation unit which defines it. Make sure that any inline virtuals are declared inline in the class body, even if they are not defined there.
libc++和
libc++abi这两个库我是在llvm里看到才引起注意,因为之前gcc有很多库都不明其所以然甚至不知道是不是和我的运行环境有关,这个帖子说明了一些基本情况,以下就是我的理解: libc++是实现c++ standard library,但是必须依赖于libc++abi(LLVM的实现)/libsupc++(gnu/gcc的实现)等等的所谓实现ABI的库的,之前我们已经有了ABI的概念,就是一些基本的c++实现层的要求,它的要求是类似“互联互通”,但是需要有平台相关的细节来保证实现,这个就是libc++abi和libsupc++的存在的原因。这里是一个非官方的libsupc++的网页: libsupc++ 我想找一找官方的网页看看,这个是官方的libstdc++v3的网页,我在gcc/libstdc++-v3/doc/html下面看到的就是这个文件。
x86_64-pc-linux-gnu/libstdc++-v3/,很明显的它是平台相关的,而且我的configure选项--enable-static --disable-shared要求它编译为静态库,我可以找到我需要的symbol: 所以,我今天解决了一个如何编译gcc版本的c++ABI的静态库的简单问题,不过不幸的是不能像llvm的libc++abi.a可以单独编译,目前我只能在整个gcc编译过程中编译它。现在就实验一下链接看看如何。结果还是一样,就是说我至少证明了我使用gcc-10.2.0原生的libstdc++库的__cxa_demangle依然无法正确的解析之前的这个复杂的lambda的mangled name,有机会我实验一下gcc-11看看。
三月二日 等待变化等待机会
值得注意的是stdc++只在繁体中文环境下有测试,甚至于香港的英文环境也有,这一点是让人遗憾的。此外这里提到的测试如果以上locale不满足就会失败也是一个头疼的问题,但是貌似如果安装了所有的locale也是可以的。If the 'gnu' locale model is being used, the following locales are used and tested in the libstdc++ testsuites. The first column is the name of the locale, the second is the character set it is expected to use.
de_DE ISO-8859-1 de_DE@euro ISO-8859-15 en_GB ISO-8859-1 en_HK ISO-8859-1 en_PH ISO-8859-1 en_US ISO-8859-1 en_US.ISO-8859-1 ISO-8859-1 en_US.ISO-8859-15 ISO-8859-15 en_US.UTF-8 UTF-8 es_ES ISO-8859-1 es_MX ISO-8859-1 fr_FR ISO-8859-1 fr_FR@euro ISO-8859-15 is_IS UTF-8 it_IT ISO-8859-1 ja_JP.eucjp EUC-JP ru_RU.ISO-8859-5 ISO-8859-5 ru_RU.UTF-8 UTF-8 se_NO.UTF-8 UTF-8 ta_IN UTF-8 zh_TW BIG5
Table 3.1. C++ Command Options比如那个exception-free的版本,因为据说
Option Flags Description -std=c++98or-std=c++03Use the 1998 ISO C++ standard plus amendments. -std=gnu++98or-std=gnu++03As directly above, with GNU extensions. -std=c++11Use the 2011 ISO C++ standard. -std=gnu++11As directly above, with GNU extensions. -std=c++14Use the 2014 ISO C++ standard. -std=gnu++14As directly above, with GNU extensions.
Option Flags Description -fexceptionsSee exception-free dialect -frttiAs above, but RTTI-free dialect. -pthreadFor ISO C++11 <thread>,<future>,<mutex>, or<condition_variable>.-latomicLinking to libatomicis required for some uses of ISO C++11<atomic>.-lstdc++fsLinking to libstdc++fsis required for use of the Filesystem library extensions in<experimental/filesystem>.-fopenmpFor parallel mode. -ltbbLinking to tbb (Thread Building Blocks) is required for use of the Parallel Standard Algorithms and execution policies in <execution>.
On recent hardware with GNU system software of the same age, the combined code and data size overhead for enabling exception handling is around 7%.对于怎么抑制异常处理使用这样子的宏还是挺聪明的做法,当然对于宏专家是不值一提,只不过我很难想到
if(true)这样子的语句,因为违反习惯
#if __cpp_exceptions # define __try try # define __catch(X) catch(X) # define __throw_exception_again throw #else # define __try if (true) # define __catch(X) if (false) # define __throw_exception_again #endif
可是我们明明印象中有一个参数是char的overloading啊,不过它是声明在抽象类__ctype_abstract_base,而且它根本就是一个内部实现类These are available in the C++98 compilation mode, i.e.
-std=c++98or-std=gnu++98. Unless specified otherwise below, they are also available in later modes (C++11, C++14 etc).Table 3.2. C++ 1998 Library Headers
algorithmbitsetcomplexdequeexceptionfstreamfunctionaliomanipiosiosfwdiostreamistreamiteratorlimitslistlocalemapmemorynewnumericostreamqueuesetsstreamstackstdexceptstreambufstringutilitytypeinfovalarrayvector- Table 3.3. C++ 1998 Library Headers for C Library Facilities
cassertcerrnocctypecfloatciso646climitsclocalecmathcsetjmpcsignalcstdargcstddefcstdiocstdlibcstringctimecwcharcwctype- The following header is deprecated and might be removed from a future C++ standard.
Table 3.4. C++ 1998 Deprecated Library Heade
strstream- 世纪曙光初现,c++
十年磨一剑在沉寂十多年后的的飞跃迎来了c++11These are available in C++11 compilation mode, i.e.
-std=c++11or-std=gnu++11. Including these headers in C++98/03 mode may result in compilation errors. Unless specified otherwise below, they are also available in later modes (C++14 etc).Table 3.5. C++ 2011 Library Headers
arrayatomicchronocodecvtcondition_variableforward_listfutureinitalizer_listmutexrandomratioregexscoped_allocatorsystem_errorthreadtupletypeindextype_traitsunordered_mapunordered_setTable 3.6. C++ 2011 Library Headers for C Library Facilities
ccomplexcfenvcinttypescstdaligncstdboolcstdintctgmathcuchar- 经过了c++11的大跨越,c++14仿佛是一个小小的停顿与休整,这样的休整是必要的不单单开发者需要一个整理维护的间隔期,用户也需要一个时期的咀嚼与吞咽,休息是为了更好的跨越。
This is available in C++14 compilation mode, i.e.
-std=c++14or-std=gnu++14. Including this header in C++98/03 mode or C++11 will not result in compilation errors, but will not define anything. Unless specified otherwise below, it is also available in later modes (C++17 etc).Table 3.7. C++ 2014 Library Header
shared_mutex- 在经历了c++14的短暂的休整之后c++17果然迎来了又一个大的跨越,注意这里没有c语言对应的,要知道c语言相映c++似乎成为一个很稳定的语言了,仿佛上个世纪初经典物理发展到了顶峰时候,巨匠们对于它的要求一样:把物理常数测的更加精准一些就可以了,所以c语言也是进入了一个半休眠期。
These are available in C++17 compilation mode, i.e.
-std=c++17or-std=gnu++17. Including these headers in earlier modes will not result in compilation errors, but will not define anything. Unless specified otherwise below, they are also available in later modes (C++20 etc).- Table 3.8. C++ 2017 Library Headers
anycharconvexecutionfilesystemmemory_resourceoptionalstring_viewvariant- 照例说经过c++17的比较大的跨越c++20似乎应该也是做一个短暂的休整,然而不是的,c++20似乎比c++17还要大的突破,难道说c++语言近年来有一种加速发展的趋势?实际上c++20远不止这些因为到目前为止c++20还是一个现在进行式,仅仅是早期收获而已,这里的内容不一定准确。
These are available in C++2a compilation mode, i.e.
-std=c++2aor-std=gnu++2a. Including these headers in earlier modes will not result in compilation errors, but will not define anything.- Table 3.9. C++ 2020 Library Headers
bitversion- The following headers have been removed in the C++2a working draft. They are still available when using this implementation, but in future they might start to produce warnings or errors when included in C++2a mode. Programs that intend to be portable should not include them. Table 3.10. C++ 2020 Obsolete Headers
ccomplexciso646cstdaligncstdboolctgmath- 这里我自己起名叫做
c++11外传因为它是自从c++98开始就一直徘徊着想要登入c++家族的大门,但是出于种种原因,它们成为了偏房始终不给名份最后在一个所谓的TR/TS的文字游戏中消磨了青春,直到近些年才转正。Table 3.11, “File System TS Header”, shows the additional include file define by the File System Technical Specification, ISO/IEC TS 18822. This is available in C++11 and later compilation modes. Including this header in earlier modes will not result in compilation errors, but will not define anything.
- Table 3.11. File System TS Header
experimental/filesystem- 如果说文件系统是一个
通房丫鬟那么这些TS的主力就是小妾了,它们的待遇确实很不公平。Table 3.12, “Library Fundamentals TS Headers”, shows the additional include files define by the C++ Extensions for Library Fundamentals Technical Specification, ISO/IEC TS 19568. These are available in C++14 and later compilation modes. Including these headers in earlier modes will not result in compilation errors, but will not define anything.
- Table 3.12. Library Fundamentals TS Headers
experimental/algorithmexperimental/anyexperimental/arrayexperimental/chronoexperimental/dequeexperimental/forward_listexperimental/functionalexperimental/iteratorexperimental/listexperimental/mapexperimental/memoryexperimental/memory_resourceexperimental/numericexperimental/optionalexperimental/propagate_constexperimental/randomexperimental/ratioexperimental/regexexperimental/setexperimental/source_locationexperimental/stringexperimental/string_viewexperimental/system_errorexperimental/tupleexperimental/type_traitsexperimental/unordered_mapexperimental/unordered_setexperimental/utilityexperimental/vector- 如果说TS还算是修成了正果的
偏房那么TR连小妾都不如的外室怎么也看不到有一天能够被收编的希望呢?至少也不可能全体,偶尔的零星半点的被暗渡陈仓而已。In addition, TR1 includes as:
- Table 3.13. C++ TR 1 Library Headers
tr1/arraytr1/complextr1/memorytr1/functionaltr1/randomtr1/regextr1/tupletr1/type_traitstr1/unordered_maptr1/unordered_settr1/utility- Table 3.14. C++ TR 1 Library Headers for C Library Facilities
tr1/ccomplextr1/cfenvtr1/cfloattr1/cmathtr1/cinttypestr1/climitstr1/cstdargtr1/cstdbooltr1/cstdinttr1/cstdiotr1/cstdlibtr1/ctgmathtr1/ctimetr1/cwchartr1/cwctype- Decimal floating-point arithmetic is available if the C++ compiler supports scalar decimal floating-point types defined via
__attribute__((mode(SD|DD|LD))).Table 3.15. C++ TR 24733 Decimal Floating-Point Header
decimal/decimal- 说完了TS/TR这些
怨妇就开始很少人问津的ABI了,这个实在是很偏门,我也是最近才听说是用来打印类型名字,对于c++更像是某种艳遇吧- 那么对于extension能说什么呢?我常常想这些是不是都是一些
秘而不宣的偷情史呢?And a large variety of extensions.
- Table 3.17. Extension Headers
ext/algorithmext/atomicity.hext/bitmap_allocator.hext/cast.hext/codecvt_specializations.hext/concurrence.hext/debug_allocator.hext/enc_filebuf.hext/extptr_allocator.hext/functionalext/iteratorext/malloc_allocator.hext/memoryext/mt_allocator.hext/new_allocator.hext/numericext/numeric_traits.hext/pb_ds/assoc_container.hext/pb_ds/priority_queue.hext/pod_char_traits.hext/pool_allocator.hext/rb_treeext/ropeext/slistext/stdio_filebuf.hext/stdio_sync_filebuf.hext/throw_allocator.hext/typelist.hext/type_traits.hext/vstring.h- Table 3.18. Extension Debug Headers
debug/arraydebug/bitsetdebug/dequedebug/forward_listdebug/listdebug/mapdebug/setdebug/stringdebug/unordered_mapdebug/unordered_setdebug/vectorTable 3.19. Extension Parallel Headers
parallel/algorithmparallel/numeric- 混合头文件是一个多么复杂的问题啊!我简直难以想象这个实现的可能的样子,比如一个c++98的
functional和c++11的array并列在一起会怎么样?文档里说混合是不可能的,所谓的泾渭分明,那么向后兼容的原则吗?不,新的取代旧的,就是说要使用array必须使用-std=c++11文档里最后一点就是TR1版本和正式版混合,比如tr1/type_traits和type_traits混合,我粗略看了看两个文件差别非常大,似乎前者是靠诸如SFINAE来实现的,而后者更多的靠的是编译器的进步吧?总之两者应该说是很不同的,居然放在一起没有事情,可见c++的维护工作量有多少。- c++风格的头文件名自然是一个基本的素养,我自信已经养成了习惯,只是背后的原因不甚了了。其实也很简单吧,就是保证了c++的所有函数都得到了std namespace的保护,而相似名称的c函数在global并不会冲突,而且使用很多std::xxx的c++版本的相应函数会收到更高的收益,比如模板化的适应全部类型参数的overloading。
- 关于precompiled header这个可能是对于我最大的帮助,因为我自己的precompiled header就包含了大部分的
stdc++.h里的头文件,但是在我目前的gcc安装机制只能使用这个目录<bits/stdc++.h>,因为这个是平台相关的目录x86_64-unknown-linux-gnu/bits/stdc++.h另外的两个头文件stdtr1c++.h和extc++.h我估计用到的可能性不大吧。- 其他关于namespace/macro以及linking都有些不得要领,似乎很简单没有什么值得记录的,但是总觉得有些不安。这里有提到freestanding似乎都是c语言的
- 这里谈到如何缩减string的内存占用尺寸,
std::string(str.data(), str.size()).swap(str);理解这行代码的妙处有佛手捻花而笑的感觉。三月三日 等待变化等待机会
- 在古老的文档里常常有一些很有趣的校注里面有些意外的收获,比如这里提到如何自己制作一个caseinsensitive的string呢?这个也算是
著名的题目了,是论坛里出现频率很高的,我模糊印象中几个月前我花了不少精力去研究现在都忘得一干二净了,唯一记得最好的解决方案是boost的locale,因为当时要考虑多字节语言的upper/lower是无意义的,但是貌似也是可以的吧?因为无所谓大小写就也可以,但是牵扯到排序还是需要引入locale,所以,这个问题完整的解决方案还是使用locale的相关函数比较字节,但是这个作者的方案对于西方语言是足够了。简而言之就是实现自己的char_traits,它和操作符==直接相关的就是compare方法,所以如果仅仅是实现它也算是一个投机的做法。 我看到了正确的实现方式在这里。当时我还是不太能够领悟。 至于说其他成员函数eq,le因为用不到就不实现了,我偶然google到了TR,标准委员会里对于一个小函数都有详细的论证。- 牵扯出的这个c++的网站www.gotw.ca貌似很不错的样子,以后再看吧。忍不住看了一个
guru of week就被教训了 这个代码行吗?答案是行!This is a C++ feature… the code is valid and does exactly what it appears to do.这里的const起到了至关重要的作用,没有它是不行的!
Normally, a temporary object lasts only until the end of the full expression in which it appears. However, C++ deliberately specifies that binding a temporary object to a reference to const on the stack lengthens the lifetime of the temporary to the lifetime of the reference itself, and thus avoids what would otherwise be a common dangling-reference error. In the example above, the temporary returned by f() lives until the closing curly brace. (Note this only applies to stack-based references. It doesn’t work for references that are members of objects.)- 我才意识到libstdc++的篇幅是相当的大的因为它基本是一个迷你版的c++ standard library reference手册,不过这个不是废话吗?这个文档不是手册是什么呢?我是说很多平常很少遇到的问题这里是作为常见问答来回答的,比如这个关于iterator的问答。
- 问题:怎样打印iterator的地址?这样子是不行的:ostream::operator<<(iterator)
- 问题:如何清除iterator的引用?这样子是不行的: iterator = 0
- iterator = iterator_type();
- 问题:如何判断iterator还是指向有效数据?这样子是不行的:if (iterator)
- if (iterator != iterator_type())
- 我以前对于namespace std的敏感度不高,认为是天经地义的,现在才意识到很多的微妙的地方,尤其在c/c++混合的古早年代,这里global namespace和std namespace有着很多的陷阱,这里介绍的把std搀合进global的方法我还一时难以领会。唯一能看懂的是在用户的namespace里个别std namespace的函数变得
好像是global namespace里的函数,其中的用途也许是某些c语言的老手可以自由的替换掉c语言的函数为c++的函数,如果不用加前缀std::的话?- 这里提到的.gdbinit的设定我还从来没有试过,它提到的gdb文档看样子不错。 我做了一个简单的实验比如我定义个两个类来展示多态: Derived:public Base并且都实现一个虚方法int func(int);那么
Base* base=new Derived();我们打印base变量如何呢?在打开set print object on现在gdb可以(gdb) p /r *base $4 = (Derived) {= { _vptr.Base = 0x555555754d70 <vtable for Derived+16> }, <No data fields>} 认出base的真实类型是Derived然后ptype的输出证实了这一点这里又一个很有意思的地方我故意在定义类不使用(gdb) ptype type = /* real type = Derived */ struct Base { public: virtual int func(int); }class而是使用struct就是为了节省一个public关键字,结果ptype打印的时候还是替我加上了。 所以,我觉得这个.gdbinit还是挺有用的,决定采纳。set print pretty on set print object on set print static-members on set print vtbl on set print demangle on set demangle-style gnu-v3- 这里提到的设定gdb pretty-printer的方法已经过时了,就是说现代gdb都已经集成了这个Python了,怎么知道呢?这个却是花了我不少时间才明白,没有比较就没有伤害,你甚至不知道远古时代的痛苦怎么明白今天幸福生活的来之不易,所以,我终于发现可以直接info pretty-printer显示当前已经有安装的printer,同时如果你一定要load自己的python-pretty-printer的脚本可以直接 source your-python-pretty-printer-path,但是最最白痴的是我理解错误使用p /r vect结果以为pretty-printer不起作用,后来才意识到直接print vect才是使用的方式,print /r vect是不使用
pretty-printer的方式。真的是出洋相啊。三月四日 等待变化等待机会
char_type toupper(char_type __c) const { return this->do_toupper(__c); }这个事情我想我之前已经花时间去探寻这个原因了,可是进一步的问题是为什么这样子就可以呢?
std::transform(p_str.begin(), p_str.end(), p_str.begin(), [](char c){return std::toupper(c);});注意到我们调用的是同样的std::toupper而其中的参数是char,这里的解释是什么呢?
Note that these calls all involve the global C locale through the use of the C functions toupper/tolower.
就是说它们是global namespace里的c版本toupper其中隐含的把char转换为int的过程,
Note that using explicit也就是说静态链接-static -lasan是走不通的,至少我的尝试是这样的,它需要dl/pthread,最后还是卡在了一个宏DYNAMIC的未定义上,与是我就放弃了。-lasanoption has been widely discouraged by ASan developers (e.g. here) as it misses some other important linker flags. The only recommended way to link is to use-fsanitize=address.
阿三是一个很不简单的库,目前我还没有精力去折腾它。
${var#Pattern} Remove from $var the shortest part of $Pattern that matches the front end of $var.${var##Pattern} Remove from $var the longest part of $Pattern that matches the front end of $var.
${var%Pattern} Remove from $var the shortest part of $Pattern that matches the back end of $var.${var%%Pattern} Remove from $var the longest part of $Pattern that matches the back end of $var.
另一个很漂亮的做法是依赖于一个不能自定义delimiter的做法,我模糊印象中我曾经研究过这个机制但是已经记不清了,重新看代码发现这个是异常的复杂完全不可能用户自定义实现的。
这一段代码的strtokenize的能力来源于哪里呢?究竟这个operator>>是哪一个类的呢?我找了很久我认为是basic_streambuf(文件istreambuf)的一个friend函数
这个函数在文件istream.tcc,我目前对于c++ std lib的实现文件类型还不明白,常常看到这类模板文件,它们是模板产生的源文件吗?
三月五日 等待变化等待机会
If the only functions from它是c++语言的基本支持部分的函数:libstdc++.awhich you need are language support functions (those listed in clause 18 of the standard, e.g.,newanddelete), then try linking againstlibsupc++.a, which is a subset oflibstdc++.a. (Using gcc instead of g++ and explicitly linking inlibsupc++.avia-lsupc++for the final link step will do it). This library contains only those support routines, one per object file. But if you are using anything from the rest of the library, such as IOStreams or vectors, then you'll still need pieces fromlibstdc++.a.
These fundamental types are always available, without having to include a header file. These types are exactly the same in either C++ or in C.
C++ has the following builtin types:这个是c++标准委员会制定的标准,那么查看limits文件里的注释有这么些说明
- char
- signed char
- unsigned char
- signed short
- signed int
- signed long
- unsigned short
- unsigned int
- unsigned long
- bool
- wchar_t
- float
- double
- long double
所以// The numeric_limits<> traits document implementation-defined aspects // of fundamental arithmetic data types (integers and floating points). // From Standard C++ point of view, there are 14 such types: // * integers // bool (1) // char, signed char, unsigned char, wchar_t (4) // short, unsigned short (2) // int, unsigned (2) // long, unsigned long (2) // // * floating points // float (1) // double (1) // long double (1) // // GNU C++ understands (where supported by the host C-library) // * integer // long long, unsigned long long (2)
long long, unsigned long long是GNU c++的对于基本类型的扩展支持。 但是实际上这个是不对的,因为最新的c++标准实际上还支持新的char8_t, char16_t, char32_t
The header比如struct numeric_limits<char>等等<limits>defines traits classes to give access to various implementation defined-aspects of the fundamental types. The traits classes -- fourteen in total -- are all specializations of the class templatenumeric_limits
简单的常数吗?可是
0L长度可就不一定和void*一样了。
The C++ 2011 standard added the nullptr keyword, which is a null pointer constant of a special type, std::nullptr_t. Values of this type can be implicitly converted to any pointer type, and cannot convert to integer types or be deduced as an integer type. Unless you need to be compatible with C++98/C++03 or C you should prefer to use nullptr instead of NULL.
对于像我这样子粗枝大叶的人一眼看过去还以为这个就是我们第一天学c++的所谓new ctor的语法,可是且住!你看到它返回值是和malloc一样的void*了吗?你看到它的参数是无类型的一个size_t了吗?你意识到它说的是这个global namespace里的
void* operator new(std::size_t);- Single object form. Throws
std::bad_allocon error. This is what most people are used to using.void* operator new(std::size_t, std::nothrow_t) noexcept;- Single object “nothrow” form. Calls
operator new(std::size_t)but if that throws, returns a null pointer instead.可以直接使用它的ctor比如std::nothrow_t{}void* operator new[](std::size_t);- Array
new. Callsoperator new(std::size_t)and so throwsstd::bad_allocon error.void* operator new[](std::size_t, std::nothrow_t) noexcept;- Array “nothrow”
new. Callsoperator new[](std::size_t)but if that throws, returns a null pointer instead.void* operator new(std::size_t, void*) noexcept;- Non-allocating, “
placement” single-objectnew, which does nothing except return its argument. 什么都不干?这个叫什么函数呢?这个和指针重新赋值有什么区别呢?难道这个是为了帮助自己实现在栈里模拟堆? This function cannot be replaced.什么叫做不能replaced?谁要镇么做?为什么要镇么做呢?void* operator new[](std::size_t, void*) noexcept;- Non-allocating, “placement” array
new, which also does nothing except return its argument. noexcept是什么时候才引入的关键字呢?这个是c++98就有的吗?我看到的是c++11才有的specifier,至于operator noexcept是另一码事。 This function cannot be replaced.
operator new了吗?你是这么分配内存的吗?
你是否和我一样的困惑void* p1= operator new(sizeof(int));//你是不是现在才意识到它说的是这个? delete (int*)p1; // 实际上我应该调用这个: operator delete(p1); // see below discussion! int* p2 = new int;//你是不是以为是这个? delete p2;
operator new(size_t)和operator new[](size_t)都是一样的需要一个参数怎么就能体现出array和普通的单个对象的区别呢?难道它们都是一个连续内存的分配为什么要两个不同的函数,相应的delete函数我需要两个形式吗?
连续内存,这个不是必要也不可能有那么大的内存,我记得实现层里有个技巧就是把array的个数写在地址开头处并且用链表来实现内存的多个块分配。
到这里我还没有看到明确列出的void*p3= operator new[](sizeof(int)*8); //operator delete(p3);//这个是会导致内存泄漏的调用 //delete (int*)p3; //这个会导致内存泄漏是asan报告的 //delete [](int*)p3; //你不需要告诉有几个元素,这些信息是保存在地址开头的部分的,这个不一定等价于下面的,但是下面的肯定是对的 opeerator delete[](p3); // 这个才是正确的调用形式!!!
delete的相对应的形式,但是我觉得这个已经是相当的复杂了,似乎超过了FAQ的期望了吧?实际上我很不自信我调用的是期待中的delete因为c++的类型是它的参数,而无法delete void*。所以再次祭起祖师的法宝RTFC在del_op.cc
_GLIBCXX_WEAK_DEFINITION void
operator delete(void* ptr) noexcept
{
std::free(ptr);
}
原生的
delete,而不是期待传递一个类型的c++的operator delete。最后我们知道所谓的delete在最底层的实现和c语言的free没有什么区别。
void*p3= operator new[](sizeof(int)*8); operator delete(p1);
abort就是直接退出不像exit会呼叫atexit注册的函数以及释放static allocated object in reversed oder。不过你可以注册自己的
- the abort() function does not call the destructors of automatic nor static objects,... The functions registered with atexit() don't get called either
- The good old exit() function ... 1) Static objects are destroyed in reverse order of their creation. 2) Functions registered with atexit() are called in reverse order of registration, once per registration call. 3) The previous two actions are “interleaved,”
- atexit() is only required to store 32 functions...recommend using the xatexit/xexit combination from libiberty, which has no such limit.
If you are having difficulty with uncaught exceptions and want a little bit of help debugging the causes of the core dumps, you can make use of a GNU extension, the verbose terminate handler.它的过程是
The __verbose_terminate_handler function obtains the name of the current exception, attempts to demangle it, and prints it to stderr. If the exception is derived from std::exception then the output from what() will be included.它的代码在vterminate.cc的确是如此,值得注意的是
Any replacement termination function is required to kill the program without returning; this one calls std::abort.看到这里我才豁然开朗原来abort实际上就是简单raise一个SIGABRT的signal而已。这里就是操作系统一个简单的常识性的概念,一个进程通常并不会自然而然的结束,因为并不像是一个函数结束运行就结束一样吧?正像这个进程不会自然而然开始运行一样的,是操作系统的机制使用fork/exec开始当然也需要类似的机制来kill它,
三月六日 等待变化等待机会
No compiler support for language c++.我一开始怀疑是路径的问题,但是显然的2016年是一个遥远的时代,我的gcc/gdb的版本应该早就要支持了。这里有人建议重新编译新版gdb,这个也许是一个好主意。但是具体编译的时候我有些小犹豫,因为官方的repo给人的印象是和binutils相关的这一点和gcc类似,难道我要下载编译整个binutils吗?我也不想这么安装啊?最后我还是去官网下载发行包编译,这里似乎更加的让人好理解,就是和gcc类似的多个stage编译但是每个stage对于binutils的依赖其实是有限的只是需要一些很少的几个命令而已,而且这个是编译过程需要而已并不是运行期的依赖,所以这个是令人放心的。
三段论,我不知道要怎么称呼它们,比如我自己编译的
x86_64-pc-linux-gnu,我模模糊糊记得gcc编译准备脚本configure里有相关的猜测探测的代码,但是这个实在是很烦人,有时候是PC,有时候是unknown,而gnu似乎也不是很重要,这个真的是很让人抓狂。其次,在gdb里实际上是呼叫libcc1.so的接口
gcc_c_fe_context_function/gcc_cp_fe_context_function前者是c编译器,后者是c++编译器,它们是libcc1.so我一直还以为有一个对应的libcp1.so因为源代码有这样的文件,但是动态库二者合而为一了。
我之所以看gcc下面的libcc1的代码会糊涂是因为没有想到它的设计是这样子的。通常你得到了这个libcc1.so的入口获得了所谓的context你以为就可以直接操作gcc得到你所需要的运行结果,我就是这样天真的想的结果把自己搞糊涂了,因为这个所谓的接口根本就没有能力做你想像的事情。这个和人间的现象很像似,民间常常有所谓自称手眼通天能够接近大人物的神棍招摇撞骗打着大旗当作虎皮,我们这些凡人以为它们是显贵$ objdump -CT /usr/lib/gcc/x86_64-linux-gnu/7/libcc1.so |grep gcc_c 000000000000a260 g DF .text 0000000000000054 Base gcc_cp_fe_context 0000000000006890 g DF .text 0000000000000054 Base gcc_c_fe_context
身边的红人自然就是能够帮我们办事,于是对他们顶礼膜拜孝敬有加,归根结底问题就出在它们那个
名号上,凭着libcc1.so的名头想想看cc1是什么来历,那不就是编译器了吗?那么它身边的
护卫难道不能给我们办事吗?其实不能,因为gcc/g++确实是一个很庞大的系统确实没有办法如通常的软件那样轻易做到我们想像中的功能,这一点上LLVM拥趸们并没有错。我看了不少时间才明白libcc1只不过是一个
门房,就是一个注册回调函数的接口,它本身能够帮你的就是
传话,比如第一步他要做一个很搞笑的事情,现在想来才明白我对于名头的错判,比如作为
皇上身边的带刀侍卫,它却不确定皇上在哪里!不要以为一个libcc1.so就对应一个版本的gcc/g++,实际上它是一个通用的接口基本上固定不变的,所以它需要在PATH环境变量里的所有路径下按照用户给定的triplet来查找gcc/g++,找到之后他要做的是开一个
socketpair,我还是第一次听说这个函数,但是它的作用应该很容易猜到就是一个pipe的应用吧很久很久以前我用过的unix socket应该就是这个东西吧?,让gcc/g++在那一头执行把结果从这个pipe传回来而已。这里关键的是它的参数让我恍然大悟
-fplugin=libcp1plugin以及参数-fplugin-arg-libcp1plugin-fd=%d这里的%d是unix socket的file descriptor。原来这个libcc1.so依赖的是libcc1plugin/libcp1plugin,这对兄弟才是真正的
内卫,只有它们才能
通天,那个
门房只是帮我们
传话罢了。到这里我们才明白是怎么回事:如果你要使用特定的编译器就直接调用libcp1plugin好了,gdb之所以使用libcc1.so的原因是它不确定用户要使用那个编译器,给了用户指定任意编译器的灵活度。
Target Triplets describe a platform on which code runs and are a core concept in the GNU build system. They contain three fields: the name of the CPU family/model, the vendor, and the operating system name. You can view the unambiguous target triplet for your current system by running:所以我的结果是gcc -dumpmachine
x86_64-linux-gnu所以,machine-vendor-operatingsystem
'pc' for 32-bit x86 systems ... 'unknown' or 'none' for other systems ...since the vendor field is mostly unused, the GNU build system allows you to leave out the vendor field比如
x86_64-freebsd
The build system will then automatically deduce that the vendor is the default (unknown)...Note that parsing target triplets are a bit more tricky, as sometimes the operating system field can be two fields:
x86_64-unknown-linux-gnu这里才是我需要的答案:那个unknown指的是vendor而我们一般根本不关心,而引起混乱的是后面的操作系统部分是由两个字组成的linux-gnu
This gets a bit worse since the vendor field can be left out:
x86_64-linux-gnu我完全同意作者的说法
This is most definitely ambiguous.
但是这一段话我理解有困难,这个是什么意思呢?
- Build Platform: This is the platform on which the compilation tools are executed.
- Host Platform: This is the platform on which the code will eventually run.
- Target Platform: If this is a compiler, this is the platform that the compiler will generate code for.
这里是代表什么呢?我决定不再追究这个也许仅仅是为了方便交流并不是什么定式吧?This means that up to three differently-targeted compilers might be in play (if you are building a GCC on platform A, which will run on platform B, which produces executables for platform C). This problem is solved by simply prefixing the compilation tools with the target triplet. When you build a cross-compiler, the installed executables will be prefixed with the specified target triplet:
i686-elf-gcc
三月七日 等待变化等待机会
set follow-fork-mode child
cat source.cpp|xclip -selection clipboard或者这样子xclip -selection clipboard -in source.cpp-fplugin=/path/to/name.ext是给出动态库的路径,这里我强调动态库因为它使用dl,所以,静态库是不可能的,当然了几乎没有人会有这种莫名其妙的想法。gcc -print-file-name=plugin在我的系统里就是/usr/lib/gcc/x86_64-linux-gnu/7/plugin而gcc的路径在哪里呢?
gcc -print-file-name=gcc
结果看得比较不清楚:
/usr/lib/gcc/x86_64-linux-gnu/7/../../../../lib/gcc
这个路径让我比较意外,我们使用tree来看看目录结构吧:
tree -d /usr/lib/gcc/x86_64-linux-gnu/7/../../../../lib/gcc
/usr/lib/gcc/x86_64-linux-gnu/7/../../../../lib/gcc
├── i686-linux-gnu
│ └── 8
└── x86_64-linux-gnu
├── 7
│ ├── include
│ │ ├── cilk
│ │ └── sanitizer
│ ├── include-fixed
│ └── plugin
├── 7.5.0 -> 7
└── 8
所以这里的gcc根目录可能是所有的toolchain都安装的地方,不同的版本,不同的triplet的gcc的标准安装目录,而不是所谓的which gcc的当前操作系统创建的symlink的路径。那么当前的gcc安装在哪一个路径呢?如果参数为空的话就返回了当前gcc的路径
gcc -print-file-name=
/usr/lib/gcc/x86_64-linux-gnu/7/
find `gcc -print-file-name=` -maxdepth 1 -type f -executable
/usr/lib/gcc/x86_64-linux-gnu/7/collect2
/usr/lib/gcc/x86_64-linux-gnu/7/lto-wrapper
/usr/lib/gcc/x86_64-linux-gnu/7/cc1
/usr/lib/gcc/x86_64-linux-gnu/7/cc1plus
/usr/lib/gcc/x86_64-linux-gnu/7/lto1
三月八日 等待变化等待机会
plugin_is_GPL_compatible另一个是plugin_init函数。这里有一个细节就是windows下的GetProcAddress是返回一个函数指针所以省却了很多cast的麻烦,可是在linux的dlsym返回的是一个void*指针,对于前者根本没有人关心plugin_is_GPL_compatible到底是什么类型或者值几何,因为只要这个symbol存在就可以了,gcc根本也没有在dlsym里取用这个值而是仅仅看看dlsym返回不是NULL就行了。但是对于plugin_init是要使用的,那么这里就是一个有意思的地方了。注解里说ISO C forbids assignment between function pointer and 'void *',那么你要怎么才能把这个void*强制转化为函数指针呢?这里的戏法就是用一个union类型包含了void*和我们需要强制转化的plugin_init的函数指针,与是首先在dlsym时候返回的void*先赋值给我们union里的void*,然后再把它的函数指针给我们的plugin_init函数指针变量来调用。这个真的是用心良苦啊!所以,一个最基本的plugin需要至少以上这两个symbol都定义了。这里有必要再复习一下dlerror的用意,它类似于getlasterror的意思,是在我们地用dlopen/dlsym之后的必要的检查。
plugin-version.h看到它是这么定义的
#include "configargs.h"
#define GCCPLUGIN_VERSION_MAJOR 10
#define GCCPLUGIN_VERSION_MINOR 2
#define GCCPLUGIN_VERSION_PATCHLEVEL 0
#define GCCPLUGIN_VERSION (GCCPLUGIN_VERSION_MAJOR*1000 + GCCPLUGIN_VERSION_MINOR)
static char basever[] = "10.2.0";
static char datestamp[] = "20200723";
static char devphase[] = "";
static char revision[] = "";
/* FIXME plugins: We should make the version information more precise.
One way to do is to add a checksum. */
static struct plugin_gcc_version gcc_version = {basever, datestamp,
devphase, revision,
configuration_arguments};
这个设置导致gcc-plugin.h必然是和这个
plugin-version.h是在同一个目录下的,所以,我觉得传递参数的时候使用这个头文件里定义的最为科学,虽然没有强制力。我想说的是plugin的加载方是使用当前gcc的版本号就是这个plugin-version.h里定义的
gcc_version。总之一个简单的初始化函数搞了我一个下午还没有完全掌握!
The version of GCC used to compile the plugin can be found in the symbol gcc_version defined in the header plugin-version.h.,唉,我还是没有仔细读文档自己瞎折腾,当然了文档里并没有告诉我全部,我可能还是要自己找到其余的部分。这句话里的陈述也不是很清楚,虽然版本几乎没有什么用,但是这里的编译plugin是
有意让读者糊涂的说法,你编译你的plugin,你自己并不会使用这个gcc_version,这个参数是你要挂载的目标gcc使用的plugin loader的代码,是它把当前目标gcc的这个版本参数传递给你作为plugin的plugin_init函数,这个参数你爱用不用,实在是无所谓的东西。 我觉得我在这个版本的trivial的问题上浪费了太多的时间了,毫无意义!
event类型结果我在代码里搜了半天居然没有找到它们是怎么定义的,后来才发现是定义在一个
plugin.def的文件里的,这是一个文件后缀不是.h的头文件!这个真的让人无语!为什么定义一个symbol不使用头文件呢?
enum plugin_event
{
# define DEFEVENT(NAME) NAME,
# include "plugin.def"
# undef DEFEVENT
PLUGIN_EVENT_FIRST_DYNAMIC
};
stringify一类的宏,比如
#define GCC_PLUGIN_STRINGIFY0(X) #X,不使用头文件定义一个symbol是为了什么呢?我对于宏产生的literal不太熟悉,我猜想是不是这样子定义不用产生类型和symbol在二进制码吗?至少目前我是在cc1等里看不到,这个是因为定义宏的缘故吗?
三月九日 等待变化等待机会
struct plugin_name_args
{
char *base_name; /* Short name of the plugin
(filename without .so suffix). */
const char *full_name; /* Path to the plugin as specified with
-fplugin=. */
int argc; /* Number of arguments specified with
-fplugin-arg-.... */
struct plugin_argument *argv; /* Array of ARGC key-value pairs. */
const char *version; /* Version string provided by plugin. */
const char *help; /* Help string provided by plugin. */
};
这个看来说明了gcc-plugin对于版本敏感的一个原因吧?看来我还是错的。这个c++filt看来是很cute的东西!c++filt _ZN17gcc_rich_location8add_exprEP9tree_nodeP11range_label gcc_rich_location::add_expr(tree_node*, range_label*)
/* The prototype for a plugin callback function.
gcc_data - event-specific data provided by GCC
user_data - plugin-specific data provided by the plug-in. */
typedef void (*plugin_callback_func)(void *gcc_data, void *user_data);
其中的user_data是用户注册plugin的时候register_callback传入的参数,这里的一个小细节是针对不同的plugin event实际上并不是user_data都是用户自定义的,对于PLUGIN_PASS_MANAGER_SETUP来说这个一定是register_pass_info,也正因为这个你才可以传递一个栈里的临时变量,因为register_pass知道怎么使用这个
user_data,自然的对于其他event,这个void*的指针肯定是要保证生命周期的了。仿佛在应证我的
发现这里是文档的标准答案
For the PLUGIN_PASS_MANAGER_SETUP, PLUGIN_INFO, and PLUGIN_REGISTER_GGC_ROOTS pseudo-events thecallbackshould be null, and theuser_datais specific.
三月十日 等待变化等待机会
make RUNTESTFLAGS="dg.exp=diagnostic_plugin_show_trees.c" check-gccmake check-gcc RUNTESTFLAGS="plugin.exp",就是说check-gcc指明了目标目录,然后参数plugin.exp指明了运行的driver
cpp_callbacks *cb = cpp_get_callbacks (parse_in);
cb->comment = my_comment_cb;
-fno-diagnostics-show-caret -fno-diagnostics-show-line-numbers -fdiagnostics-color=never -fdiagnostics-urls=never测试例有很多值得学习的东西,查看运行log是我下一步的工作了。三月十一日 等待变化等待机会
The compiler driver program runs one or more of the subprograms cpp, cc1, as and ld. It tries prefix as a prefix for each program it tries to run, both with and without machine/version/ for the corresponding target machine and compiler version.当然了可执行程序一定最后会在PATH路径里搜索这个是必然的。
那么stat mylink 文件:mylink -> dir 大小:3 块:0 IO 块:4096 符号链接 ...
这就是为什么gcc在处理目录前全部都加上/.后缀的原因。stat mylink/. 文件:mylink/. 大小:4096 块:8 IO 块:4096 目录 ...
调教的?而且居然有linux版本的安装,肯定有很多不足,但是应该是有一个很好的起步了。这个是下载中心。
三月十二日 等待变化等待机会
看到这样的代码是不是如我一样要崩溃了?这样子的理由对于gcc里成千上万的变量来说哪一个不可以有呢?/* The global singleton context aka "g". (the name is chosen to be easy to type in a debugger). */ extern gcc::context *g;
diagnostic_starter (global_dc) = test_diagnostic_starter;肯定是设定回调函数,可是天知道这个diagnostic_starter是何方神圣?如果我告诉你global_dc可以猜出来是global variable的diagnostic_context的话,你能猜出来diagnostic_starter是什么东西呢?居然是一个宏!#define diagnostic_starter(DC) (DC)->begin_diagnostic简直是让人无语了。更让人无语的是同样的回调函数的定义里,既然定义了宏给begin_diagnostic为什么不给start_span定义呢?为什么会有如下的代码存在呢?
global_dc->start_span = test_diagnostic_start_span_fn;
我唯一的解释就是这个工程是众多程序员长年累月的积累,中间某些程序员的个人习惯或者是突发奇想的结果吧?每个人其实都会做这样的事情,不过就是因为团体的强制约束防止发生才防止出现,没有了团体的约束这个是必然的结果。
/* DK_UNSPECIFIED must be first so it has a value of zero. We never assign this kind to an actual diagnostic, we only use this in variables that can hold a kind, to mean they have yet to have a kind specified. I.e. they're uninitialized. Within the diagnostic machinery, this kind also means "don't change the existing kind", meaning "no change is specified". */ DEFINE_DIAGNOSTIC_KIND (DK_UNSPECIFIED, "", NULL) /* If a diagnostic is set to DK_IGNORED, it won't get reported at all. This is used by the diagnostic machinery when it wants to disable a diagnostic without disabling the option which causes it. */ DEFINE_DIAGNOSTIC_KIND (DK_IGNORED, "", NULL) /* The remainder are real diagnostic types. */ DEFINE_DIAGNOSTIC_KIND (DK_FATAL, "fatal error: ", "error") DEFINE_DIAGNOSTIC_KIND (DK_ICE, "internal compiler error: ", "error") DEFINE_DIAGNOSTIC_KIND (DK_ERROR, "error: ", "error") DEFINE_DIAGNOSTIC_KIND (DK_SORRY, "sorry, unimplemented: ", "error") DEFINE_DIAGNOSTIC_KIND (DK_WARNING, "warning: ", "warning") DEFINE_DIAGNOSTIC_KIND (DK_ANACHRONISM, "anachronism: ", "warning") DEFINE_DIAGNOSTIC_KIND (DK_NOTE, "note: ", "note") DEFINE_DIAGNOSTIC_KIND (DK_DEBUG, "debug: ", "note") /* For use when using the diagnostic_show_locus machinery to show a range of events within a path. */ DEFINE_DIAGNOSTIC_KIND (DK_DIAGNOSTIC_PATH, "path: ", "path") /* These two would be re-classified as DK_WARNING or DK_ERROR, so the prefix does not matter. */ DEFINE_DIAGNOSTIC_KIND (DK_PEDWARN, "pedwarn: ", NULL) DEFINE_DIAGNOSTIC_KIND (DK_PERMERROR, "permerror: ", NULL) /* This one is just for counting DK_WARNING promoted to DK_ERROR due to -Werror and -Werror=warning. */ DEFINE_DIAGNOSTIC_KIND (DK_WERROR, "error: ", NULL) /* This is like DK_ICE, but backtrace is not printed. Used in the driver when reporting fatal signal in the compiler. */ DEFINE_DIAGNOSTIC_KIND (DK_ICE_NOBT, "internal compiler error: ", "error")
The purpose of GENERIC is simply to provide a language-independent way of representing an entire function in trees....If you can express it with the codes in gcc/tree.def, it's GENERIC.
/* Generated automatically. */
static const char configuration_arguments[] = "../gcc-10.2.0/configure CFLAGS='-ggdb3 -O0' CXXFLAGS='-ggdb3 -O0' LDFLAGS=-ggdb3 --prefix=/home/nick/Downloads/gcc-10.2.0/gcc-10.2.0-install --disable-bootstrap --disable-multilib --enable-languages=c++ --enable-gcc-debug";
static const char thread_model[] = "posix";
static const struct {
const char *name, *value;
} configure_default_options[] = { { "cpu", "generic" }, { "arch", "x86-64" } };
三月十三日 等待变化等待机会
窥探的工具普通人是极其难以了解其中的奥秘,哪怕管中窥豹都近乎不可能。但是这个工具似乎不是那么完善吧?或者我的理解还有偏差,比如我想使用PLUGIN_INCLUDE_FILE事件来查看到底有多少include文件被打开结果似乎很让人费解。我本身已经使用了precompiled-header然后再使用stdc++.h这样子的标准库的所谓的precompiled-header,这样子会怎样呢?首先,似乎这个事件对于precompiled-header是无效的,众多的包含的头文件并没有引发事件,其次,stdc++.h似乎是引发了一个built-in的头文件名字,这个很奇怪啊。还有就是gcc -v揭示了很多我没有意识到的问题
x86_64-unknown-linux-gnu,这个很可能是configure自动侦测无法判断vendor的通常结果吧?这个是所有的gcc的固定的搜索路径吗?因为我自己编译的tripet不像官方版本而是x86_64-unknown-linux-gnu而作为对比的官方版本的tripet才是
x86_64-linux-gnu找到了可能的原因了因为官方版本的配置是强制使用前缀的--program-prefix=x86_64-linux-gnu-,这个也许和tripet无关吧?
include路径是必然要被走索的
忽略重复的目录“/home/nick/opt/gcc-10.2.0/include/c++/10.2.0” 因为它是一个重复了系统目录的非系统目录
这个只能说明""是用户定义的高于系统的<>定义的路径,其中的细节还是很多的不清楚。我印象中看过这部分的相关代码,结果还是不清楚。我现在的感觉是用户定义的-I也是放在了这个#include "..." search starts here: #include <...> search starts here:
系统的搜索路径的最前面,不过这部分c++标准不具体规定是各个编译器自己实现的所以没有什么普遍意义。
bits/stdc++.h出现的。
cpp_reader的全局变量的file_change这个callback里来呼叫的。那么就全都取决于cpp/libcpp的调用自己的这个回调函数的机制了。然后作为English Programmer我找到了如下的注释解释了我的疑惑
看来问题解决了。/* Called when switching to/from a new file. The line_map is for the new file. It is NULL if there is no new file. (In C this happens when done with <built-in>+<command line> and also when done with a main file.) This can be used for resource cleanup. */
#include "cpplib.h"后总是出现这个编译错误# error "Cannot find a least-32-bit signed integer type",一开始我误以为是我需要包含特别的头文件,最后经过了很多盲目的尝试才意识到这个问题的根本原因是这个头文件本身定义的。它的核心是这个directive的问题:
这个directive要求我们定义CHAR_BIT所以必须包含#if CHAR_BIT * SIZEOF_INT >= 32 # define CPPCHAR_SIGNED_T int #elif CHAR_BIT * SIZEOF_LONG >= 32 # define CPPCHAR_SIGNED_T long #else # error "Cannot find a least-32-bit signed integer type" #endif
glimits.h和 SIZEOF_INT这个要求包含
auto-host.h。其次就是对于头文件
line-map.h的一些定义的问题,它要求我们包含
ansidecl.h和
libiberty.h。至此编译过程可以了,下面是链接的问题了,libcpp.a是肯定的,其次就是libiberty.a。此外还需要。。。libcommon.a和libbacktrace.a,当然了链接的时候必须使用linking flag-static来强制静态链接。 这过程中阅读这个帖子有很多的帮助,当然我的问题不是那么简单。
cpp_reader* parse_in=cpp_create_reader(CLK_CXX2A, nullptr, nullptr);并不代表初始化的成功,因为没有设定正确的参数之前呼叫const char* ptr=cpp_read_main_file(parse_in, "/home/nick/eclipse-2021/cppTest/src/cppTest.cpp");是不会成功的,而这个正是我现在在探索的问题,为了方便debug我决定编译debug版本的libcpp:--enable-cpp-debug不知道这个开关是否是正确的?我是从--enable-gcc-debug推理出来的。三月十五日 等待变化等待机会
driver遇到了困难因为libbackend.a是一个
think archive,我隐约记得这个东西表示它的很多的symbol本身就像一个软链接一样的吧?搜索了一个
不明觉厉的帖子。这个可能是死路一条?
急救章的解决过程,表面上看似乎部分工作,但是深层次的问题也许还是存在的。
thin archive重新编译,这个例子很好的解决了这个问题。因为所谓的
thin archive就是
incremental的编译的过程吧?所以,这个足够了。
ar -t libbackend.a | xargs ar -rvs libbackend_real.a,这么做的一个直接坏处就是我的这个静态库爆增到超过一个G!register_include_chains(parse_in, nullptr, nullptr, nullptr, 1, 1, 1);
这里我采用verbose结果打印出类似的编译器的内置路径ignoring nonexistent directory "/home/nick/Downloads/gcc-10.2.0/gcc-10.2.0-debug-libcpp-install/lib/gcc/x86_64-pc-linux-gnu/10.2.0/../../../../x86_64-pc-linux-gnu/include"
#include "..." search starts here:
#include <...> search starts here:
/home/nick/Downloads/gcc-10.2.0/gcc-10.2.0-debug-libcpp-install/lib/gcc/x86_64-pc-linux-gnu/10.2.0/../../../../include/c++/10.2.0
/home/nick/Downloads/gcc-10.2.0/gcc-10.2.0-debug-libcpp-install/lib/gcc/x86_64-pc-linux-gnu/10.2.0/../../../../include/c++/10.2.0/x86_64-pc-linux-gnu
/home/nick/Downloads/gcc-10.2.0/gcc-10.2.0-debug-libcpp-install/lib/gcc/x86_64-pc-linux-gnu/10.2.0/../../../../include/c++/10.2.0/backward
/home/nick/Downloads/gcc-10.2.0/gcc-10.2.0-debug-libcpp-install/lib/gcc/x86_64-pc-linux-gnu/10.2.0/include
/usr/local/include
/home/nick/Downloads/gcc-10.2.0/gcc-10.2.0-debug-libcpp-install/include
/home/nick/Downloads/gcc-10.2.0/gcc-10.2.0-debug-libcpp-install/lib/gcc/x86_64-pc-linux-gnu/10.2.0/include-fixed
/usr/include
End of search list.const cpp_token*token=NULL;
token=cpp_get_token(parse_in);
while (token){
cout<<cpp_token_as_text(parse_in, token)<<endl;
token=cpp_get_token(parse_in);
}O Romeo, Romeo, wherefore art thou Romeo?我的coredump在哪里?我决定摘录如下:
/proc/sys/kernel/core_pattern/usr/share/apport/apport %p %s %c %d %P %E~/.config/apport/settings拥有如下内容
但是这样子有一个缺点就是core的文件名不会变化就是core导致覆盖,也是好事也是坏事,总之不占空间是好事,我以前系统崩溃就是无数的coredump耗尽磁盘空间而不自知。[main] unpackaged=true
executable does not belong to a package, ignoring
三月十六日 等待变化等待机会
typedef bool (*printer_fn) (pretty_printer *, text_info *, const char *, int, bool, bool, bool, bool *, const char **);,但是编译错误说
error: typedef 'printer_fn' is initialized (use decltype instead)这个挺让人困惑的吧,其实关键的问题是这里的类型
pretty_printer没有定义结果编译器不把它当作是typedef而是猜测你是在初始化什么东西,或者是定义一个返回类型之类的,总之,这个是非常的误导人的。一个简单的解决办法是forward declare: class pretty_printer;
diagnostic.h,但是包含这个头文件会引发很多的问题,首先,必须先包含system.h和coretypes.h而且它们的顺序很重要的。而且system.h不能出现在任何c++的通常的头文件比如iostream等等之前
nm --debug-syms libexample.a通过查看
For debugger symbols the second column indicates N.
libcpp/location-example.txt是非常的难懂。我对于简单的location_t还不明了就更不用提rich_location_t了。
sysroot的意义实际上就是在默认搜索路径
/usr/include所增加的前缀使之成为
sysroot/usr/include这个是对应于编译gcc的安装目录configure里的prefix吧?这么简单我却不理解以为是文件名的前缀。而第二个参数
iprefix才是我理解的前缀,比如gcc默认会有两个目录include和include-fixed它们会被添加前缀iprefixinclude和iprefixinclude-fiexed,而第三个参数imultipath,实际上是gcc默认的第三个搜索路径的后缀,比如我们总是看到这个看似无用的路径
lib/gcc/x86_64-pc-linux-gnu/10.2.0/../../../../x86_64-pc-linux-gnu/include,而这个imultipath就是加在这个路径的后缀。
char*path=strdup("/tmp");
add_path(path, INC_QUOTE, 1, 1);token->type!=CPP_EOF这么简单我费了一个下午!register_include_chains(parse_in, nullptr, nullptr, nullptr, 1, 1, 1);const char* ptr=cpp_read_main_file(parse_in, "/tmp/test.c");cpp_init_builtins(parse_in, 1);cpp_callbacks*pCallback=cpp_get_callbacks(parse_in);pCallback->diagnostic=cb_diagnostic;cpp_set_callbacks(parse_in, pCallback);-I/[gcc-installed-path]/lib/gcc/[gcc-triplet i.e. x86_64-pc-linux-gnu]/[gcc-version i.e. 10.2.0]/plugin/include需要链接这些静态库
libcpp.a libincpath.a libcommon-target.a libcommon.a libbacktrace.a libiberty.a,这里的顺序很重要,而且libincpath.a是一个我自己造出来的静态库:
ar -t gcc/libincpath.a incpath.o cppdefault.o options.o prefix.o主要原因是libbackend.a是一个所谓的"thin archive",我无法正常去链接所以只能自己制作
ar -rvs libincpath.a incpath.o cppdefault.o options.o prefix.o
看来如果我不留下笔记过一个星期我肯定就忘记怎么重新制作这个project了。 三月十七日 等待变化等待机会
caret/start/finish等等的复杂的给用户的提示。总之,我注意到LLVM的这个caret指示不对,这是让我感到欣慰的:他们也未必搞得非常清楚吧?
cpp_warning_reason是CPP_W_NONE的话,是不会当作错误来计算的。此外我终于意识到了在location小于所谓的BUILTINS_LOCATION的时候输出的头文件是被赋予这个特殊的头衔<built-in>这个就是我之前观察到的
原生头文件的输出。而这个所谓的BUILTINS_LOCATION是被定义为1的,并不是我一开始以为的0.
line_maps的传入参数,我想当然的就自己创建了一个,后来才发现这个必须使用line_table这个全局指针变量,但是初始化却是要你自己完成,这个做法是相当古老的,我一开始看到所谓的genmatch里可以自己创建以为就是可以的,现在回过头来看这个名字很有可能是一些内部测试使用的东西吧?总之解决了这个问题之后我就可以在回调函数里把location_t用linemap_client_expand_location_to_spelling_point转为expanded_location了。
持剑人是否有承担毁灭地球70%以上人口的历史责任的决心问题。如果三体人不是依赖
智子从长期对
圣母婊程心的长期观察判断得出她绝无可能按下核按钮的话,怎么可能敢于在
罗辑仅仅把控制器交给
程心才十分钟就发起攻击?对于领导人性格意志的观察分析是决定中美未来冲突策率的根本依据,而爆发于未来的战争起始于今天,就是现在!在武力统一台湾或者武装占领钓鱼岛的过程中,美国核潜艇偷袭中国海军的六艘航母中的任何一艘,那么中国是否敢于使用东风导弹打击美国的航母?也许有,也许没有。但是假如并没有任何美国航母在东风导弹的射程范围内的话,打击美国某个军事基地是否能够得上
对等报复?这个行为是否可以被美国认定为如伊朗使用导弹打击美国驻伊拉克的空军基地一样的仅有象征性意义呢?是否这一冲突可以在随后的外交谈判中化解并最终导致台湾和钓鱼岛的历史地位被固定化?这个可以说是美国计划中的最好的剧本。兵法有云:弱不能守,强不能久。这里指的就是作为对弈中的较弱的中方必须要采取进攻的战略才能达到防守的目的;而作为较强的美方时时刻刻都应该明白作为实力暂时居优的一方的时间已经不多了,如果不今早发起战略决战迟早会被中方逆转大局。那么如果一定要爆发冲突最好在美军还占有较大优势的时候爆发,既然要打,那不如大打,那不如打核战争。
不胜与
不败的分寸。在对弈双方中的强势一方几乎没有人敢于主动追求
不胜;而与之相对应的是弱势的一方几乎没有人不愿意把追求
不败作为最高目标的。有实力获得全胜而予以放弃转而求其次满足于
不胜,不但国君不能答应,己方的将士也视之为无能与怯懦。而相对应的看似不可能取得胜利,能够以自保就是最好的运气的弱势一方,如果最高目标超过了
不败没有人不会认为是不自量力的自杀送死的想法的。所以,强势的一方不敢追求
不胜,弱势的一方不得不追求
不败。而若不能守要求的是弱势一方不能满足于
不败,要在战略相持阶段到来之前就打出外线去反攻,这个就是在1947年毛泽东要求刘邓挺进中原时候走的险棋。而
强不能久的一方如果制定的战略是以
不胜为目标的话,他的优势迟早会在完全达到目标前就消失,所以,从来
不胜即为失败。所以,蒋介石如果在1947年底就把关外精锐的新一军新六军调入关内以绝对优势兵力解决华东的话,国民政府绝对可以保有长江以南全部和长江以北的大部版土,但是东北的全部丢失给共产党之后。即便倾全国之力也不可能剿灭东北的共产党政权。此为
不胜之策,断然没有决策者愿意采纳。是故强有所不甘,弱有所不敢。
不胜之策留有胜之余味,为强者所不甘愿也。而
不败之策有一厢情愿的意味,为弱者所不敢希望也。
bluffing的博弈游戏。美苏双方都拥有足以毁灭对方好几次的核武器,而双方的博弈焦点就在于让对方决策者相信自己有决心使用互相摧毁的手段来达到自己的战略目的,而彼此之间的反复试探和努力一方面是做出准备使用核武器的架势,另一方面加强领导人坚毅决心的外在形像的演示,其目的都是不过营造一个让对方相信己方虚张声势的氛围。称其为
讹诈的战争一点也不为过。彼此对于对方手中的牌一清二楚却又将信将疑,自欺欺人的揣摩对方领导人揣摩自己心理的各种剧本,也就是《三体》中的那个
猜疑链。 如果用中文来转述的话,也许是这样子的:
中方认为美方认为中方在虚张声势,而美方认为中方认为美方在虚张声势。中方的虚张声势的目的是要让美方明白在中方没有虚张声势的时候的的确确是没有虚张声势,或者中方确实在虚张声势的时候要让美方觉得中方并没有虚张声势。而在中方看来美方的虚张声势一定就是虚张声势,因为美国如果没有虚张声势的话,那么美方的的确确是没有虚张声势,所以说美方的确是没有虚张声势。这里的逻辑非常的复杂,而中文并没有一个与英文bluffing完全一致内涵的对等的词,而其中的假命题的否定之否定让人头脑发昏了。总之,中美双方究竟谁在虚张声势呢?也许都没有,也许都有,也许只有一方有,无外乎就是这几种组合罢了。
convert input.gif -rotate 90 out.gif/usr/include/x86_64-pc-linux-gnu这个x86_64-pc-linux-gnu不是multilib,而是target,multilib是所谓的后缀吧?就是在文件名之后加上的?我找到了gcc的权威文档,现在看起来才有些理解,似乎我只有实践过了才能理解一点点,所以,我对于主席的《实践论》是比较推崇的,一切的真知都来源于实践。
在我的情况target是x86_64-pc-linux-gnu,而version是10.2.0,而这里的libdir并不是#include <file>in:/usr/local/include libdir/gcc/target/version/include /usr/target/include /usr/includeFor C++ programs, it will also look in libdir/../include/c++/version In the above, target is the canonical name of the system GCC was configured to compile code for; often but not always the same as the canonical name of the system it runs on. version is the version of GCC in use.
lib64,而是lib虽然我的系统是64位,但是lib作为兼容32位,或者因为multilib的因素吧,总而言之,lib才是正确的libdir,我模糊记得redhat/fedora似乎不是这样子吧?我不确定。总之,现在对于搜索路径有了更清晰的认识了。
You can add to this list with the -Idir command line option. All the directories named by -I are searched, in left-to-right order, before the default directories. The only exception is when dir is already searched by default. In this case, the option is ignored and the search order for system directories remains unchanged.这里告诉我们什么呢?-I拥有最高的优先级!但是cpp究竟怎么运行的没有明显的输出方式,我的plugin只能输出用户程序的include,对于系统的头文件并不能被调用,所以,依旧只能去看代码才知道。而这个正是我的libcpp需要知道的逻辑。所以,今天的全部就卡在这里了。
GCC looks for headers requested with所以顺序是#include "file"first in the directory containing the current file, then in the directories as specified by -iquote options, then in the same places it would have looked for a header requested with angle brackets. For example, if /usr/include/sys/stat.h contains#include "types.h", GCC looks for types.h first in /usr/include/sys, then in its usual search path.
本地,-iquote,尖挂号。天哪!我以为-iquote意思就是-I""!不是的!它是替代已经过时的-I-。我要崩溃了!
三月十八日 等待变化等待机会
gnu/stubs-32.h这类的系统头文件不会触发missing header之类的错误了,但是其中的逻辑代码的寻找就不那么明显。一开始我是在搜索其中的错误回调函数,我找到了这个专门处理的回调
missing_header,它给了我一条线索,但是它的调用的场景非常有限,libcpp的逻辑是只有当正常搜索不到的时候才调用这个用户可以自定义的回调,逻辑是所谓的
exhaust搜索才返回。所以这个函数是所有逻辑的集合点_cpp_find_file
enum include_type
{
/* Directive-based including mechanisms. */
IT_INCLUDE, /* #include */
IT_INCLUDE_NEXT, /* #include_next */
IT_IMPORT, /* #import */
/* Non-directive including mechanisms. */
IT_CMDLINE, /* -include */
IT_DEFAULT, /* forced header */
IT_MAIN, /* main */
IT_DIRECTIVE_HWM = IT_IMPORT + 1, /* Directives below this. */
IT_HEADER_HWM = IT_DEFAULT + 1 /* Header files below this. */
};
-include,-imacro在所谓的cpp的cwd路径,而
#include_next顾名思义要跳到下一个,这个是GNU的扩展,非常的独门。
gcc -x c++ /dev/null -dM -E注意这里-x是强制指定语言的开关,所以这里并不需要直接使用g++就能够指定输出c++相关的宏。这里提到ISO不提倡定义这些头尾没有__的宏,这个我还真的没有概念,总之现在知道一个内建的宏很可能一个变三个在cpp里。Pass an object-like macro. If it doesn't lie in the user's namespace, defines it unconditionally. Otherwise define a version with two leading underscores, and another version with two leading and trailing underscores, and define the original only if an ISO standard was not nominated. e.g. passing "unix" defines "__unix", "__unix__" and possibly "unix". Passing "_mips" defines "__mips", "__mips__" and possibly "_mips".
三月十九日 等待变化等待机会
cpp -dM /dev/null输出的宏依样画葫芦传递给我的libcpp结果依然出错在tbb/tbb.h。怎么办呢?只好再用gdb跟踪吧?/* Although this file must not go in the cache, because the file found might depend on things (like the current file) that aren't represented in the cache, it still has to go in the list of all files so that #import works. */所以,我并不需要特别处理就应该可以,那么我出了什么错呢?我再gdb我自己的libcpp发现回调函数missing_header里我使用cout输出就导致gdb跟踪无法继续,也许这个就是根源?去掉之后似乎正确跳过了missing_header的错误,但是最后还是coredump然后我gdb core之后看到bt里是所谓的一个convert_escape的空指针crash了,这是怎么回事呢? 经过艰苦的gdb过程发现需要先初始化cpp_init_iconv否则charset conversion的函数指针没有初始化,这个的确是一个让人感到有些意外的地方,我始终感觉对于charset这个概念是模糊的,其中既包含代码和可执行码的这两个方面。其中代码的charset是比较复杂的,这个牵涉到各种literal的翻译问题,比如我遇到的crash就是在翻译escape的时候无所适从而崩溃的,虽然我的编码是utf-8已经设定过了,可是相关的转换函数的初始化就是这个函数的作用。我不由得再次感叹gcc整个系统里最简单的预处理就是这么的复杂,那么后面部分呢?以前编译器课程的教授说过编译器实现的95%的难读在于代码产生部分因为所有的优化都发生在那里,那么这剩下的不到5%的部分里预处理又是少之又少的部分,那么。。。我只能仰天长叹。
故知胜有五:知可以战与不可以战者胜;识众寡之用者胜;上下同欲者胜;以虞待不虞者胜;将能而君不御者胜。此五者,知胜之道也。知易行难,作为统帅怎么能够判断出
知可以战与不可以战呢?你怎么知道你依赖的幕僚确实知道呢?我以为就是要依赖算法与实验来验证,运用兵棋推演并把兵棋推演结果做近似实战化进行验证。决策者不需要也不可能知道实现的细节,但是要知道验证的逻辑与原理并亲眼验证验证过程本身的可靠性。陪审员不需要法官的法律专业知识技能,但是必须具有凭常识判断证据可信度以及因果逻辑关系正确性的能力。从孙子的这五个要素来看,中美较量中方并不可能在任何四个领域占优,在我看来中方唯一的优势就只有一条:上下同欲。这恐怕是中方唯一的优势,因为在其他四个领域里美方都不见得比中方弱,甚至有先发的优势而占优。
你们没有资格在中国的面前说,你们从实力的地位出发同中国谈话。多么的霸气侧漏啊!这句中文要怎么翻译啊?什么叫做从实力的地位出发?中国不承认美国的一超地位了吗?这次聚会是否相当于渑池之会呢?对于
秦王侮辱
赵王鼓瑟时候蔺相如
五步之内,相如可以刎颈以血溅大王!
探针的工具,尽管是多么的不足。怎样解决各种编译cpplib.h的各个函数,以及随后的链接都是大事,尤其是在众多的静态库里找到你需要的库,而且那个libbackend.a是一个thin archive逼迫你自己制作一个库,静态库的顺序依赖看来是轻而易举的事,可是在七八年前对于我来说就算是一个大成就了。
长征不是难堪日,战锦方为大问题。
开关对于我来说还是不容易的。
很容易被中国造出来的根本原因是因为你知道原子弹是一定可以造出来的,没有比在黑暗里摸索不确定的可能性更难的了,而具体实现已知可行的路径反倒是容易的了。当然
knowing the path和walking the path是两个截然不同的难度也是对的,没有
Oracle的话
Neo是不会敢于正面硬钢Agents的。
POSIX.1-2008. These functions are not specified in POSIX.1-2001, and are not widely available on other systems.?我不明白这个到底是什么时候问世的,怎么没有人通知我呢? 这里我为了适应cpp_output_token需要的file stream,我想把结果输出在内存里处理,所以,这个是我能够想到的办法,本来想用stringstream,可是要怎么模拟FILE*呢?似乎没有显而易见的办法吧?不过这个方法有些不可靠,因为如果要保留一个个的token,你要拷贝一个个的string,保存buffer的指针偏移肯定是不行的,天知道有没有在内部使用了realloc,所以,这个方法实在是很笨拙,我还想不出来什么好办法。或者牺牲效率,就每次都调用新的open_memstream,这个节省一些内存吧?实际上使用cpp_spell_token就解决了这个问题。
三月二十日 等待变化等待机会
static const struct cpp_operator
{
uchar prio;
uchar flags;
} optab[] =
{
/* EQ */ {0, 0}, /* Shouldn't happen. */
/* NOT */ {16, NO_L_OPERAND},
/* GREATER */ {12, LEFT_ASSOC | CHECK_PROMOTION},
/* LESS */ {12, LEFT_ASSOC | CHECK_PROMOTION},
/* PLUS */ {14, LEFT_ASSOC | CHECK_PROMOTION},
/* MINUS */ {14, LEFT_ASSOC | CHECK_PROMOTION},
/* MULT */ {15, LEFT_ASSOC | CHECK_PROMOTION},
/* DIV */ {15, LEFT_ASSOC | CHECK_PROMOTION},
/* MOD */ {15, LEFT_ASSOC | CHECK_PROMOTION},
/* AND */ {9, LEFT_ASSOC | CHECK_PROMOTION},
/* OR */ {7, LEFT_ASSOC | CHECK_PROMOTION},
/* XOR */ {8, LEFT_ASSOC | CHECK_PROMOTION},
/* RSHIFT */ {13, LEFT_ASSOC},
/* LSHIFT */ {13, LEFT_ASSOC},
/* COMPL */ {16, NO_L_OPERAND},
/* AND_AND */ {6, LEFT_ASSOC},
/* OR_OR */ {5, LEFT_ASSOC},
/* Note that QUERY, COLON, and COMMA must have the same precedence.
However, there are some special cases for these in reduce(). */
/* QUERY */ {4, 0},
/* COLON */ {4, LEFT_ASSOC | CHECK_PROMOTION},
/* COMMA */ {4, LEFT_ASSOC},
/* OPEN_PAREN */ {1, NO_L_OPERAND},
/* CLOSE_PAREN */ {0, 0},
/* EOF */ {0, 0},
/* EQ_EQ */ {11, LEFT_ASSOC},
/* NOT_EQ */ {11, LEFT_ASSOC},
/* GREATER_EQ */ {12, LEFT_ASSOC | CHECK_PROMOTION},
/* LESS_EQ */ {12, LEFT_ASSOC | CHECK_PROMOTION},
/* UPLUS */ {16, NO_L_OPERAND},
/* UMINUS */ {16, NO_L_OPERAND}
};
Precedence Operator Description Associativity 1 ::Scope resolution Left-to-right 2 a++a--Suffix/postfix increment and decrement type()type{}Functional cast a()Function call a[]Subscript .->Member access 3 ++a--aPrefix increment and decrement Right-to-left +a-aUnary plus and minus !~Logical NOT and bitwise NOT (type)C-style cast *aIndirection (dereference) &aAddress-of sizeofSize-of[note 1] co_awaitawait-expression (C++20) newnew[]Dynamic memory allocation deletedelete[]Dynamic memory deallocation 4 .*->*Pointer-to-member Left-to-right 5 a*ba/ba%bMultiplication, division, and remainder 6 a+ba-bAddition and subtraction 7 <<>>Bitwise left shift and right shift 8 <=>Three-way comparison operator (since C++20) 9 <<=For relational operators < and ≤ respectively >>=For relational operators > and ≥ respectively 10 ==!=For equality operators = and ≠ respectively 11 &Bitwise AND 12 ^Bitwise XOR (exclusive or) 13 |Bitwise OR (inclusive or) 14 &&Logical AND 15 ||Logical OR 16 a?b:cTernary conditional[note 2] Right-to-left throwthrow operator co_yieldyield-expression (C++20) =Direct assignment (provided by default for C++ classes) +=-=Compound assignment by sum and difference *=/=%=Compound assignment by product, quotient, and remainder <<=>>=Compound assignment by bitwise left shift and right shift &=^=|=Compound assignment by bitwise AND, XOR, and OR 17 ,Comma Left-to-right
孪生兄弟cpp_spell_token就是我要找的函数,所以完全没有必要使用什么open_memstream。值得注意的是cpp_spell_token是不能处理CPP_PADDING的,这个当然是可以理解的,你要打印空格你自己去打印吧。而且查看这个函数你就能理解很多的原理,比如怎样从hashnode转换,不过我不想了解这些细节。 其中的TOKEN_NAME有些精心动魄因为我很少干这种宏的复杂的替换,尤其是重定义的宏,不过我是现学现卖把原本的TOKEN_NAME改造了一下拷贝过来的:
struct Token_Name
{
cpp_ttype t;
unsigned char* name;
};
#define OP(e, s) { CPP_##e, (unsigned char*) #s },
#define TK(e, s) { CPP_##e, (unsigned char*) #e },
static const struct Token_Name token_names[N_TTYPES] = { TTYPE_TABLE };
#undef OP
#undef TK
#define TOKEN_NAME(token) (token_names[(token)->type].name)
表,设计者当初就计划好了你灵活使用注解作为打印enum的办法,这个在c++的reflective能力有突破之前是唯一的办法。
#define TTYPE_TABLE \
OP(EQ, "=") \
OP(NOT, "!") \
OP(GREATER, ">") /* compare */ \
OP(LESS, "<") \
OP(PLUS, "+") /* math */ \
OP(MINUS, "-") \
OP(MULT, "*") \
OP(DIV, "/") \
OP(MOD, "%") \
OP(AND, "&") /* bit ops */ \
OP(OR, "|") \
OP(XOR, "^") \
OP(RSHIFT, ">>") \
OP(LSHIFT, "<<") \
\
OP(COMPL, "~") \
OP(AND_AND, "&&") /* logical */ \
OP(OR_OR, "||") \
OP(QUERY, "?") \
OP(COLON, ":") \
OP(COMMA, ",") /* grouping */ \
OP(OPEN_PAREN, "(") \
OP(CLOSE_PAREN, ")") \
TK(EOF, NONE) \
OP(EQ_EQ, "==") /* compare */ \
OP(NOT_EQ, "!=") \
OP(GREATER_EQ, ">=") \
OP(LESS_EQ, "<=") \
OP(SPACESHIP, "<=>") \
\
/* These two are unary + / - in preprocessor expressions. */ \
OP(PLUS_EQ, "+=") /* math */ \
OP(MINUS_EQ, "-=") \
\
OP(MULT_EQ, "*=") \
OP(DIV_EQ, "/=") \
OP(MOD_EQ, "%=") \
OP(AND_EQ, "&=") /* bit ops */ \
OP(OR_EQ, "|=") \
OP(XOR_EQ, "^=") \
OP(RSHIFT_EQ, ">>=") \
OP(LSHIFT_EQ, "<<=") \
/* Digraphs together, beginning with CPP_FIRST_DIGRAPH. */ \
OP(HASH, "#") /* digraphs */ \
OP(PASTE, "##") \
OP(OPEN_SQUARE, "[") \
OP(CLOSE_SQUARE, "]") \
OP(OPEN_BRACE, "{") \
OP(CLOSE_BRACE, "}") \
/* The remainder of the punctuation. Order is not significant. */ \
OP(SEMICOLON, ";") /* structure */ \
OP(ELLIPSIS, "...") \
OP(PLUS_PLUS, "++") /* increment */ \
OP(MINUS_MINUS, "--") \
OP(DEREF, "->") /* accessors */ \
OP(DOT, ".") \
OP(SCOPE, "::") \
OP(DEREF_STAR, "->*") \
OP(DOT_STAR, ".*") \
OP(ATSIGN, "@") /* used in Objective-C */ \
\
TK(NAME, IDENT) /* word */ \
TK(AT_NAME, IDENT) /* @word - Objective-C */ \
TK(NUMBER, LITERAL) /* 34_be+ta */ \
\
TK(CHAR, LITERAL) /* 'char' */ \
TK(WCHAR, LITERAL) /* L'char' */ \
TK(CHAR16, LITERAL) /* u'char' */ \
TK(CHAR32, LITERAL) /* U'char' */ \
TK(UTF8CHAR, LITERAL) /* u8'char' */ \
TK(OTHER, LITERAL) /* stray punctuation */ \
\
TK(STRING, LITERAL) /* "string" */ \
TK(WSTRING, LITERAL) /* L"string" */ \
TK(STRING16, LITERAL) /* u"string" */ \
TK(STRING32, LITERAL) /* U"string" */ \
TK(UTF8STRING, LITERAL) /* u8"string" */ \
TK(OBJC_STRING, LITERAL) /* @"string" - Objective-C */ \
TK(HEADER_NAME, LITERAL) /* <stdio.h> in #include */ \
\
TK(CHAR_USERDEF, LITERAL) /* 'char'_suffix - C++-0x */ \
TK(WCHAR_USERDEF, LITERAL) /* L'char'_suffix - C++-0x */ \
TK(CHAR16_USERDEF, LITERAL) /* u'char'_suffix - C++-0x */ \
TK(CHAR32_USERDEF, LITERAL) /* U'char'_suffix - C++-0x */ \
TK(UTF8CHAR_USERDEF, LITERAL) /* u8'char'_suffix - C++-0x */ \
TK(STRING_USERDEF, LITERAL) /* "string"_suffix - C++-0x */ \
TK(WSTRING_USERDEF, LITERAL) /* L"string"_suffix - C++-0x */ \
TK(STRING16_USERDEF, LITERAL) /* u"string"_suffix - C++-0x */ \
TK(STRING32_USERDEF, LITERAL) /* U"string"_suffix - C++-0x */ \
TK(UTF8STRING_USERDEF,LITERAL) /* u8"string"_suffix - C++-0x */ \
\
TK(COMMENT, LITERAL) /* Only if output comments. */ \
/* SPELL_LITERAL happens to DTRT. */ \
TK(MACRO_ARG, NONE) /* Macro argument. */ \
TK(PRAGMA, NONE) /* Only for deferred pragmas. */ \
TK(PRAGMA_EOL, NONE) /* End-of-line for deferred pragmas. */ \
TK(PADDING, NONE) /* Whitespace for -E. */
三月二十一日 等待变化等待机会
三月二十二日 等待变化等待机会
weak symbol,具体的说就是它首先被放在了.textsection的自己的section
template.h
template <typename T>
bool compare(T t1, T t2){
return t1<t2;;
}
template3.cpp
#include "template.h"
void test3(){
compare(23, 34);
compare<char>(5,7);
}
void test4(){
test3();
}
objdump -Ct template3.o
template3.o: file format elf64-x86-64
SYMBOL TABLE:
0000000000000000 l df *ABS* 0000000000000000 template3.cpp
0000000000000000 l d .text 0000000000000000 .text
0000000000000000 l d .data 0000000000000000 .data
0000000000000000 l d .bss 0000000000000000 .bss
0000000000000000 l d .text._Z7compareIiEbT_S0_ 0000000000000000 .text._Z7compareIiEbT_S0_
0000000000000000 l d .text._Z7compareIcEbT_S0_ 0000000000000000 .text._Z7compareIcEbT_S0_
0000000000000000 l d .note.GNU-stack 0000000000000000 .note.GNU-stack
0000000000000000 l d .eh_frame 0000000000000000 .eh_frame
0000000000000000 l d .comment 0000000000000000 .comment
0000000000000000 l d .group 0000000000000000 .group
0000000000000000 l d .group 0000000000000000 .group
0000000000000000 g F .text 0000000000000025 test3()
0000000000000000 w F .text._Z7compareIiEbT_S0_ 0000000000000015 bool compare<int>(int, int)
0000000000000000 w F .text._Z7compareIcEbT_S0_ 000000000000001a bool compare<char>(char, char)
0000000000000025 g F .text 000000000000000c test4()
.text._Z7compareIiEbT_S0_,这个可以很简单的就证实它和.text无关。另一个模板函数也是类似的就是它们都被标签weak symbol.
objdump -Ct --section=.text._Z7compareIiEbT_S0_ template3.o
template3.o: file format elf64-x86-64
SYMBOL TABLE:
0000000000000000 l d .text._Z7compareIiEbT_S0_ 0000000000000000 .text._Z7compareIiEbT_S0_
0000000000000000 w F .text._Z7compareIiEbT_S0_ 0000000000000015 bool compare<int>(int, int)
objdump -Ct --section=.text._Z7compareIcEbT_S0_ template3.o
template3.o: file format elf64-x86-64
SYMBOL TABLE:
0000000000000000 l d .text._Z7compareIcEbT_S0_ 0000000000000000 .text._Z7compareIcEbT_S0_
0000000000000000 w F .text._Z7compareIcEbT_S0_ 000000000000001a bool compare<char>(char, char)
A weak symbol denotes a specially annotated symbol during linking of Executable and Linkable Format (ELF) object files. By default, without any annotation, a symbol in an object file is strong. During linking, a strong symbol can override a weak symbol of the same name. In contrast, in the presence of two strong symbols by the same name, the linker resolves the symbol in favor of the first one found. This behavior allows an executable to override standard library functions, such as malloc(3). When linking a binary executable, a weakly declared symbol does not need a definition. In comparison, (by default) a declared strong symbol without a definition triggers an undefined symbol link error.怎么理解呢?
The weak function attribute is supposed to be used on function declarations. Using it on a function definition may yield unexpected results, depending on the compiler and optimization level.
__attribute__((weak)) void myfunc()
{}
strong(没有声明为weak就是strong)那么最后这个symbol它就是weak,不管顺序如何。比如我在
nick@nick-HP-Laptop:/tmp/temp$ cat weak.h
void myfunc() __attribute__((weak)) ;
nick@nick-HP-Laptop:/tmp/temp$ cat strong.h
void myfunc();
nick@nick-HP-Laptop:/tmp/temp$ cat myfunc.c
#include "weak.h"
#include "strong.h"// it doesn't matter even we change the order of include here
void myfunc()
{}
nick@nick-HP-Laptop:/tmp/temp$ gcc -c myfunc.c -o myfunc.o
nick@nick-HP-Laptop:/tmp/temp$ nm myfunc.o
0000000000000000 W myfunc
正常的(strong)也可以把它声明为weak的,取决于你编译这个实现的时候编译器看到的声明,所以这个时候
Using weak symbols in static libraries has other semantics than in shared ones, i.e. with a static library the symbol lookup stops at the first symbol – even if it is just weak and an object file with a strong symbol is also included in the library archive. On Linux, the linker option --whole-archive changes that behavior.
就是说一个symbol的声明在一个obj文件里是ODR,但是对于不同的obj文件就是链接的问题了,如果把不同的声明放在同一个静态库里就是灾难了!
先到先得,平起平坐。这里是全文的解读
On UNIX System V descendent systems, during program runtime the dynamic linker resolves weak symbols definitions like strong ones. For example, a binary is dynamically linked against libraries libfoo.so and libbar.so. libfoo defines symbol所以动态链接必须有环境变量LD_DYNAMIC_WEAK才能强制要求寻找strong symbol,但是lazy之类的就复杂了吧?fand declares it as weak. libbar also definesfand declares it as strong. Depending on the library ordering on the link command line (i.e.-lfoo -lbar) the dynamic linker uses the weak f from libfoo.so although a strong version is available at runtime. The GNUldprovides the environment variableLD_DYNAMIC_WEAKto provide weak semantics for the dynamic linker.
strong或者
weak的symbol,那么在链接的时候就有了优先级的差别。
nick@nick-HP-Laptop:/tmp/temp$ cat first.h
int myfunc() __attribute__((weak));
nick@nick-HP-Laptop:/tmp/temp$ cat first.c
#include "first.h"
int myfunc(){
return 1;
}
nick@nick-HP-Laptop:/tmp/temp$ cat call.c
#include "first.h"
int main(){
return myfunc();
}
nick@nick-HP-Laptop:/tmp/temp$ cat second.c
int myfunc(){
return 2;
}
nick@nick-HP-Laptop:/tmp/temp$ gcc -g -c first.c -o first.o
nick@nick-HP-Laptop:/tmp/temp$ gcc -g -c second.c -o second.o
nick@nick-HP-Laptop:/tmp/temp$ gcc -g -c call.c -o call.o
nick@nick-HP-Laptop:/tmp/temp$ nm first.o
0000000000000000 W myfunc
nick@nick-HP-Laptop:/tmp/temp$ nm second.o
0000000000000000 T myfunc
nick@nick-HP-Laptop:/tmp/temp$ nm call.o
U _GLOBAL_OFFSET_TABLE_
0000000000000000 T main
w myfunc
nick@nick-HP-Laptop:/tmp/temp$ gcc -g call.o first.o -o first.exe
nick@nick-HP-Laptop:/tmp/temp$ ./first.exe
nick@nick-HP-Laptop:/tmp/temp$ echo $?
1
nick@nick-HP-Laptop:/tmp/temp$ gcc -g call.o first.o second.o -o second.exe
nick@nick-HP-Laptop:/tmp/temp$ ./second.exe
nick@nick-HP-Laptop:/tmp/temp$ echo $?
2
三月二十三日 等待变化等待机会
$ cat call_no_definition.c
__attribute__((weak))int myfunc();
int main(){
return myfunc();
}
$ gcc call_no_definition.c -o call_no_definition.exe
$ nm call_no_definition.exe | grep myfunc
w myfunc
$ ./call_no_definition.exe
Segmentation fault (core dumped)
If this variable is set, it controls the video mode in which the Linux kernel starts up, replacing the ‘vga=’ boot option (see linux). It may be set to ‘text’ to force the Linux kernel to boot in normal text mode, ‘keep’ to preserve the graphics mode set using ‘gfxmode’, or any of the permitted values for ‘gfxmode’ to set a particular graphics mode (see gfxmode).者就对了,它实际上是影响kernel的参数vga= 但是继续看这里我又有些困惑,我应该不是32位的boot程序那么应该不需要直接设定set gfxpayload=1024x768之类的吧? 另一个差别在linux [kernel-file]
The partition table format traditionally used on PC BIOS platforms is called the Master Boot Record (MBR) format; this is the format that allows up to four primary partitions and additional logical partitions. With this partition table format, there are two ways to install GRUB: it can be embedded in the area between the MBR and the first partition (called by various names, such as the "boot track", "MBR gap", or "embedding area", and which is usually at least 31 KiB), or the core image can be installed in a file system and a list of the blocks that make it up can be stored in the first sector of that partition.所以第一种就明白了在512byte之后到32k之间,通常这个部分是不放东西的因为
on modern disks, it is often a performance advantage to align partitions on larger boundaries anyway, so the first partition might start 1 MiB from the start of the disk.这就对了,我曾经无数次的看到所谓的虚拟机,BMC等等的img都是这样子的分成前面32k大部分是空,然后真正的文件系统block有时候是的确从1M开始的。这个在fdisk里很容易验证。
所以文件系统的起始位置是在2048*512/1024=1024Kib=1Mib。所以,这句话sudo fdisk -l /dev/sda ... Units: sectors of 1 * 512 = 512 bytes ... Device Boot Start End Sectors Size Id Type /dev/sda1 * 2048 504104959 504102912 240.4G 83 Linux
the first partition might start 1 MiB from the start of the disk是对的。
Some newer systems use the GUID Partition Table (GPT) format. This was specified as part of the Extensible Firmware Interface (EFI), but it can also be used on BIOS platforms if system software supports it; for example, GRUB and GNU/Linux can be used in this configuration. With this format, it is possible to reserve a whole partition for GRUB, called the BIOS Boot Partition. GRUB can then be embedded into that partition without the risk of being overwritten by other software and without being contained in a filesystem which might move its blocks around.所以,以后安传如果使用GPT就会遇到了。
三月二十四日 等待变化等待机会
变量类型,比如typedef ReturnType(*FuncType)(ArgType...);这样子的话作为一个指针类型可以声明一个函数指针变量就能够随意使用了。但是假如你声明一个函数类型,它和指针类型也差不多,不过就是lvalue/rvalue之类的区别吧?但是有什么优势呢?以下代码是gcc的真实代码只不过为了保护隐私把结构和函数的参数省略了而已。Are you kidding me?其实这个在编译器不支持c++的年代人们幻想着有一种神奇的函数叫constructor或者有一种模式叫做factory。毕竟c++编译器是用c语言实现的,出现这个情况不值得大惊小怪的。
struct gcc_cp_context{}; //a struct. ok.
typedef struct gcc_cp_context *gcc_cp_fe_context_function();//a function type?!not pointer.
extern "C" gcc_cp_fe_context_function gcc_cp_fe_context;//a function variable?
extern "C" struct gcc_cp_context *gcc_cp_fe_context (){ //THE function.
return new gcc_cp_context;
}
#define GCC_CP_FE_CONTEXT gcc_cp_fe_context //why do you want this?
...you can declare a function to take a function as a parameter ..., and the effect is to make the parameter a function pointer. This is similar to the way you can declare a function parameter that looks like an array, but is actually a pointer.
The function argument can be the name of the function, with or without a
&to explicitly take its address. If you omit the&, then there's an implicit function-to-pointer conversion. Again, this is similar to passing a (pointer to) an array, where the implicit array-to-pointer conversion means you only need to write the array's name, rather than&array[0].
目标gt的文件名都是前缀gt然后是目录名然后是源文件名,比如gt-cp-class.c,这个做法是为了能够把众多的代码文件拷贝到同一个目录下编译吗?这个简直要把人逼疯了,这个是故意这么做的吗?
三月二十五日 等待变化等待机会
struct MyPoint{int x, y, z; string name};Point p{Anything{},Anything{},Anything{},Anything{}};undefined reference to `Anything::operator int<int>() const'当然对于最后一个成员变量string就是`Anything::operator int<string>() const',你当然可以在Anything里加上一个简单的实现就如被我注释的那样{return T();},可是对于复杂类型这个就不一定行了,而实际上我们不需要真的创建这么一个变量,因为我们仅仅需要这个Point的一个decltype比如 以下这个是可以的 尽管我们只给了两个参数给Point的ctor依然是成立的因为对于没有explicit的ctor这个类似于数组的Brace-enclosed initializers给几个参数都是可以的只要不超过。而且由于是decltype编译器根本不去实例化参数只是检查参数个数,所以
初始化部分,因为逗号,前面的是初始化,只有逗号,后面的Anthing{}才是唱主角的返回值。所以它等价于Point{Anthing{}};,何况
名门正派的Antything呢?这就是为什么这个类的模板函数operator T() const根本没有模板参数也可以因为编译器压根不关心!这里的核心是编译器只关心参数的个数比如 MyStruct只能接受一个参数因为它的成员变量就是一个,你给两个编译器就发现了,这里编译器是只做类似语法的检查,decltype/static_assert并不需要产生目标代码。 总而言之,作者就是利用了这个来检查类的成员变量的最大个数。
T{(void(Is), detail::Anything{})...};要怎么理解呢?这里的(,)...是什么神操作?我又一次想了好久才回忆起来以前就反复遇到过,...是Brace-enclosed initializers代表使用函数参数里的parameter pack来拓展(expand),至于说(,)这个是惯常的比如摘录这个例子在初始化数组的时候顺便打印每个值0
(void)0(+;) is a valid, but 'does-nothing' C++ expression, that's everything. It doesn't translate to theno-opinstruction of the target architecture, it's just an empty statement as placeholder whenever the language expects a complete statement... the(void)prevents it from being accidentally used as a value
万能的模板类。 然后再specialization的时候把index_sequence作为模板参数传递。我觉得这个和用模板函数传递它作为实参的效果似乎是异曲同工,总之index_sequence实际上是相当于实参而不是型参吧? 这里的using虽然是alias实际上和声明实例没有区别。 这里就是结果能够打印出来数组的成员
0,1,2,3,4,5,6,7,8,
三月二十六日 等待变化等待机会
类的初始化依靠大量的宏,这个是没有办法的办法,因为第一个c++的parser是依靠c实现的,这里都是c的代码,尽管后来有了新版的编译器可以实现这些也没有人愿意改动因为怕出错,而且我始终有一个担心就是使用最新的c++的feature去编译c++编译器是否是一个螺旋的错误,如果有某种很深藏的bug导致编译器有某种bug,而导致编译出来的编译器根本被隐藏了就永远发现不了了,因为很多时候我们测试是基于编译器的行为,有些测试是独立的第三方的是基于输入输出的,可是有些测试是基于新版编译器是否符合当前编译器的期待输出的,这个时候如果编译器本身就是错的那么结果怎么样呢?错上加错?这些接口定义在langhooks-def.h居然是一个头文件,真的是进步啊,昨天看到头条的文章有人惊叹居然c/c++的include可以引用任何类型的文件,这个明显是windows程序员的固疾因为被操作系统固化了思维的人会把文件类型和后缀名等同化的结果,一个人在某种体制下束缚太久就会形成惯性思维和路径依赖,这就是所谓的
天经地义理所当然的感想的由来,事物文件不以它们的外表或者说文件名来决定,而是由文件的内容决定的,这一点linux的工具file就是做这个工作的,可惜不是所有的应用都能够遵循这个原则,毕竟集成这个工具需要不少的力气而且他本身也没有办法做到那么完美。
common-xxx.c里,比如最重要的接口LANG_HOOKS_PARSE_FILE被c++hook定义为了c_common_parse_file这一点是让我花了不少时间才明白因为很多时候代码文件名字是会误导人的,比如cp-objcp-common.h我就误以为里面都是
objectiveC++的相关定义,所以当我只看到这里把这个接口LANG_HOOKS_PARSE_FILE定义为c_common_parse_file而找不到其他
gnu/c++的定义时候就让我感到惶恐了以为自己理解错误了。文件名不副实是一个gcc的大问题。 我要记录下这个parser的流程
#0 c_parse_file () at ../../gcc-10.2.0/gcc/cp/parser.c:43993
#1 0x0000000000c28c2c in c_common_parse_file () at ../../gcc-10.2.0/gcc/c-family/c-opts.c:1190
#2 0x000000000139cf47 in compile_file () at ../../gcc-10.2.0/gcc/toplev.c:458
#3 0x00000000013a01f2 in do_compile () at ../../gcc-10.2.0/gcc/toplev.c:2278
#4 0x00000000013a0500 in toplev::main (this=0x7fffffffdac6, argc=33, argv=0x7fffffffdbc8)
at ../../gcc-10.2.0/gcc/toplev.c:2417
#5 0x00000000022e4bbb in main (argc=33, argv=0x7fffffffdbc8) at ../../gcc-10.2.0/gcc/main.c:39
passes因为这个可能才是所有的逻辑算法的核心部分,它本身不是实现的部分,但是它是所有实现的总调度相关的部分,可能也是最变化多端的部分吧?我应该在到达它之前就远远的停下来。我的感觉是parsing仅仅是很小的一部分工作也许有可能把其中相关的文件找出来,但愿gcc不像llvm的支持者说的那么不堪,我现在对于这些人的言论是半信半疑的。
三月二十七日 等待变化等待机会
genmodes.c实际就是一个小的可执行程序作为工具使用一个
machmode.def作为输入产生新的代码头文件和代码文件,这也就是很多时候我死活找不到一些函数的定义的原因。其实这个简单的事情我早应该想到了,比如在编译路径下为什么会有那么多的.c/.h文件呢?不是编译时候产生的难道是拷贝来的?这个不是显而易见的吗?所以gcc的困难不是普通程序员所能想像的,对于很多以为天经地义的事情在编译器的实现阶段是一个未知数。
垂而不死不知道在多少时间后在匪夷所思的地方
炸尸还魂,这才是让人揪心。
将不胜其忿而蚁附之,杀士三分之一而城不拔者,此攻之灾也。目前的局势就是美国在逼迫中国尽快在台湾问题上摊牌,能否有足够的时间去准备即将到来的不可避免的战争的决定必须在现在做出。
major, minor, patchlevel
cpp_define_formatted (pfile, "__GNUC__=%d", major);
cpp_define_formatted (pfile, "__GNUC_MINOR__=%d", minor);
cpp_define_formatted (pfile, "__GNUC_PATCHLEVEL__=%d", patchlevel);
cpp_define_formatted (pfile, "__VERSION__=\"%s\"", version_string);
const char version_string[] = BASEVER DATESTAMP DEVPHASE REVISION;memory model我很陌生
cpp_define_formatted (pfile, "__ATOMIC_RELAXED=%d", MEMMODEL_RELAXED);
cpp_define_formatted (pfile, "__ATOMIC_SEQ_CST=%d", MEMMODEL_SEQ_CST);
cpp_define_formatted (pfile, "__ATOMIC_ACQUIRE=%d", MEMMODEL_ACQUIRE);
cpp_define_formatted (pfile, "__ATOMIC_RELEASE=%d", MEMMODEL_RELEASE);
cpp_define_formatted (pfile, "__ATOMIC_ACQ_REL=%d", MEMMODEL_ACQ_REL);
cpp_define_formatted (pfile, "__ATOMIC_CONSUME=%d", MEMMODEL_CONSUME);
define_builtin_macros_for_compilation_flags (pfile);
define_builtin_macros_for_lp64 (pfile);
define_builtin_macros_for_type_sizes (pfile);cpp_force_token_locations (parse_in, BUILTINS_LOCATION);是什么用意呢?是说明这些设定的宏cpp_define都是不属于任何文件的而是builtin的?而随后的类似的<command-line>是添加用户定义的宏就是-D, -U,-A这个最后的
自问自答的功能是很强大的,你可以询问cpp问题,它就cpp_assert那个宏回答你。真的是很神奇。
三月二十八日 等待变化等待机会
c_compile_file的所有的需求。首先我注意到libcpp的链接需求,这里有一个困惑我很久的疑问就是它在gcc编译过程中有两个编译的版本,一个在源代码的libcpp下,一个在目标机器的build-x86_64-pc-linux-gnu下,二进制文件不同,但是包含的obj文件个数至少是一样的,那么检查两者的Makefile我看到很少量的变化好像是和多语言的差别以及链接的库有差别,比如-static-libstdc++ -static-libgcc这个也许关系不大吧?至少我觉得这个是有运行库和没有运行库的差别,具体差别哪里在好像是异常处理吧?我又忘了。总之可能没关系因为在源代码的libcpp目录下有这些额外的库的链接问题不大。
libgcc.a(_muldi3.o): In function `__multi3':
(.text+0x0): multiple definition of `__multi3'我想这个是我长久以来一直想找到的,但是目前对于我的问题似乎没有效果The archives should be a list of archive files. They may be either explicit file names, or `-l' options.
The specified archives are searched repeatedly until no new undefined references are created. Normally, an archive is searched only once in the order that it is specified on the command line. If a symbol in that archive is needed to resolve an undefined symbol referred to by an object in an archive that appears later on the command line, the linker would not be able to resolve that reference. By grouping the archives, they all be searched repeatedly until all possible references are resolved.
Using this option has a significant performance cost. It is best to use it only when there are unavoidable circular references between two or more archives.
Galadriel: Farewell, Frodo Baggins. I give you the light of Earendil, our most beloved star.
Galadriel: May it be a light for you in dark places, when all other lights go out.
├── build-x86_64-pc-linux-gnu
│ ├── fixincludes
│ ├── libcpp
│ └── libiberty
│ └── testsuite
├── fixincludes
├── gcc
│ ├── ada
│ │ └── gcc-interface
│ ├── analyzer
│ ├── brig
│ ├── build
│ ├── c
│ ├── c-family
│ ├── common
│ ├── cp
│ ├── d
│ ├── doc
│ ├── fortran
│ ├── go
│ ├── include
│ ├── include-fixed
│ │ ├── boost
│ │ │ └── predef
│ │ │ └── os
│ │ ├── root
│ │ │ └── home
│ │ │ └── nick
│ │ │ └── opt
│ │ │ └── gcc-10.2.0
│ │ │ └── include
│ │ │ └── c++
│ │ ├── X11
│ │ └── x86_64-linux-gnu
│ │ └── c++
│ ├── jit
│ ├── lto
│ ├── objc
│ └── objcp
├── gmp
│ ├── cxx
│ ├── demos
│ │ ├── calc
│ │ └── expr
│ ├── doc
│ ├── mpf
│ ├── mpn
│ ├── mpq
│ ├── mpz
│ ├── printf
│ ├── rand
│ ├── scanf
│ ├── tests
│ │ ├── cxx
│ │ ├── devel
│ │ ├── misc
│ │ ├── mpf
│ │ ├── mpn
│ │ ├── mpq
│ │ ├── mpz
│ │ └── rand
│ └── tune
├── intl
├── isl
│ ├── doc
│ ├── imath_wrap
│ └── include
│ └── isl
├── libbacktrace
├── libcc1
├── libcpp
├── libdecnumber
├── libiberty
│ ├── pic
│ └── testsuite
├── lto-plugin
├── mpc
│ ├── doc
│ ├── src
│ └── tests
├── mpfr
│ ├── doc
│ ├── src
│ ├── tests
│ └── tune
├── x86_64-pc-linux-gnu
│ ├── libatomic
│ │ └── testsuite
│ ├── libgcc
│ ├── libgomp
│ │ └── testsuite
│ ├── libitm
│ │ └── testsuite
│ ├── libquadmath
│ │ ├── math
│ │ ├── printf
│ │ └── strtod
│ ├── libsanitizer
│ │ ├── asan
│ │ ├── interception
│ │ ├── libbacktrace
│ │ ├── lsan
│ │ ├── sanitizer_common
│ │ ├── tsan
│ │ └── ubsan
│ ├── libssp
│ │ └── ssp
│ ├── libstdc++-v3
│ │ ├── doc
│ │ │ └── xsl
│ │ ├── include
│ │ │ ├── backward
│ │ │ ├── bits
│ │ │ ├── debug
│ │ │ ├── decimal
│ │ │ ├── experimental
│ │ │ │ └── bits
│ │ │ ├── ext
│ │ │ │ └── pb_ds
│ │ │ │ └── detail
│ │ │ │ ├── binary_heap_
│ │ │ │ ├── binomial_heap_
│ │ │ │ ├── binomial_heap_base_
│ │ │ │ ├── bin_search_tree_
│ │ │ │ ├── branch_policy
│ │ │ │ ├── cc_hash_table_map_
│ │ │ │ ├── eq_fn
│ │ │ │ ├── gp_hash_table_map_
│ │ │ │ ├── hash_fn
│ │ │ │ ├── left_child_next_sibling_heap_
│ │ │ │ ├── list_update_map_
│ │ │ │ ├── list_update_policy
│ │ │ │ ├── ov_tree_map_
│ │ │ │ ├── pairing_heap_
│ │ │ │ ├── pat_trie_
│ │ │ │ ├── rb_tree_map_
│ │ │ │ ├── rc_binomial_heap_
│ │ │ │ ├── resize_policy
│ │ │ │ ├── splay_tree_
│ │ │ │ ├── thin_heap_
│ │ │ │ ├── tree_policy
│ │ │ │ ├── trie_policy
│ │ │ │ └── unordered_iterator
│ │ │ ├── parallel
│ │ │ ├── pstl
│ │ │ ├── tr1
│ │ │ ├── tr2
│ │ │ └── x86_64-pc-linux-gnu
│ │ │ ├── bits
│ │ │ │ ├── extc++.h.gch
│ │ │ │ ├── stdc++.h.gch
│ │ │ │ └── stdtr1c++.h.gch
│ │ │ └── ext
│ │ ├── libsupc++
│ │ ├── po
│ │ ├── python
│ │ ├── scripts
│ │ ├── src
│ │ │ ├── c++11
│ │ │ ├── c++17
│ │ │ ├── c++98
│ │ │ └── filesystem
│ │ └── testsuite
│ └── libvtv
│ └── testsuite
└── zlib
find . -name config.log -print0 -printf " %T@\\n" > /tmp/sort.txt
sort -k2 </tmp/sort.txt
./config.log 1615674928.7171014080
./lto-plugin/config.log 1615674968.0291659660
./build-x86_64-pc-linux-gnu/fixincludes/config.log 1615674970.5451701210
./fixincludes/config.log 1615674970.6131702330
./intl/config.log 1615674971.4371715940
./build-x86_64-pc-linux-gnu/libcpp/config.log 1615674974.5651767660
./zlib/config.log 1615674977.0011807960
./libdecnumber/config.log 1615674977.6731819090
./libbacktrace/config.log 1615674981.9291889570
./build-x86_64-pc-linux-gnu/libiberty/config.log 1615674983.9651923320
./libiberty/config.log 1615674985.6411951110
./gmp/config.log 1615674998.8252170150
./libcpp/config.log 1615674999.9772189320
./isl/config.log 1615675034.9972774730
./mpfr/config.log 1615675044.2732930590
./mpc/config.log 1615675067.7333326220
./gcc/config.log 1615675103.7213936950
./libcc1/config.log 1615675121.8934247010
./x86_64-pc-linux-gnu/libgcc/config.log 1615675507.0301019860
./x86_64-pc-linux-gnu/libssp/config.log 1615675539.0661596290
./x86_64-pc-linux-gnu/libquadmath/config.log 1615675542.0421649930
./x86_64-pc-linux-gnu/libatomic/config.log 1615675546.8101735870
./x86_64-pc-linux-gnu/libgomp/config.log 1615675550.9061809720
./x86_64-pc-linux-gnu/libstdc++-v3/config.log 1615675613.7582945880
./x86_64-pc-linux-gnu/libvtv/config.log 1615675715.7944800520
./x86_64-pc-linux-gnu/libitm/config.log 1615675719.9984877170
./x86_64-pc-linux-gnu/libsanitizer/config.log 1615675720.6864889720
# For stage1 and when cross-compiling use the build libcpp which is很明显的第一次是为了做stage1或者cross-compilation,我是本地编译,所以,stage1是必须的?什么是stage1?什么是NLS?查到了是Native Language Support(NLS),这个就对了和我早上查看到的编译的makefile里没有各种语言的msg的情况是吻合的。诚不我欺也。 我看到了我感兴趣的几个编译的先后顺序,但是依旧摸不着头脑,不过我想最主要的编译故事都发生在gcc目录下,探索的重点应该是那里。
# built with NLS disabled. For stage2+ use the host library and
# its dependencies.
乌合麒麟的画我做了一个小游戏把他的画里的要点标记出来,看你能不能都找出来!,我以为他代表了未来的艺术发展方向,那就是数字艺术,现实与艺术的不着痕迹的完美结合,大有文艺复兴时代绘画写实风格的意味。这幅Better Cotton Initialive尤其好。
申诉不知道有多么的荒谬与恶毒!
强迫劳动的由来。
I have been sexually assaulted and abused.这就是
稻草人小姐对
侵犯人权的控诉吗?BBC/CNN你们可以做的更好些吗?这么赤裸裸的谎言是否太low了?
伸张正义呢?

三月二十九日 等待变化等待机会
generated的部分就很不理解,尤其是反复出现的什么GTY是什么东西呢?GGC是garbage collection这个我早就知道可是。。。还有总是出现的什么OMP之类的似乎和并行运行相关的东西。
# The gengtype generator program is special: Two versions are built.
# One is for the build machine, and one is for the host to allow
# plugins to define their types and generate the supporting GGC
# datastructures and routines with GTY markers.
终于明白了为什么!这个是很好的第一步,至于是什么和怎么样就是以后的工作了。gengtype
As C does not have any means of reflection (and even C++98 does not have enough reflective abilities), gengtype was introduced to support some GCC-specific type and variable annotations, which in turn support garbage collection inside the compiler and precompiled headers. As such, gengtype is a one big kludge of a rudimentary C lexer and parser.
...It is explicitly triggered by a call to ggc_collect and not by allocations. It is implemented in files gcc/ggc.h and gcc/ggc-*.c. Pointers (variables, fields, ...) are explicited (thru the GTY(()) marker), and marking and scanning routines are generated.而这里是直接回答了我之前关于众多的gt-xxx.c的文件的产生的疑问。
... be aware that some additional C files (eg gt-tree-FOO.h or gtype-desc.c) are generated in the object (build) tree (but not in the GCC source tree).
三月三十日 等待变化等待机会
终于我总算把一个看似简单的函数c_compile_file的所有symbol解决了,这个是静态库的顺序
其中parser是我创建的cp下的所有的.o的静态库,cfamily是c-family下的所有的.o的静态库,而common_special是一个非常特殊的处理,它来自于libcommon.a但是我去除了ggc-none.o这个是因为我需要ggc-page.o可是它们两个里有很多函数是重复定义了,我的理解是libcommon.a是给所有不需要ggc的模块使用的,其中的关于ggc的细节实现都是一个空函数,但是作为gcc的实际的实现需要像ggc-page.c里那样的实现。
-lparser -lcfamily -lgcc_main -lcpp -lcommon-target -lcommon_special -lbacktrace -liberty -lisl -lmpc -lmpz -lmpfr -lgmp -ldecnumber -lz -ldl
这里最核心的库是libgcc_main.a它是怎么制作的呢?我是在原来的thin achive
:libbackend.a的基础上制作的,首先,要吧thin archive转成普通的full/current archive。
for i in $(ar t libbackend.a); do ar rvs libbackend_real.a "$i"; done
ar t libbackend_real.a | sort > /tmp/back.txt
ar t libgcc_main.a | sort > /tmp/gcc.txt
comm --check-order -3 /tmp/back.txt /tmp/gcc.txt
attribs.o
cc1plus-checksum.o
glibc-c.o
i386-c.o
A thin archive only contains a symbol table and references to the file. The file format is essentially a System V format archive where every file is stored without the data sections. Every filename is stored as a "long" filename and they are to be resolved as if they were symbolic links.所以当我反复想要重新创建一个current archive拥有full path的时候是不成功的,这里的an page说P是可能的,也许我理解错误吧?
P所以这个就是英语母语的优势,我又一次理解错误,这个只有当创建工具支持full path的时候才有意义,而gnu是不支持的所以我是徒劳的,我看到的是thin archive的类似的Use the full path name when matching names in the archive. GNU ar can not create an archive with a full path name (such archives are not POSIX complaint), but other archive creators can. This option will cause GNU ar to match file names using a complete path name, which can be convenient when extracting a single file from an archive created by another tool.
symlink,换句话说当我要转换的时候是不可能full path name的。
这个英文讲的是什么意思?就是说这个是转为动态库才有用的,因为动态库要解决所有的symbol?但是为什么我不理解,总之和thin archive没有半毛钱关系!--whole-archiveFor each archive mentioned on the command line after the
--whole-archiveoption, include every object file in the archive in the link, rather than searching the archive for the required object files. This is normally used to turn an archive file into a shared library, forcing every object to be included in the resulting shared library. This option may be used more than once.
三月三十一日 等待变化等待机会
昨夜西风凋碧树。我打算调整小目标打算先从提高cpp做起,在理解提高之后再跨越到parser的阶段,这么做的跨度就小多了。
main,接下去是gcc.c里的driver::main做所有的初始化设置,这里我尤其感兴趣的是搜索路径的函数这里有很多的关于spec的解析查找的逻辑很繁琐的,但是非常的必要。但是这个所谓的gcc.c不是backend,它属于frontend,所以,我的程序基本上属于backend,要怎么把前端的逻辑包含进来呢?直接拷贝这几个函数吗?这样的意义在哪里呢?我们如果要更好的控制就必须重新整理前端后端的逻辑代码,而这样做的意义难道变成了把参数解析为一个全局的context之类的大的结构体因为gcc令人头疼的是无数的全局变量!可是这个工作不应该这么做啊!矛盾啊。。
compiler程序来具体执行,比如从可执行文件名字来判断调用哪一个程序,如果不是绝对路径那么就是从正常的程序搜索路径来找,所以这就是我以前很头疼的fork无法跟踪的问题。然后就是所谓的main.c里的所谓的toplev的类摒弃又一次执行它的所谓的成员函数的main。这里我看得困死了。
四月一日 等待变化等待机会
compiler的概念,就是说前端cpp/as/cc1/cc1plus/ar/collect2等等要选择哪一个这个是前端的一个任务,说起来也很简单但是很啰嗦,首先当然是用户呼叫的可执行程序是那个,听上去像是
愚人节的费话,但是其实也不然,取决于你呼叫的是全路径的可执行程序还是文件名,这个我现在又有些模糊了,因为在strace里看到的也许是bash在解析,总之这里要解析的是前端的driver这个类要根据或者用户参数明确指明的语言,比如-x c++,或者就是根据输入文件名的后缀来决定所谓的
compiler是谁?而这个逻辑又是依赖于所谓的
spec来决定的,我是昨天跟踪代码才看到这个是所谓的spec里的execute相关的部分主要指明了所有的编译器中每个对应的输入文件的后缀名,而前端的工作就是搜索spec之后选择spec里的execute-spec里对应的符合的后缀名的编译器。所以,在这个之前寻找正确的spec就是一个很大的问题,这个搜索路径我一直看得不是很清楚其中牵涉到各种目标机器以及版本的组合,这一套逻辑很啰嗦因为spec里各自对应有的要版本号有的不要,如果找不到就使用默认的builtin spec。所以单单从这一点来看前端就已经很复杂了因为它也许是对应了多种支持的语言的比如ada/fortune/objectivec[++]/c[++]等等,加上之前每种语言的流水线上的不同的阶段的所谓
编译器这个组合可能有几十吧。单单解析spec就是一个头疼的事情,我至今对于spec的结构依然一无所知,但是看起来至少前端的逻辑几乎是不怎么更新的除非c++的新规范出炉里面要配置所谓的各种新开关,我估计这部分的代码几乎是不变的因为它是纯粹对后端可执行程序的fork的调用根本没有任何的关联性是依靠文件传出结果的,这个是最小的耦合性了。而且现在我才意识到使用spec可以轻松改变编译器后端而无需重新编译前端,这个我以前模模糊糊看到过各路神仙使用spec来调用包括gdb在内的前端来运行各种神奇的变化,现在真正的开始有意识了其中的一个粗浅的道理。
struct path_prefix
{
struct prefix_list *plist; /* List of prefixes to try */
int max_len; /* Max length of a prefix in PLIST */
const char *name; /* Name of this list (used in config stuff) */
};
四三我眼花了怎么看成四行了?大搜索路径
/* List of prefixes to try when looking for executables. */
static struct path_prefix exec_prefixes = { 0, 0, "exec" };
/* List of prefixes to try when looking for startup (crt0) files. */
static struct path_prefix startfile_prefixes = { 0, 0, "startfile" };
/* List of prefixes to try when looking for include files. */
static struct path_prefix include_prefixes = { 0, 0, "include" };
./gcc/Makefile: -DDEFAULT_REAL_TARGET_MACHINE=\"$(real_target_noncanonical)\"
static const char *const spec_version = DEFAULT_TARGET_VERSION;
static const char *spec_machine = DEFAULT_TARGET_MACHINE;
./gcc/Makefile: -DDEFAULT_TARGET_VERSION=\"$(version)\"
./gcc/Makefile: -DDEFAULT_REAL_TARGET_MACHINE=\"$(real_target_noncanonical)\"
struct prefix_list
{
const char *prefix; /* String to prepend to the path. */
struct prefix_list *next; /* Next in linked list. */
int require_machine_suffix; /* Don't use without machine_suffix. */
/* 2 means try both machine_suffix and just_machine_suffix. */
int priority; /* Sort key - priority within list. */
int os_multilib; /* 1 if OS multilib scheme should be used,
0 for GCC multilib scheme. */
};
machine_suffix就是
machine_suffix = concat (spec_host_machine, dir_separator_str, spec_version,
accel_dir_suffix, dir_separator_str, NULL);
just_machine_suffix = concat (spec_machine, dir_separator_str, NULL);
$ find /usr/bin/ -maxdepth 1 -type f -executable -name "*gcc"
/usr/bin/c89-gcc
/usr/bin/c99-gcc
/* Figure compiler version from version string. */
compiler_version = temp1 = xstrdup (version_string);
/* The complete version string, assembled from several pieces.
BASEVER, DATESTAMP, DEVPHASE, and REVISION are defined by the
Makefile. */
const char version_string[] = BASEVER DATESTAMP DEVPHASE REVISION;
grep 'BASEVER\|DATESTAMP\|DEVPHASE\|REVISION' Makefile
BASEVER := $(srcdir)/BASE-VER # 4.x.y
DEVPHASE := $(srcdir)/DEV-PHASE # experimental, prerelease, ""
DATESTAMP := $(srcdir)/DATESTAMP # YYYYMMDD or empty
REVISION := $(srcdir)/REVISION # [BRANCH revision XXXXXX]
nick@nick-HP-Laptop:~/Downloads/gcc-10.2.0/gcc-10.2.0/gcc$ cat BASE-VER
10.2.0
nick@nick-HP-Laptop:~/Downloads/gcc-10.2.0/gcc-10.2.0/gcc$ cat DEV-PHASE
nick@nick-HP-Laptop:~/Downloads/gcc-10.2.0/gcc-10.2.0/gcc$ cat DATESTAMP
20200723
nick@nick-HP-Laptop:~/Downloads/gcc-10.2.0/gcc-10.2.0/gcc$ cat REVISION
cat: REVISION: 没有那个文件或目录
version_string是10.2.020200723才对啊。可是当我满怀信心的在gdb打印出来的却是
(gdb) p version_string
$5 = 0x53abac <version_string> "10.2.0"
objdump -Ct version.o | grep .rodata | grep version_string
000000000000001c g O .rodata 0000000000000007 version_string
0000000000000023 g O .rodata 0000000000000007 pkgversion_string
readelf -x .rodata version.o
“.rodata”节的十六进制输出:
0x00000000 3c687474 70733a2f 2f676363 2e676e75 <https://gcc.gnu
0x00000010 2e6f7267 2f627567 732f3e00 31302e32 .org/bugs/>.10.2
0x00000020 2e300028 47434329 2000 .0.(GCC) .
10.2.0(最后一个NULL字符是c语言literal自动添加的)。
./x86_64-pc-linux-gnu/libstdc++-v3/include/x86_64-pc-linux-gnu/bits/c++config.h:#define __GLIBCXX__ 20200723
./x86_64-pc-linux-gnu/libstdc++-v3/src/c++11/cxx11-ios_failure-lt.s: .string "__GLIBCXX__ 20200723"
./x86_64-pc-linux-gnu/libstdc++-v3/src/c++11/cxx11-ios_failure-lt.s: .string "__GLIBCXX__ 20200723"
掉包了。 在Makefile里version.o是这样编译的:
...
-DBASEVER=$(BASEVER_s) -DDATESTAMP=$(DATESTAMP_s) \
-DREVISION=$(REVISION_s) \
-DDEVPHASE=$(DEVPHASE_s)
...
DATESTAMP_s := \
"\"$(if $(DEVPHASE_c)$(filter-out 0,$(PATCHLEVEL_c)), $(DATESTAMP_c))\""
DATESTAMP_c := $(shell cat $(DATESTAMP))-DBASEVER="\"10.2.0\"" -DDATESTAMP="\"\"" \
-DREVISION="\"\"" \
-DDEVPHASE="\"\"" -DPKGVERSION="\"(GCC) \"" \make SHELL='sh -x'我看到了什么呢?
结果还是没有看到什么最后只好祭出终极法宝直接$(info "DATESTAMP_s ==> ${DATESTAMP_s}")结果还是空,这个时候我才恍然大悟,我看代码太粗率了,这个条件是要 $(DEVPHASE_c)$(filter-out 0,$(PATCHLEVEL_c))时间戳才有意义!这就是为什么时间戳是空! 我为了这么一个小东西version_string耗费了一个早上的时间!
匹夫无罪,怀璧其咎。因为中国的强大动了美国人的奶酪,这个地球的食物链的顶端只能是三亿美国人没有更多的空间容纳一个十四亿的中国人,哪怕他们中的大多数人愿意牺牲自我降级到食物链的中下端也不行。这是一个弱肉强食的丛林世界,统治这片黑森林的法则被称为
三体人(Trisolaran)式思维。
四月二日 等待变化等待机会
根,但是这个东西说简单也简单,说复杂也复杂。首先,这个是可以使用用户定义的环境变量GCC_EXEC_PREFIX来指定的。假如没有指定的话它的确定方式是采用libiberty的一个函数make_relative_prefix或者是make_relative_prefix_ignore_links,后者是前者的
canonicalized的版本,也就是要resolve symlink。这两个函数都要求三个参数
这里的算法我看了好久还是将信将疑,到底什么是gcc的executable prefix呢?说来好笑它要计算的是计算BIN_PREFIX和PREFIX之间的common prefix,然后得到这个common prefix和BIN_PREFIX之间的相对路径,最后把这个相对路径安在PROGNAME的除却程序名之外的/* Given three strings PROGNAME, BIN_PREFIX, PREFIX, return a string that gets to PREFIX starting with the directory portion of PROGNAME and a relative pathname of the difference between BIN_PREFIX and PREFIX. For example, if BIN_PREFIX is /alpha/beta/gamma/gcc/delta, PREFIX is /alpha/beta/gamma/omega/, and PROGNAME is /red/green/blue/gcc, then this function will return /red/green/blue/../../omega/. If no relative prefix can be found, return NULL. */
目录后。比如BIN_PREFIX(/alpha/beta/gamma/gcc/delta)和PREFIX(/alpha/beta/gamma/omega/)的comon prefix是/alpha/beta/gamma/,那么它相对于BIN_PREFIX的相对路径就是../../omega/,而这里恰恰是理解上的关键,为什么计算相对路径看上去好像是从delta算起,而不是delta/?照例说它是一个path,不应该啊?这个是我费了不少时间才看明白还做了实验才确认的。细节在后面。接下来把PROGNAME(/red/green/blue/gcc)的目录部分求出来加上之前的相对路径。
我做实验是使用llibiberty的静态库直接链接上来运行这两个函数,中间闹了个笑话就是我忘了声明这两个函数为extern "C"结果导致链接不上迷惑了我很久。这里的一个细节是不能引用libiberty.h的头文件,原因是其中包含了basename这个函数和glibc里的定义不一致。所以,只能链接。
另一个方式是看源代码,其中计算相对路径用到的函数split_directories实际上很幼稚的就是数有几个/,所以,你传入的参数里的路径是否以/结尾很重要!,有和没有直接导致输出相差一个../,联想到之前我们看到gcc处理所有的路径都要在加为保证添加/.,就知道这个问题有多重要,不仅它能保证symlink也会成为合法的directory,而且路径的结尾一致可以保证相对路径的计算正确。其实是相对的路径,只要报纸一致就可以,比如大家结尾都不加/也可以。
变种,比如不同的toolchain的安装在统一台机器里,这个相对路径至关重要,说穿了就是从当前的可执行的gcc找到gcc的安装路径的
根目录或者说gcc编译的configure里的prefix的相对路径。
Define default real time library to link if one is not already specified in the configuration process.这里要注意不要误以为是real time library,因为是
realtime library。恐怕只有我才会这么误解。
/* What do with libstdc++:
-1 means we should not link in libstdc++
0 means we should link in libstdc++ if it is needed
1 means libstdc++ is needed and should be linked in.
2 means libstdc++ is needed and should be linked statically. */
/* Make sure -lstdc++ is before the math library, since libstdc++ itself uses those math routines. */
| 环境变量 | 添加到的搜索路径组 | 备注 |
|---|---|---|
| GCC_EXEC_PREFIX | exec_prefixes, startfile_prefixes | 仅仅采用去除后缀/lib/gcc后的前缀,并且设定为std_prefix |
| COMPILER_PATH | exec_prefixes, include_prefixes | 条件要求不是交叉编译的情况下是以:分隔的多个路径 |
| LIBRARY_PATH | startfile_prefixes | 是以:分隔的多个路径 |
| LPATH | startfile_prefixes | 条件要求不是交叉编译的情况下是以:分隔的多个路径 |
四月三日 等待变化等待机会
COMPONENT is the value to be passed to update_path.就是在这个update_path里面去做所谓的translate_name结果又把设定的@BINUTILS, @GCC翻译回了原先的std_prefix也就是正常的gcc-configure-prefix。这个骚操作是在干什么呢?我最后的解释只能是这个是gcc适应某些安装方式比如在windows下的情形,比如cygwin使用
注册表来存储这一类的环境变量吧?总而言之gcc的前端要适应多种复杂的安装配置还有数不清的参数开关,经年累月积累下来的复杂行为实在是让人头疼啊。
中规中矩的情况下搜索路径是这样子设定的
那么这两个目录下究竟存的什么呢?
搜索路径组名称 前缀名称 前缀路径 标签名称 exec_prefixes standard_libexec_prefix ${INSTALL}/libexec/gcc GCC exec_prefixes standard_libexec_prefix ${INSTALL}/libexec/gcc BINUTILS exec_prefixes standard_exec_prefix ${INSTALL}/lib/gcc BINUTILS startfile_prefixes standard_exec_prefix ${INSTALL}/lib/gcc BINUTILS exec_prefixes concat (tooldir_prefix, "bin", dir_separator_str, NULL) tooldir_prefix = concat (gcc_exec_prefix ? gcc_exec_prefix : standard_exec_prefix, spec_host_machine, dir_separator_str, spec_version, accel_dir_suffix, dir_separator_str, tooldir_prefix2, NULL); tooldir_prefix2 = concat (tooldir_base_prefix, spec_machine, dir_separator_str, NULL); 所以我的系统是${INSTALL}/lib/gcc/x86_64-pc-linux-gnu/10.2.0/../../../../bin/ BINUTILS startfile_prefixes concat (tooldir_prefix, "lib", dir_separator_str, NULL) tooldir_prefix = concat (gcc_exec_prefix ? gcc_exec_prefix : standard_exec_prefix, spec_host_machine, dir_separator_str, spec_version, accel_dir_suffix, dir_separator_str, tooldir_prefix2, NULL); tooldir_prefix2 = concat (tooldir_base_prefix, spec_machine, dir_separator_str, NULL); 所以我的系统结果是${INSTALL}/lib/gcc/x86_64-pc-linux-gnu/10.2.0/../../../../lib/ BINUTILS startfile_prefixes concat (gcc_exec_prefix ? gcc_exec_prefix : standard_exec_prefix, machine_suffix, standard_startfile_prefix, NULL) standard_startfile_prefix=$(unlibsubdir)在没有设定accelerator compiler的情况下我的系统等价于${INSTALL}/lib/gcc/x86_64-pc-linux-gnu/10.2.0/../../../ BINUTILS startfile_prefixes standard_startfile_prefix_1 /lib startfile_prefixes standard_startfile_prefix_2 /usr/lib
../src/configure -v --with-pkgversion='Ubuntu 7.5.0-3ubuntu1~18.04' --with-bugurl=file:///usr/share/doc/gcc-7/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++ --prefix=/usr --with-gcc-major-version-only --program-suffix=-7 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --enable-bootstrap --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-libmpx --enable-plugin --enable-default-pie --with-system-zlib --with-target-system-zlib --enable-objc-gc=auto --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu
目录名 意义 默认值 --prefix the toplevel installation directory defaults to/usr/local --exec-prefix the toplevel installation directory for architecture-dependent files The default is prefix --bindir the installation directory for the executables called by users (such as gcc and g++). The default is exec-prefix/lib --libexecdir the installation directory for internal executables of GCC The default is exec-prefix/libexec
不足为外人道也的东西,根本那不上台面的东西,但是对于理解gcc的配置和编译过程设置确实是很有帮助的东西,比如gcc的gcc_gxx_include_dir尤其有用,他解决了我长久以来看到的困惑就是c++的头文件安装在哪里的问题。又比如对于到底gcc的二进制文件放在哪个目录这样子的问题我是回答不上来的,因为这个问题的定义有问题,就是你所说的gcc的binary是指的gcc/g++还是后台真正干活的cc1[plus],collect2呢?而且我的感觉一般程序员根本就分不清到底gcc/g++和它们是什么关系,因为我至今也不是非常的清楚。因为前者的真正目录是libexecsubdir,而这一点在官方配置gcc比如Ubuntu-7.5的时候故意人为设定--libexecdir=/usr/lib 让人产生很多的误会,这也就是当我自己编译gcc的时候看到的众多的在官方ubuntu配置下看不到的现象,让人无所适从!
目录名变量 意义 值 prefix Common prefix for installation directories defaults to/usr/local local_prefix Directory in which to put localized header files. On the systems with gcc as the native cc, local_prefixmay not beprefixwhich is /usr/usr/local (NOTE: local_prefix *should not* default from prefix.) exec_prefix Directory in which to put host dependent programs and libraries ${prefix} bindir Directory in which to put the executable for the command gcc${exec_prefix}/bin libdir Directory in which to put the directories used by the compiler ${exec_prefix}/lib libexecdir Directory in which GCC puts its executables ${exec_prefix}/libexec libsubdir Directory in which the compiler finds libraries etc. $(libdir)/gcc/$(real_target_noncanonical)/$(version)$(accel_dir_suffix) libexecsubdir Directory in which the compiler finds executables $(libexecdir)/gcc/$(real_target_noncanonical)/$(version)$(accel_dir_suffix) plugin_resourcesdir Directory in which all plugin resources are installed $(libsubdir)/plugin plugin_includedir Directory in which plugin headers are installed $(plugin_resourcesdir)/include plugin_bindir Directory in which plugin specific executables are installed $(libexecsubdir)/plugin libsubdir_to_prefix $(prefix), expressed as a path relative to $(libsubdir). 这个是一个中间变量有一个非常复杂的sed表达式,但是一板情况下就是../它的作用是用来帮助toolchain找到prefix的路径。 unlibsubdir Used to produce a relative $(gcc_tooldir) in gcc.o ifeq ($(enable_as_accelerator),yes) unlibsubdir = ../../../../.. else unlibsubdir = ../../.. endif prefix_to_exec_prefix $(exec_prefix), expressed as a path relative to $(prefix). echo "${exec_prefix}" | sed -e 's|^${prefix}||' -e 's|^/||' -e '/./s|$$|/|' 我的实验结果就是这个复杂的表达式在以上设定的情况下结果就是${prefix} gcc_tooldir Used in install-cross $(libsubdir)/$(libsubdir_to_prefix)$(target_noncanonical) build_tooldir Since gcc_tooldir does not exist at build-time, use -B$(build_tooldir)/bin/ $(exec_prefix)/$(target_noncanonical) gcc_gxx_include_dir Directory in which the compiler finds target-independent g++ includes. $(libsubdir)/$(libsubdir_to_prefix)include/c++/$(version)
tooldir_prefix的部分。
accel_dir_suffix居然是什么
A prefix to be used when this is an accelerator compiler,很明显的大多数人的机器里都是空,这是什么古老的东东呢?我实在是懒得google了。
${prefix}/libexec/gcc/:${prefix}/libexec/gcc/:${prefix}/lib/gcc/${prefix}/lib/gcc/x86_64-pc-linux-gnu/10.2.0/../../../../x86_64-pc-linux-gnu/bin/${prefix}/lib/gcc/x86_64-pc-linux-gnu/10.2.0/../../../../x86_64-pc-linux-gnu/lib/${prefix}/$(real_target_noncanonical)/lib/
这个startfile_prefixes的重要性除了runtime library之外应该就是寻找specs的作用,当然我从来不知道怎么使用自然没有,但是用户使用自己的specs是一个高超的技巧。
四月四日 等待变化等待机会
Specifying Subprocesses and the Switches to Pass to Them,真的是一句顶一万句啊!但是后面的文档我像看天书一样摸不着头脑,其中的语法非常的费解,我和代码里定义的spec根本对不上,只好放弃转而使用gdb看看究竟这个最后转化为呼叫参数究竟是怎么样的。
${INSTALL}/bin/g++ -v -std=c++17 -I${INSTALL}/lib/gcc/x86_64-pc-linux-gnu/10.2.0/plugin/include -O0 -g3 -Wall -c -fmessage-length=0 -MMD -MP -MF"src/parserTest.d" -MT"src/parserTest.o" -o "src/parserTest.o" "../src/parserTest.cpp"
${INSTALL}/libexec/gcc/x86_64-pc-linux-gnu/10.2.0/cc1plus -quiet -v -I ${INSTALL}/lib/gcc/x86_64-pc-linux-gnu/10.2.0/plugin/include -imultiarch x86_64-linux-gnu -MMD src/parserTest.d -MF src/parserTest.d -MP -MT src/parserTest.o -dD -D_GNU_SOURCE ../src/parserTest.cpp -quiet -dumpbase parserTest.cpp -mtune=generic -march=x86-64 -auxbase-strip src/parserTest.o -g3 -O0 -Wall -std=c++17 -version -fmessage-length=0 -o /tmp/ccGN42w0.s
as -v -I ${INSTALL}/lib/gcc/x86_64-pc-linux-gnu/10.2.0/plugin/include --64 -o src/parserTest.o /tmp/ccQXFUvq.s独上高楼,望尽天涯路。其实,并非完全没有收获,因为
四月五日 等待变化等待机会
。而大多数聪明人对此嗤之以鼻转而开辟全新的语言。其他的替代编译器事实上都在追赶gcc。狗GO的语言lang
#0 scan_translation_unit (pfile=0x3650ab0) at ../../gcc-10.2.0/gcc/c-family/c-ppoutput.c:175
#1 0x0000000000c2d280 in preprocess_file (pfile=0x3650ab0)
at ../../gcc-10.2.0/gcc/c-family/c-ppoutput.c:102
#2 0x0000000000c28be0 in c_common_init () at ../../gcc-10.2.0/gcc/c-family/c-opts.c:1167
#3 0x0000000000a4fe1f in cxx_init () at ../../gcc-10.2.0/gcc/cp/lex.c:329
#4 0x000000000139f946 in lang_dependent_init (
name=0x7fffffffe1b5 "/home/nick/eclipse-2021/parserTest/src/parserTest.cpp")
at ../../gcc-10.2.0/gcc/toplev.c:1974
#5 0x00000000013a018d in do_compile () at ../../gcc-10.2.0/gcc/toplev.c:2263
#6 0x00000000013a0500 in toplev::main (this=0x7fffffffdb76, argc=21, argv=0x7fffffffdc78)
at ../../gcc-10.2.0/gcc/toplev.c:2417
#7 0x00000000022e4bbb in main (argc=21, argv=0x7fffffffdc78) at ../../gcc-10.2.0/gcc/main.c:39
四月六日 等待变化等待机会
一公里,但也是强弩之末了。明天再说吧。
四月七日 等待变化等待机会
cxx_dialect = cxx17;
imultiarch="x86_64-linux-gnu";
flag_abi_version=14; //latest_abi_version=14;
flag_preprocess_only=1;
user_label_prefix="";
ix86_arch_string="x86_64";
ix86_tune_string="generic";
挖出来化繁为简的简单实现,这种做法是英文hacker的原型,但是却是最拙劣的一种。
void define_cb(cpp_reader *cpp, location_t loc, cpp_hashnode *hash){
cout<<cpp_macro_definition(cpp, hash)<<endl;
}
cpp_callbacks * callback= cpp_get_callbacks(parse_in);
callback->define=define_cb;
四月八日 等待变化等待机会
四月九日 等待变化等待机会
compiler,它的功能当然容易明白就是根据后缀名推理使用哪一个spec,但是这中间更加复杂的是进一步的相关的扩展就看不懂了。
简约的表达开关之间的逻辑因果关系。比如某些开关不能共存,某些开关是另一些的充分条件或者必要条件等等,而这里spec可以是开关本身的字符串也可以代表字符串的变量甚至于存储字符串的文件名。可以说非常的灵活复杂。
白猫黑猫论是高度的浓缩,治国理政其实最后的本质大都是一样的,只不过对于前端用户来说
不足为外人道也。你去和一个只能听得懂c语言的用户来说fortune的描述方式肯定是对牛弹琴,同样的各个语言的操纵者彼此是完全不可能互相理解的,但是作为编译器却要集合如此海量的不同诉求来解析它们的各自的独特要求,最后去粗取精融会贯通在复杂的排查纠错之后生成用户所期待的可以执行的政策来具体实施。然而,作为用户根本无力也无兴趣自己的复杂要求怎么样被编译器理解并产生自己期待的可执行程序达到用户的千奇百怪的目的,它们这里我使用非生物的它既代表了客观中立的看待用户,更是隐含了对于无知如动物的用户的鄙视和可怜都是结果导向的经验生物,只会运用几百万年进化的唯一武器,神经系统的条件反射来判断自己的行为的唯一目的是否达成:也就是生物的唯一存在目的所导致的
趋利避害的行为。面对如此不可预测的用户作为编译器的最好的生存逻辑是适应用户的多种繁杂的语言以及连带造成的复杂各异的开关逻辑并竭尽所能取悦用户真实的目的,还是说从更高层级来越俎代庖主动为用户来设计一条它们看得懂听得懂的道路。这是一个人类终极的哲学问题,甚至是一个社会学的伪命题,因为从社会实践来看人类社会还处于发展的婴幼儿时期,还不明白自己的发展方向也不明白究竟自己真的需要什么,仿佛婴儿唯一的思维就是来源于饥饿的条件反射的哇哇啼哭。而作为执政者如何翻译貌似无理的各种用户选民的诉求是否应该经过严格的逻辑甄选而不是一味的盲从?而这些相关的诉求之间的某种内生的逻辑关系应该是早已刻画在spec里的至理名言。
四月十日 等待变化等待机会
探寻编译过程时候才再一次明白我的尝试的意义,那就是哪怕最简单的preprocessing的过程即便是libcpp的回调函数都是苍白无力的有限。比如plugin的PLUGIN_INCLUDE_FILE事件是不包含系统的builtin的头文件部分的,即便我再深入使用cpp_callbacks注册parse_in的回调函数
include得到的也是如此。所以,我们面对的gcc是一个不会开口说话的
闷葫芦。
union GTY ((ptr_alias (union lang_tree_node), desc ("tree_node_structure (&%h)"), variable_size)) tree_node{
struct tree_base GTY ((tag ("TS_BASE"))) base;
struct tree_typed GTY ((tag ("TS_TYPED"))) typed;
struct tree_common GTY ((tag ("TS_COMMON"))) common;
struct tree_int_cst GTY ((tag ("TS_INT_CST"))) int_cst;
...
};
三不政策能够持续多久呢?直到我看到这个定义才有些恍然大悟的样子。
union tree_node;
typedef union tree_node *tree;
四月十一日 等待变化等待机会
通用型的函数。
The purpose of GENERIC is simply to provide a language-independent way of representing an entire function in trees.
四月十二日 等待变化等待机会
新人希望改变gcc文档长期落后更新的现状,更加专注于html格式而不是传统的manpage/html/pdf一体化的固定格式。我个人以为它的权威性是不够的。第一步是发现有不少的有趣的plugin,但是2011年一定发生了什么重大的事件导致大量的程序在那一年后停止了。那一年发生了什么大事?
宇宙社会学这种
三体人式的的思维模式同样适用于
中美关系,事实上我非常怀疑作者当初设想的对象就是如此:
生存,不过其中的内涵因为两个文明发展阶段和特点又有着它们自己的特点
新发现都是既有资源的发现而已,比如化石能源矿产土地等等,各种资源总量相对固定。
宇宙社会学的两个推论也是类似的
零和博弈的
修昔底德陷阱(Thucydides Trap)的两个对立文明彼此之间充满了对于彼此所宣称的所谓国家发展目的的猜疑与否定。双方对于彼此明显的生存目的讳莫如深只能更加加深各自对于彼此的真实目的的怀疑。这里的更加深层次的原因在于双方的暂时维持的所谓
和平的根本基础是建立在自冷战以来的所谓
确保相互摧毁MAD(Mutual Assured Destruction),而这个基础的核心在于核讹诈与反讹诈本身就是猜疑与欺骗的本质更加加剧了这个猜疑链的深度和广度。
橙色战术或者说
颜色革命
神迹战术或者
民主灯塔
智子锁死人类科学家对于微观世界的探索路径,而美国采用的就是在芯片基础软件领域的严防死守阻止对方在至关重要的科技领域的进步路径。
四月十三日 等待变化等待机会
四月十四日 等待变化等待机会
兼容的机器了吧?在这些众多的特性之一就是所谓的64-bit_data_models,我记得我以前就看过这个东西,但是要真正理解其中的含义其实未必那么简单。首先,这个在gcc里是怎么体现的呢?用脚趾头想也知道是实现配置的,也就是按照configure脚本里配置的。所以,这个东西是在所谓的
target-machine相关的部分吧?所以,当你看到一个头文件的名字叫做tm.h就不应该意外,而且它一定是在编译gcc的目录下才有,不是吗?这一点都想不到就不要再看下去了。其实大多数人能够接触的就是LLP64和LP64两种,而它们的区别也就是关于long int的不同。
这里的这个表之所以重要是因为这一段代码没有它你就看不懂! 对照上面的表里的long int=64和指针size=64,和int=32,所以它就是LP64!
64-bit data models Data model short (integer) int long (integer) long long pointers,
size_tSample operating systems ILP32 16 32 32 64 32 x32 and arm64ilp32 ABIs on Linux systems. LLP64 16 32 32 64 64 Microsoft Windows (x86-64 and IA-64) using Visual C++; and MinGW LP64 16 32 64 64 64 Most Unix and Unix-like systems, e.g., Solaris, Linux, BSD, macOS. Windows when using Cygwin; z/OS ILP64 16 64 64 64 64 HAL Computer Systems port of Solaris to the SPARC64 SILP64 64 64 64 64 64 Classic UNICOS[45][46] (versus UNICOS/mp, etc.)
但是当我搜索LLP64目标时候发现似乎只有ARM64的aarch64才是这个目标,那么gcc在所谓的cgywin下是怎么样的呢?也许我这里混淆了什么,不过我从来不用windows下的东西了,所以,管它呢?
int: mostly 32 bits long (Linux, Mac and Windows)long: 64 bits on Mac and Linux, 32 on Windowslong long: 64-bit on Mac, Linux, and Windows x64- (
u)intptr_t: exact length of pointer (32 on 32-bit, 64 on 64-bit systems)
好心的为你定义这个所谓的SIZETYPE,实际上它是要去推理的。所谓的precision是一个很复杂的过程的结果。首先,有一个相关的常量是在编译的时候定义的#define NUM_INT_N_ENTS 1。它是好几个相关数组的长度,其中我关心的是int_n_data它的类型是相当让我吃惊的复杂东西 说它复杂在于scalar_int_mode_pod是一个让人感到很吃惊的类,因为它背后的所谓的
machine mode是一个我一无所知的领域。 而编译过程的定义让我也是摸不着头脑
(gdb) p SIZETYPE
$2 = "long unsigned int"
(gdb) p SIZETYPE
$4 = "unsigned int"
options这里我被一个诡异的事情纠缠,就是这个结构里没有一丝一毫提到TARGET_LP64或者SIZE_TYPE可是这个结构指针赋值之后为什么这两个所谓的
变量就变了呢?在我看来它们是用宏定义的literal而已,不是吗?在
defaults.h里
#ifndef SIZE_TYPE
#define SIZE_TYPE "long unsigned int"
#endif
x86-64.h里定义为
#undef SIZE_TYPE
#define SIZE_TYPE (TARGET_LP64 ? "long unsigned int" : "unsigned int")
tm.h里定义了很重要的两件事,一个是关于使用什么
c library的问题,这个是我以前一直没有注意到的,gcc支持四种glibc, uclibc, bionic,musl,这个bionic我还真的没有听说过。另一个就是定义一大堆的config下相关的目标机器相关的头文件。这些头文件对于一个各个平台共用的
defaults.h下默认定义的宏进行了重定义,这个就是目标机器的由来的一部分。这里当然包含了大量的细节,我能叫的上名字就不错了,更不要提细节了,那些应该都是各个平台专家才能明白的细节了,比如说指令集的定义等等吧?
四月十五日 等待变化等待机会
(gdb) info macro SIZE_TYPE
Defined at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/../../gcc-10.2.0/gcc/config/i386/x86-64.h:40
included at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/./tm.h:33
included at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/../../gcc-10.2.0/gcc/opts.c:26
#define SIZE_TYPE (TARGET_LP64 ? "long unsigned int" : "unsigned int")
(gdb) info macro TARGET_LP64
Defined at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/../../gcc-10.2.0/gcc/config/i386/i386.h:203
included at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/./tm.h:26
included at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/../../gcc-10.2.0/gcc/opts.c:26
#define TARGET_LP64 TARGET_ABI_64
(gdb) info macro TARGET_ABI_64
Defined at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/./options.h:8268
included at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/./tm.h:22
included at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/../../gcc-10.2.0/gcc/opts.c:26
#define TARGET_ABI_64 ((ix86_isa_flags & OPTION_MASK_ABI_64) != 0)
(gdb) p ix86_isa_flags
$2 = 0
(gdb) info macro OPTION_MASK_ABI_64
Defined at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/./options.h:8141
included at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/./tm.h:22
included at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/../../gcc-10.2.0/gcc/opts.c:26
#define OPTION_MASK_ABI_64 (HOST_WIDE_INT_1U << 4)
(gdb) info macro HOST_WIDE_INT_1U
Defined at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/../../gcc-10.2.0/gcc/hwint.h:70
included at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/../../gcc-10.2.0/gcc/system.h:1204
included at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/../../gcc-10.2.0/gcc/opts.c:22
#define HOST_WIDE_INT_1U HOST_WIDE_INT_UC (1)
(gdb) p OPTION_MASK_ABI_64
$3 = 16
(gdb) info macro ix86_isa_flags
Defined at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/./options.h:53
included at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/./tm.h:22
included at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/../../gcc-10.2.0/gcc/opts.c:26
#define ix86_isa_flags global_options.x_ix86_isa_flags
(gdb) p global_options_init.x_ix86_isa_flags
$5 = 18
(gdb) p opts->x_ix86_isa_flags
$6 = 0
(gdb)
struct default_include
{
const char *const fname; /* The name of the directory. */
const char *const component; /* The component containing the directory
(see update_path in prefix.c) */
const char cplusplus; /* Only look here if we're compiling C++. */
const char cxx_aware; /* Includes in this directory don't need to
be wrapped in extern "C" when compiling
C++. */
const char add_sysroot; /* FNAME should be prefixed by
cpp_SYSROOT. */
const char multilib; /* FNAME should have appended
- the multilib path specified with -imultilib
when set to 1,
- the multiarch path specified with
-imultiarch, when set to 2. */
};
objdump -Ct parserTest| grep cpp_include_defaults
000000000084615c l F .text 0000000000000015 _GLOBAL__sub_I_cpp_include_defaults
00000000021fb680 g O .rodata 0000000000000120 cpp_include_defaults
0x021fb680 d8b21f02 00000000 5ab31f02 00000000 ........Z.......
0x021fb690 01010000 00000000 60b31f02 00000000 ........`.......
0x021fb2d0 ffffff7f 02000000 2f686f6d 652f6e69 ......../home/ni
0x021fb2e0 636b2f44 6f776e6c 6f616473 2f676363 ck/Downloads/gcc
0x021fb2f0 2d31302e 322e302f 6763632d 31302e32 -10.2.0/gcc-10.2
0x021fb300 2e302d64 65627567 2d6c6962 6370702d .0-debug-libcpp-
0x021fb310 696e7374 616c6c2f 6c69622f 6763632f install/lib/gcc/
0x021fb320 7838365f 36342d70 632d6c69 6e75782d x86_64-pc-linux-
0x021fb330 676e752f 31302e32 2e302f2e 2e2f2e2e gnu/10.2.0/../..
0x021fb340 2f2e2e2f 2e2e2f69 6e636c75 64652f63 /../../include/c
0x021fb350 2b2b2f31 302e322e 3000472b 2b000000 ++/10.2.0.G++...
四月十六日 等待变化等待机会
(gdb) info macro GPLUSPLUS_INCLUDE_DIR
The symbol `GPLUSPLUS_INCLUDE_DIR' has no definition as a C/C++ preprocessor macro
at /home/nick/Downloads/gcc-10.2.0/debug-libcpp-build/gcc/../../gcc-10.2.0/gcc/toplev.c:2359
readelf --debug-dump=macro cppdefault.o | grep GPLUSPLUS_INCLUDE_DIR
DW_MACRO_define_strp - lineno : 0 macro : GPLUSPLUS_INCLUDE_DIR "/home/nick/Downloads/gcc-10.2.0/gcc-10.2.0-debug-libcpp-install/lib/gcc/x86_64-pc-linux-gnu/10.2.0/../../../../include/c++/10.2.0"
gcc_gxx_include_dir = $(libsubdir)/$(libsubdir_to_prefix)include/c++/$(version)
...
./gcc/Makefile: -DGPLUSPLUS_INCLUDE_DIR=\"$(gcc_gxx_include_dir)\" \系统搜索目录但是命令行我怎么也找不到一个输出的指令,它实际上是cpp_include_defaults的复杂的变体,因为在--print-search-dirs里的install/programs/libraries指的完全不是一回事,它们是可执行程序以及可执行程序依赖的库的搜索路径和语言相关的头文件压根不是一回事。所以,官方文档也只能使用实际编译命令行输出的目录。
这个从编译过程就明白它实际上是这个cpp_include_defaults的第一个宏的结果To construct a .gch file from one of these base header files, first find the include directory for the compiler. One way to do this is:
g++ -v hello.cc #include <...> search starts here: /mnt/share/bld/H-x86-gcc.20071201/include/c++/4.3.0 ... End of search list.
gcc_gxx_include_dir = $(libsubdir)/$(libsubdir_to_prefix)include/c++/$(version)合集。
Then, create a precompiled header file with the same flags that will be used to compile other projects.
g++ -Winvalid-pch -x c++-header -g -O2 -o ./stdc++.h.gch /mnt/share/bld/H-x86-gcc.20071201/include/c++/4.3.0/x86_64-unknown-linux-gnu/bits/stdc++.hThe resulting file will be quite large: the current size is around thirty megabytes.
How to use the resulting file.
g++ -I. -include stdc++.h -H -g -O2 hello.cc
How to use the resulting file.
g++ -I. -include stdc++.h -H -g -O2 hello.cc
四月十七日 等待变化等待机会
Template metaprogramming (TMP) is a metaprogramming technique in which templates are used by a compiler to generate temporary source code, which is merged by the compiler with the rest of the source code and then compiled.逻辑上应该有编译两次吗?还是仅仅产生GENERIC之类的树呢?如果template没有实例化的需求编译器是不检查语法的,不是吗?所以,也谈不上什么临时源代码,我觉得这个仅仅是逻辑上的分两步吧?我记得有一个帖子在说如何解决这些问题,好像是所谓的
Borland的方案和gcc的方案?
The use of templates can be thought of as compile-time polymorphism.这个什么
compile-time polymorphism是学术研究的课题吧?问题是有没有一种单独的meta compiler呢?如果有单独的,人们怎么能够相信它的正确性呢?所以这就反证了它的独立性的不存在。所以,一定要依附于传统编译器,它一定是一个副产品。
Template metaprogramming was, in a sense, discovered accidentally.真的吗?这后面的趣闻是什么?
Historically TMP is something of an accident; it was discovered during the process of standardizing the C++ language that its template system happens to be Turing-complete, i.e., capable in principle of computing anything that is computable. The first concrete demonstration of this was a program written by Erwin Unruh, which computed prime numbers although it did not actually finish compiling: the list of prime numbers was part of an error message generated by the compiler on attempting to compile the code.[1] TMP has since advanced considerably, and is now a practical tool for library builders in C++, though its complexities mean that it is not generally appropriate for the majority of applications or systems programming contexts.我尝试编译这个世界上第一个metaprogram,结果还是出错,看来很多伟大的发现都是源于一个美丽的错误。
These metaprograms run before the load time of the code they manipulate. Precompilers: C/C++ precompiler. Open compilers: like writing transformations on AST (hygenic macros). Two level languages: Aspect J, C++ templates怎么理解呢?是纯粹逻辑上的概念?
The use of templates as a metaprogramming technique requires two distinct operations: a template must be defined, and a defined template must be instantiated.defined and instantiated似乎没有什么不可理解,但是在实际上两者是同时发生的,如果没有后者的需求前者也没有必要存在,这个是实际实现的现实需求决定的,不是逻辑上不可能,而是现实没有这个需求。不过如果把stl看作是defined,现实中的c++程序员难道都是在做metaprogramming的一部分?因为我们不过是把stl的模板instantiated而已?
Template metaprogramming is Turing-complete, meaning that any computation expressible by a computer program can be computed, in some form, by a template metaprogram.这个绝对是超出我的理解力的学术概念了,我在stackoverflow上看过这段话,明显是答题者摘录的。这里的Turing Completeness
In computability theory, a system of data-manipulation rules (such as a computer's instruction set, a programming language, or a cellular automaton) is said to be Turing-complete or computationally universal if it can be used to simulate any Turing machine. This means that this system is able to recognize or decide other data-manipulation rule sets. Turing completeness is used as a way to express the power of such a data-manipulation rule set. Virtually all programming languages today are Turing-complete. The concept is named after English mathematician and computer scientist Alan Turing.和Turing Machine的概念我还有一点模糊印象。但是我的记忆里它是automaton的高级版本吧?
A Turing machine is a mathematical model of computation that defines an abstract machine that manipulates symbols on a strip of tape according to a table of rules.总之,我觉得作为一个普通人知道这一句就够了
Virtually all programming languages today are Turing-complete.
Template metaprograms have no mutable variables— that is, no variable can change value once it has been initialized, therefore template metaprogramming can be seen as a form of functional programming.
Some common reasons to use templates are to implement generic programming (avoiding sections of code which are similar except for some minor variations) or to perform automatic compile-time optimization such as doing something once at compile time rather than every time the program is run这两个理由似乎就已经足够了,难道不是吗?难道有人幻想所谓的
自动编程?将来有机会让机器自动编程?
烧脑的地方就是这个递归定义,它让人看了目眩 我应该是之前没有看懂,现在也觉得有些难懂,因为我的头脑里有一个观念就是函数可以递归定义在定义里调用自己,但是结构难道也可以在继承上递归定义吗?也许我没有意识到模板结构的模板参数不同就意味着它已经不是同一个类型了,所以,这个并不是递归定义自己。也就是说结构继承了一个
堂兄而不是
自己因为模板参数已经不同了。
费米悖论一样的让人困惑,现在在《三体》里都做了一种解答,生命看似对于自然环境的要求如此苛求让现代人类认为生命产生的条件在概率上如此的小以至于出现了智慧设计的理论,而大刘说生命反过来对于它所处的环境也有反作用以至于我们错误的把目前的生存环境当作了原因而不是互作用的结果。联想到今天还在肆虐的病毒让我们看到了生命顽强的一面,对于病毒这种半生命半非生命的物质我们也许没有意识到在上古的营养汤里大量的有机质无机质的相互作用的二十亿年里不仅孕育了最原始的生命也不断的尝试生命可能生存的环境参数,我们仅仅是无数试错的一个结果。当然作为智慧设计信徒看来这个正是不可能的地方。对于如此巨大的时间尺度下我们人类是没有真实的观感的。
四月二十日 等待变化等待机会
吾尝终日而思也,不如须臾之所学。曾经看到c++语法书里说操作符的优先级没有在语法中
显式的体现,当时心中有些惶恐不知什么意思,其实现在看到这个例子就知道在BNF里体现优先级并不是什么很高深的东西,看这个例子就明白乘除的高优先级是怎么体现的。
exp: factor
| exp ADD factor { $$ = $1 + $3; }
| exp SUB factor { $$ = $1 - $3; }
;
factor: term
| factor MUL term { $$ = $1 * $3; }
| factor DIV term { $$ = $1 / $3; }
;
term: NUMBER
| ABS term { $$ = $2 >= 0? $2 : - $2; }
;
四月二十一日 等待变化等待机会
Using google, I only found that C can be perfectly parsed with LR(1) but C++ requires LR(∞).
wave实现的一个cpp,而它提到使用boost的库来实现是一个看起来更好的实现路径。我实在是孤陋寡闻,因为wave和spirit一样是boost的成员了。
再次搜索(re-search)假如没有对前人的搜索结果不做基本的评定也许也会错失发现前人遗漏的机会,因此,适度的重新体验前人的辛劳才能体会今日的难得,所谓不忘初心方得始终就是这个意思。因此,我一点儿也不觉得我做错了什么。相反,我觉得至少在cpp这个领域使用cpplib是一个可靠的选择,因为它是gcc的一部分,而且gcc预先定义的那些宏开关和预处理器的实现是无关的,你即便使用wave实现了一个cpp,依然需要设定那些builtin的宏开关。当然这和cpplib无关,只不过它在gcc内部使用其原生的机制更可靠一些,尽管我之前的实践似乎表明这个路径极其的复杂和不切实际。
Only today we begin to understand, that preprocessor generative metaprogramming combined with template metaprogramming in C++ is by far one of the most powerful compile-time reflection/metaprogramming facilities that any language has ever supported.这段话的真正的含义我肯定不可能在可视的将来能够真正体会的出。
四月二十二日 等待变化等待机会
奇怪的风格常常能颠覆我的看法(options_description_easy_init),原来程序也可以这样写,真好似武侠小说里一个初出茅庐的武学新手看到武林宗师把一些匪夷所思的拳经剑法演绎的淋漓尽致让人叹为观止:原来程序也可以这样子写啊!
僵卧蒙城难自哀, 但悲何时苦尽来。 枯藤有意缘墙势, 残碧难圆寸草心。
四月二十三日 等待变化等待机会
We are going to have to act If we want to live in a different world There is a very unstable situation on the ground That is unfolding very quickly Move toward more ideas that would help, uh Bring this thing to an end We are going to have to act We are going to have to act There is a very unstable situation on the ground That is unfolding very quickly
四月二十四日 等待变化等待机会
类c程序员,因为大部分的难点都不在这类地方,实际上现在流行的编程流派似乎认为遥远的微软那种在运行期都不知道对象的类型的编程场景的现象其实是不多的,程序员依靠继承来实现运行期多态的做法有一定的应用场景,但是更多的在boost里体现的是另类的风格。比如用模板来实现的
开放式的编程。比如在遥远的年代openGL设定一个黑箱子的context通常使用一个void*指针,但是如何扩展和操纵是完全的不透明的API函数才能操纵,因为这个context实在是太不透明了,只能通过方法来暴露功能。而方法有时候是僵硬的,一旦分发者使用二进制码就是固化的。在boost这样子尽量使用头文件的开放工程要怎么做呢?使用模板参数,而模板参数几乎是万能的回调函数,而配合所谓的
hook这种回调函数来注册达到类似的回调函数的功能。这听上去像是废话,这里面的编程者的行话可以说这些hook是functor也可以说是policy,总之能够按照设计者指定的行为方式来让继任者个性化,你也可以说这就是继承,但是对于不透明的context的void*指针是否是一种进步呢?我以为是增加了类型的检查,虽然回调函数有一定的函数调用参数约束,但是毕竟通过某种高级技巧也许可以有更大的灵活性。它的本质在我看来就是那种
静态继承
The curiously recurring template pattern (CRTP) is an idiom in C++ in which a class继承者必须遵循继承来的模板参数类所定义调用方法,最大的好处是省却了据说昂贵的运行期虚方法表的获取。而假如hook或者说policy使用boost::any也许可以允许任意类型的模板参数,当然它毕竟是回调函数最起码的参数传递还是有的,没有可能真的任意,除非它不需要什么额外的参数?Xderives from a class template instantiation usingXitself as a template argument.[1] More generally it is known as F-bound polymorphism, and it is a form of F-bounded quantification.
四月二十五日 等待变化等待机会
纸在伦敦上流社会里呼风唤雨,不仅白吃白喝,还赢得众多名媛贵妇的青睐,并且单单靠不用投入一分钱的背书就赚取了常人难以想像的投资收入。一个月后那两个开玩笑打赌的银行家回来收回那张神奇的
百万英镑的钞票的时候,这个穷小子已经赚取了一大笔钱。这中间起作用的是那张不能兑现的
百万英镑的钞票的信用和预期,无数人被之折服的背后的力量是两个超级富翁银行家的信用在这张纸上的背书,由此引发的是穷小子身边人们的预期,短短一个月时间,相当于银行家给了穷小子一个一百万英镑的
贷款额度,尽管他并
信用在使然。货币归根结底的本质是信用,而影响信用的因素很多,有人说是预期收入也就是还款能力及其还款历史作为信用记录积分。这无疑是正确的,但是还有很多其他的因素使然,比如在众多的国际货币里它们作为交易的手段固然是基础属性,而作为投资回报的标的物则越来越成为主要因素,国际上巨大的和国际贸易交易需求不成比例的货币在流动中,一方面促成了国际资本投资国际贸易结算,但是更多的成为了投资对象本身,当一国货币能够带来更多的投资回报的时候,国际资本对于这个国家货币的滥发是有容忍度的。那么什么时候这个容忍度会达到极限呢?其中一个因素一定是这个国家中央银行超发货币的效率。美国经济今天之所以叫做债务经济的根本原因是因为它的全部增长都已经来自于借债,大多数人对此没有深刻认识的原因不仅仅是因为被美国经济在很多领域里还表现了增长所迷惑,更主要的是没有意识到美国国际整体经济GDP每年全部增长甚至比美国从联邦到各个地方以及个人所新增债务还低,比如以美国整体经济规模大体上20万亿美元为例,它的经济增长基本上就是2%左右,折合4000亿美元,还不及美国联邦政府一年的财政赤字,更不要说地方政府以及企业和个人新增的债务,这些债务的本质可以想像就是美国全体人民不吃不喝应该靠新增加的借贷也应该增长至少2%以上很多,换言之,美国全体人民以及公司企业政府部门闲坐了一年也能实现这个2%的增长,那么忙忙碌碌难道是白忙了吗?也就是说美国的经济在持续萎缩!不靠借债经济就会大幅萎缩,这个也是所有即将破产的企业和个人的典型特征,收不抵支日常开支靠借债维持,至于说能够维持多久完全取决于那个借债的额度的多少。回过头来说美元滥发的极限必定就是无法继续维持所谓的
表面上的增长,当今无数的企业与个人都在玩的日复一日的游戏,只要你能
营造出一种增长的表象,那么你就可以从投资人那里获得新的贷款,或者从你那张信用卡里支取新的借债。所以,美元的终极发生在美国依靠债务驱动增长模式的终极,这个是可以想像的,因为随着债务的累加新增债务驱动增长的阻力是越来越大,这个阻力不仅来自于债务本身的利息,更来自于随着
增长后规模更大的美国经济的再增长的困难,这不仅要求持续加大的债务投入,更加可怕的是来自于新兴大国类似的债务驱动的效率的竞争。同样的债务驱动,如果效率更高就意味着它会把本来国际资本给美国的额度吸引过去,这个也说明了中美竞争不可避免的一个本质问题,崛起的中国不仅仅是它的人民要消耗掉美国人民在地球食物链顶端的资源,更加要挤兑美国债务增长驱动经济增长的借债额度,而这一点没有比一山不容二虎更加简单明了了。总而言之美元滥发的阻力来自于它自身维持债务驱动增长模式的阻力,当债务的利息抵消了大部分的增长,当债务投入增长回报不成比例,显而易见的是有一天人们意识到与其政府把那么多的债务投入创办企业发展经济还不如直接发给人民消费来的轻松的时候,世界和资本是会无情的抛弃美利坚的。更主要的是当国际资本发现有另一种货币能够带来更加稳定高速的回报的时候,美元滥发的机制就被自动刹车系统锁死了。这个另外的竞争货币无疑是人民币,原因不仅仅是货币背后代表的经济增长预期,还有更加重要的是透过数字人民币体现的严格的财政纪律所带来的信用。也就是人们常说的信用比黄金还宝贵。并不是加密货币本身的技术来实现所谓的信用,因为我们已经看到比特币并不能自律,自律要依靠发行者的强力干预才有可能达成。从这一点来看我觉得今天的bitcoin已经证明了创立者的初衷是失败的,那就是用技术手段来强制实现原本需要人的意志来达到的自律性,因为尽管加密货币在技术上本身解决了发行总量不会滥发的问题,但是它忽略了一个货币所代表的人类社会基本的事实:那就是人类通过不断的劳动是在不断创造新的价值。那么发行总额忽视这个基本事实把人类社会总的财富僵化的认为一成不变就必然导致比特币的不断升值,而这个做法实际上是让比特币的早期持有者收割后来者的财富的一种类似于
金字塔式的传销模式,由此带来的和中国炒房团一样的简单低级的盈利模式。它的结果就是这种击鼓传花的财富增值模式必然导致投机者不断推高比特币币值直到最后因太高造成的恐慌性的抛售盈利的彻底崩溃。
魔兽世界里的虚拟金币的贬值有异曲同工之效,因为前者是因为总发行量限定导致过多的实体货币投入流通导致货币升值,而后者是众多中国玩家
生产劳动创造出更多的金币导致总量增加的通货膨胀。这两者一正一反恰恰说明了一个货币的本质属性就是不断增长的属性,换言之适当的通货膨胀是货币本身的属性因为根本原因是使用货币的人类的不断的劳动创造增加的价值。所以,从这个角度来看单纯的期待美元滥发会很快停止是不现实的,因为它单单靠自然的通货膨胀就能够维持一定程度的增发很多年,这个和今天的英国英镑很像,一个垂死的昔日大国依靠它过去的积累的信用就能维持一个货币这么多年的增发而不垮台。可见维持一个信用不容易,但是摧毁一个成熟的信用也不容易。所以,货币滥发最根本的阻力机制还是来自于货币背后的劳动者的劳动创造能力的降低,假如美国人民有一天全体都采取
养猪模式依靠纯粹的消费/借债驱动增长那么它的阻力总有一天要超过增长带来的驱动力,因为你固然可以依靠提高各种消费服务价格来提高增长回报,但是来自于其他国家的同质服务价格竞争会自然拉低这个做法,更重要的一点是非服务性商品的价格往往不那么依赖于人力价格,比如固定商品价格取决于原材料价格,生产设备,劳动生产率等等,而国际比较价格更容易通过进口来阻止本国通过拉高人力成本造成的虚高商品价格,这一点在美国制造业外移表现的尤为明显。这个正像今年拜登政府数困法案试图提高最低工资水平被否决一样,民主党试图通过提高服务价格水平来维持增长的小伎俩在共和党看来无异于更快的减少债务驱动增长的上限空间使得这个
货币滥发终极摩擦力提前增大到平衡的那一刻的到来。
智子也许理论上可以监听地球上所有人的任何言行,其他不知名的领悟者也会被秘密处死,但是三体人在水滴探测器到达地球之前必须要借助于
三体地球组织来实施,而三体人又不想因为扑灭这个想法而让他为世人所意识到,所以,肉体消灭罗辑必须伪装成自然死亡。相反的,美元霸权的终极毁灭是一个世人皆知的公开秘密,谈不上为此杀人灭口,美国政府唯一能够做的是怎么阻止那个新兴大国来分割它那张永远不能兑现的空头支票式的
百万英镑的举债额度。这就是中美大国竞争的本质原因。
四月二十六日 等待变化等待机会
跨namespace那么简单组合就能实现的,它是一个非要在编译链接阶段才能实现的全新的功能,但是它的实现是依赖于对c++的语义理解而不是在预处理器能够做到的,所以,索性根本就不应该让预处理器了解。但是这个部分实在是太复杂了,我语法看了一头雾水,简直就是天书。
A module unit is a translation unit that contains a module-declaration.它的核心作用在于声明module,所以,要明白细节就去看一下module-declaration,而这一部分就相当相当的复杂,我决定暂时不关心具体细节,因为其中有好几个小节,比如module interface和module partition两种不同的模式,而单单它们的组合就能变换出四种不同的形式。我应该先掌握大图景,而不能陷入细节的泥潭!
Module partitions can be imported only by other module units in the same module但是它们的复杂程度在于它们并非并列关系,也就是说module interface的确是一个起到对外的
声明的职能,而module partition更多的是内部module实现的方便工具,因为在module内部可以import module partition,而只能在同一个module才能import module partition,说明这个是内部实现的工具,而module partition一旦出现在module interface里,则也必须暴露给外界了。这里的关系是否我理解的正确呢?而且看起来这个partition在外界是透明的也就是说外界看不到同一个module里被partition了。 这里最最重要的是module partition是开头有这个冒号:!!!
正交orthogonal的!它们互相联系,但是两者是独立且经常是交叉的,否则的话就没有必要引入module了,不是吗?所以,当我们import一个module之后它在那里呢?是另一个module吗?当然是,但是从namespace的角度来看呢?这就是这个说明的必要性,我看这些经常脑子感觉不够用,因为这个是在两个维度(dimension)出现的概念,或者说概念空间里的两个维度。 那么import declaration究竟是什么呢?
imports a set of translation units我觉得这个就是它的核心作用。就是把一个translation unit引进来,而所谓的translation unit是在语法parsing的一个概念了,我觉得它可以包含几乎全部,看过gcc的那段著名的代码就明白,在gcc/cp/parse.c里的核心就是cp_parser_translation_unit的实现部分,就是一个无限循环直到文件尾,一个语法单元要么是声明部分要么就是实现部分,这两个就构成了整个translation unit,当然具体比这个复杂的多,牵涉到比如在中间如果出现了extern "C"还要在c与c++语法的上下文切换,而且遇到namespace也要嵌套,但是总的来说无论函数声明等等都是一个个概念上的translation unit。明白了这一层才能意识到import的用意,也才能理解引入module的本意,它超出了简单的语法概念,我的意思是它试图在逻辑层面来分割程序,而且很有可能是在二进制码的层面上来实现,也就是说在链接阶段有工作要做?这一点我们随后来证实或者证伪。
a CMI(Compiled Module Interface) is generated during the compilation of a module interface unit.那么module interface unit文件是提供给用户的制作者和使用者之间的
合同,它存放在哪里呢?
四月二十七日 等待变化等待机会
什么和
怎么样,而不大会再去解释
为什么,当然少数关键的所谓的
notes还是有的,但是不是为了给普通读者来解释一般常识性的背景。所以这里阅读原来的proposal反而更有帮助。
这里的module unit和translation unit是同义词了。但是这并不能解决多少问题,因为对于translation unit本身的定义我并不清楚,似乎提到了phase1-phase7的结果,但是这个是什么我一无所知,Rule 1
A translation unit may contain at most one module declaration, and any such declaration must come first. The resulting translation unit is referred to as a module unit.
a mod- ule unit acts semantically as if it is the result of fully processing a translation unit from translation phases 1 through 7 as formally defined by the C++ standards总而言之,从语法上看是这样子的
translation-unit: module-unit toplevel-declaration-seq
a collection of related translation units, a module, with well-defined set of entry points (external names) called the module’s interface.
a module unit should be immune to macros and any preprocessor directives in effect in the translation unit in which it is imported.
the order of consecutive import declarations should be irrelevant.它的好处是并非我都认识到了
This enables a C++ implementation to separately translate individual modules, cache the results, and reuse them; therefore potentially bringing significant build time improvements. This contrasts with the current source file inclusion model that generally requires re-processing of the same program text over and over.
The primary purpose of a module system is to allow independent components to be developed independently (usually by distinct individuals or organizations) and combined seamlessly to build programs.这个是不是软件开发的终极目标呢?只不过这个是在功能上,在二进制码上的独立吗?还是我没有真的理解,这个似乎是在分发sdk上?我看了作者给出的例子,
without ODR violation because each non-exported symbol is owned by the containing module.,这里module是不需要解决linking吧?还是说这个内部实现函数都是类似于static的不用暴露的,这个理解我比较容易接受因为微软以前就是这样子的export动态库的函数的,不是吗?
四月二十八日 等待变化等待机会
四月二十九日 等待变化等待机会
${CXX_INSTALL}/bin/g++ -std=c++2a -fmessage-length=0 -g3 -Wall -fPIC -Winvalid-pch -x c++-header ${CXX_INSTALL}/include/c++/10.2.0/x86_64-pc-linux-gnu/bits/stdc++.h -o stdc++.h.gch
${CXX_INSTALL}/bin/g++ -H -std=c++2a -fmessage-length=0 -g3 -Wall -fPIC -Winvalid-pch -x c++ -include stdc++.h -I. src/gchTest.cpp -o Debug/gchTest
四月三十日 等待变化等待机会
空天军在不声不响的推进。相比美国俄罗斯的大鸣大放中国是更加的实打实做事。想想看空间实验室将来不仅是科研而是太空基地就明白了。
阿三(libasan)很头疼,一方面它是内存检查的利器,对于内存越界泄漏的检测是神器,但是由于我使用最新版的编译器动态库要重新部署很烦恼,直到发现它是可以静态链接-static-libasan的才解决。回想起来这个库是很特殊的,不是在用户层面使用-l能够指示的,这个应该就是我当初始终无法静态链接的原因,毕竟这个是非常的神奇的部分。
五月一日 等待变化等待机会
half runtime pair的真实含义,这里也是为什么要定义那些只有forward声明却不需要实现定义的空结构的意涵,他们纯粹就是作为key而存在的,而pair实际上不需要第一个key的实例,所以,make_pair把它们作为模板参数实例化第二个实参,
index获取pair说明了它的get的和tuple的相似,但是从逻辑上来说我觉得使用tuple来实现也是有可能的吧?无非就是另一个typedef?不不不,因为要实现at_key我不知道原始的tuple是否可能,应该是不行吧?这里的所谓的call/apply概念我还没有建立起来,这些都是mpl的要补课的地方。只不过这里我想记录的是mpl的namespace必须是boost,因为在using namespace boost::fusion;下编译器不可能明白这个新的namespace,总之我觉得boost里namespace是最tricky的地方。因为fusion下面也有mpl,但是那个是在boost下直接添加进去mpl的相当于说一部分mpl的实现是在fusion下添加的,这个做法是迫不得已,因为两个是双体婴儿,但是通常来说大家都不愿意踏足别人的namespace。这个是例外,因为它们是一体的。 补足例子是一个很好的学习过程,先贤们写文档的时候不可能写给所有的9岁小孩子的,因为说不定他的读者里有其他领域的大师,所以,众口难调啊。
五月二日 等待变化等待机会
#if defined(__GNUC__) && (__GNUC__ >= 7)
# pragma GCC diagnostic push
# pragma GCC diagnostic ignored "-Wbool-operation" // '~' on an expression of type bool
#endif
五月三日 等待变化等待机会
副产品到达SFINAE的目的。
I get the general idea: if nullptr cannot be statically casted to a pointer to a function returning T, it will be considered a failure (and not an error) so calling test_returnable will take the second overloaded function and return std::false_type.我无法说出比他更贴切的解释。但是我们俩的核心问题都在于什么样的类型是无法返回的?我以前怎么丝毫没有意识到数组是不能被返回的呢?我一定是一直在函数的参数上使用指针,所以从来没有意识到通常也有人喜欢传递强类型的数组类型,而这个时候就遇到返回值的问题了。比如我还是不熟悉怎么传递一个数组的引用的 那么这样子就明白什么是不允许返回的了。这位大侠其实答的是最准确的我却将信将疑。而且发现大家流行使用https://godbolt.org,我在演讲中听到过大侠们对于它的推崇,只是我还想不透它到底玄机在哪里?应该不仅仅是在线编译的虚拟机那么简单吧?不然人人都能做到了?总而言之,数组是不能返回的 ,而对于类,
You cannot make a class type that is constructable but not returnable.我想即便没有ctor的类在使用std::declval的情况下也是可以获得值的,更何况获得它的类型呢?至于说variadic argument的问题,我觉得我可以理解提问者的疑惑因为我也有类似的感觉,就是即便你要调用第一种模式你也要给一个假参数0,这一点我没有意识到结果没有给任何参数结果就是总是返回第二个结果std::false_type,所以,回答者的这个包装很能说明问题的核心 我对于这一行代码还是非常的佩服的因为它抓住了核心,我一开始并没有领悟到!
If libstdc++ is available as a shared library, and the -static option is not used, then this links against the shared version of libstdc++.这个做法不适合于我因为我有
阿三libasan当我使用-static的时候,编译器报错说
error: cannot specify -static with -fsanitize=address,所以,这个是我唯一的选择。
struct S { typedef void (*p)(); operator p(); };
请问p是什么类型?operator p()的返回类型是什么?例子里的错误要怎么改正?这个问题看似不复杂因为void (*q)() = S();
这个肯定是可以的,但是我感到疑惑的是S()是conversion operator在default ctor之后起作用吗?似乎是的吧? 当我做以下测试的时候 我得到了错误undefined reference to `test6()::S::operator void (*)()()',这个当然是因为函数只有声明没有实现,我当然可以简单的实现一下 我从来没有写过这么个函数指针的初始化方法,当然不用声明变量直接返回return nullptr;也是可以满足编译器要求实现的。问题是我能不能使用declval来绕过它呢? 我认为我的理解是对的 我对照这个例子对于一个虚函数你可以,对于一个没有实现的函数当然也是可以的了。 总而言之这两个做法是等价的
void(&)(int)
的确是一个函数引用,这个是我的证明 那么函数引用要怎么调用呢?我对于类似的问题似乎不止一次的感到困惑,这里是摘抄的实验。其中的回答我看不太懂,这里的退化我不是很确定,语法里似乎看到过,但是。。。 对于这个解释我还是有些将信将疑Functions and function references (i.e. id-expressions of those types) decay into function pointers almost immediately, so the expressions func and f_ref actually become function pointers in your case.如果函数名和函数引用已经是一样了,那么为什么多次的deference还是成立呢?(****f_ref)(4);
"Why function pointer does not require dereferencing?"这个解释我理解起来有困难。Because the function identifier itself is actually a pointer to the function already:
4.3 Function-to-pointer conversion
§1 An lvalue of function typeTcan be converted to an rvalue of type “pointer toT.” The result is a pointer to the function.
五月四日 等待变化等待机会
副产品是否成立决定了逗号后面的结果是否能够返回,而这里内心要始终默念那句六字箴言
Substitution Failure Is Not A Error!编译器不会报错!不会报错!不会报错!编译器只会静静的尝试下一个two而这个是一个generic的模板是永远成立!再次,那么既然返回two的test永远成立那么是否这两个模板函数声明的顺序会影响编译器尝试的顺序呢?不会的,因为我们故意定义one的参数是int,而two的参数是不定,这一点决定是模板的specialization更加把one作为首选!这个就是定义模板函数实参类型的必要性!重要!重要!重要! 最后一点是不言而喻的,我们对于函数感兴趣的地方只有返回值,因为sizeof对于函数来说实际上测量的是函数的返回值,所以,使用decltype来定义函数的返回值来实现就是一个明显的选择。最后一点就是说这个老套的做法已经不时新了,因为既然我们关心的是返回值何必要依靠返回值的sizeof来多此一举,直接使用true/false不是更加的直接了当吗?而且新派的做法是根本就直接继承自std::integral_constant,让代码更加的简洁和容易将来扩展!
语法正确的方式使用外边包裹一个神奇的void(),但是这个是什么我依然不清楚。从第二种使用新版requires关键字的实现方式来看,在大挂号里直接调用函数是检验语法是否成立的一种方式,这个省却了
逗号表达式的初始化副产品。 而且新版关键字noexcept能够大大简化目标代码的生成。至于说检验returnable的方式也更加的直观了就是直接使用static_cast。直接使用requires的关键字省却了利用编译器特殊性的SFINEA的奇技淫巧,那种在函数声明返回值里使用逗号表达式给我的感觉是
螄螺壳里做道场。
拿来主义的牺牲品。总而言之,我发现这个智能拼音底子并不差,我只要找到正确的词库来更新就好了。这里有一个号称转换各家词库的软件,不过我还懒得看源代码。倒是这一个博客关于智能拼音配置文件值得看看。总之,我目前知道用户数据导入导出用户界面可以添加我的个人习惯词库。不知道是不是一样的。此外sqlite3的命令行工具直接操作数据库也是一个好东西。
五月五日 等待变化等待机会
phoenix的原因吗?如果没有这个push_back我又会卡壳的,因为boost::lambda也未必可以吧?其中如果要使用phoenix::push_back也要一起使用phoenix::ref,也许内部和boost::ref甚至于std::ref都没有差别,可是谁知道呢?现在我的头脑被spirit/phoenix/fusion/mpl缠得一团浆糊,谁是谁也分不清楚。
几乎
五月六日 等待变化等待机会
expecting我实在是难以理解。这里是几乎所有的操作符重载的表,这个比例子里的无序的介绍要清晰的多了。
一幅画就是一首诗,一首诗就是一幅画。一个时代是千千万万的画卷的展开,一幅幅画卷是一个个鲜活的人生。生长于一个大时代是有幸的因为你可以亲眼目睹沧海桑田;沉浮于一个大时代又是不幸的因为你会用一生来看倦潮起潮落。幸与不幸要跟谁人诉说?也许只有刘慈欣的“最璀璨的银河”可以让后人了解这个大时代变迁的亮度。竹石
咬定青山不放松,
立根原在破岩中。
千磨万击还坚劲,
任尔东西南北风。

五月七日 等待变化等待机会
model的思想,感觉这个和新feature里requires有异曲同工之效,这种思想我现在还只能慢慢体会。
八国联军连那个躲在角落里的印度也是作为英国的殖民地参与其中,所以这里赫然醒目的
侵略者联盟(Invader)就明白了这些当年的帝国主义今天开会就是要讨论能不能建造时间机器回到当年的辉煌时代。时间机器是空想,联合声明也是吓唬人的空谈。

lit, like string, also matches a string of characters. The main difference is that lit does not synthesize an attribute.
五月九日 等待变化等待机会
科学边界,那么对于个体是否也存在呢?一个人的精力能力与意愿应该都是这个边界的因素,甚至是健康状况也是一个制约因素。对于这个操作符&的重载,其意义我有疑惑,究竟什么才是
If the predicate a matches, return a zero length match. Otherwise, fail.我把测试例子稍稍修改 这里我实验了一下epsilon作为debug的功能,它的[]操作符重载接受一个functor返回值为bool,所以,我去定义了一个简单的error 我曾经想直接在[]里声明我的lambda,但是直接嵌套[[]]不行?也许是因为操作符[]已经被重载了,这个难道会对于lambda的语法产生混淆吗?要知道lambda是语言本身的特性啊!我最初的疑惑是那个原始的&操作符并不能保证;是结尾的输入,至少test_phrase_parser的第二个参数是false制止了对于输入的完整的扫描。具体的功能是什么要看原始的定义,那个例子的说明是作者的想像发挥了。当然我是吹毛求疵了作者仅仅是说功能是验证最后一个输入字符,这里显然指的是空白字符之后,我去自己理解为一行输入的最后。
Using on_error(), that exception can be handled by calling a handler with the context at which the parsing failed can be reported.我的理解是on_error是
五月十日 等待变化等待机会
The rule is a polymorphic parser that acts as a named placeholder capturing the behavior of a Parsing Expression Grammar expression assigned to it. Naming a Parsing Expression Grammar expression allows it to be referenced later and makes it possible for the rule to call itself. This is one of the most important mechanisms and the reason behind the word "recursive" in recursive descent parsing.那么grammar是什么?grammar是rule的组合,当然也包含比rule更原始的primitive parser。
The grammar encapsulates a set of rules (as well as primitive parsers (PrimitiveParser) and sub-grammars). The grammar is the main mechanism for modularization and composition. Grammars can be composed to form more complex grammars.但是当你写一个expression你能分辨谁是rule谁是grammar呢?我觉得这个继承并没有什么内存分配释放的问题。
五月十一日 等待变化等待机会
五月十二日 等待变化等待机会
融会贯通所以才起名叫做fusion,就是
融合。所以,当然我其实是现在才想到这一点的,因为以前看到的例子都是看到直接把普通的std::vector传递进去,当然这个肯定是一组同类型的结果了,这个可能性不是没有毕竟比较少,如果都是一个类型的话估计使用parser的意义也不大了,毕竟就简单了嘛。可是这个看似理所当然的事情我却没有意识到,因为这个本来是应该传递类型我却传递了一个stl的vector的实例,这个现在看起来当然也是有道理的,因为这个自然是
类型推导才能做到的。可是如果脑子不清楚看到两个例子摆在一起的话,你是否像我一样的发出惊叹呢? 没有对比就没有伤害对人类来说应该是没有对比就没有认识。人类认识世界的唯一途经是依赖于认识图景的不同,而最直观的差别对比是最基本的方法。
五月十四日 等待变化等待机会
五月十五日 等待变化等待机会
过滤unused这类无用的attribute,所以,看到这个解说我是立刻得到豁然开朗的感觉。
Traditionally, symbol table management is maintained separately outside the BNF grammar through semantic actions. Contrary to standard practice, the Spirit symbol table class symbols is a parser. An object of which may be used anywhere in the EBNF grammar specification. It is an example of a dynamic parser. A dynamic parser is characterized by its ability to modify its behavior at run time. Initially, an empty symbols object matches nothing. At any time, symbols may be added or removed, thus, dynamically altering its behavior.怎么理解呢?首先symbol table是什么呢?我的理解就是AST里的节点名字,那么既然已经是到了AST阶段当然是semantic action了,那么对于EBNF来说本质上是语法的检验是抽象的语法元素的并非实际的输入,所以,照例说不应该有symbol table的存在,因为那个是实际使用parser的运行期建立的,可是spirit是一个很特殊的parser,它的建立也许就是parser的使用,两者是在同一个编译过程。与之对比的是flex/bison模式是先产生parser的代码再进行编译的两个阶段。至于说dynamic parser从数据结构的角度来说并没有什么很深奥的道理,只不过因为parser本身的特殊性导致了symbol table的表面上看起来是动态的,试想连parser本身也是动态的就不奇怪了。
五月十七日 等待变化等待机会
字符印象深刻,因为不论是长度为1或者2,或者3,或者4,可是这里我还是犯糊涂就是我始终认为中文大部分都是3个字符,那么它是怎么表达成2个字符的呢?这里也许是我的误解吧?只是我想不清楚,不过有一点我算是搞明白了,所谓的wchar_t的长度居然是4,也就是说传说中的都是真的,实际上就是把多字节字符当作整数来处理的。
五月十八日 等待变化等待机会
科技猿人的文章谈到人工智能的发展前景,中心思想是可能人们低估了它的困难度,我有些赞成,最关键的一点是否可能量变积累能够导致质变。我在洗澡的时候在想如果能够实现所谓的
反射,比如GPT里设定了那么多的参数经过一段时间的强化学习是否可以输出增强的输入设置作为下一阶段或者同类机器的学习输入呢?肯定是在这么做的,比如alphaGO的学习结果可以作为下一代的Master的程序的强化学习的指导或者校验员,但是如果能够直接输出它的配置文件作为master的输入不是省却了这个起始化的学习过程吗?想法是好的关键是甲的输入无法成为乙的输入,根本没有什么通用的描述语言,如果spiriti之类的工具能够实现万能的parser也许可以动态的实现解析任何描述语言,可是世界上根本不可能存在这样的能力吧?我对于去年
李伟的那本Metaprogramming的能力至今没有理解到,在meta language层面实现所谓的
反馈究竟是什么意思呢?也许我应该继续学习那本书。只不过meta实在是太难了,首先就是工具,是否有什么好的编译器是专门针对meta programming呢?我好像google到一个。但是这个领域根本不是一般人能够涉足的领域。
This encoding characters has defined 20902 CJK characters. The advantage of using this standard is that you can display Simplified Chinese characters, Traditional Chinese characters, Korean characters and Japanese characters on the same HTML page. No other encoding standards is supporting that for the moment.我以前以为GB2312和unicode兼容,其实应该是很容易转换而已吧?
多么简单扼要,中英文混用没问题!关于GB18030远比我理解的深刻:GB (Guo Biao) Code is defined by China. It is the encoding standard used to represent Simplified Chinese characters. It has defined about 6763 Chinese characters (excluding all symbols). Countries such as China, Singapore and Malaysia are using this encoding standard.
Every Chinese character is represeneted by a two byte code. The MSB of both the first and second bytes are set. Thus, they can be easily identified from documents that contain both GB characters and regular ASCII characters.
The Chinese authority soon realized that it cannot ignore the traditional Chinese characters. Thus, it had defined GBK (Guo Biao Kuozhan) to include all the traditional Chinese characters defined in Big 5. It claims that GBK is synchronized with Unicode standard, version 1.1.不过我对于synchronized with Unicode standard的意思还是不太理解,是说补全了吗?关于大五码我的理解是编码的原理和GB是相似的,也许不同的地方在于没有包含所有的ascii符号,这一点在当初GB2312的说明文档里似乎是一个值得炫耀的因为它营造了一个纯中文编码的环境不需要中英文混杂。这个是有一点见仁见智吧,不过总的来说不是坏事。
下字的编码,它是CJK的编码不是utf-8,所以,怎么转换是一个要费事的工作,因为iconv根本不可能理解到这一个问题,这个就是当初我使用iconv批量转换GB2312到utf-8的时候漏掉的部分。
五月十九日 等待变化等待机会
五月二十三日 等待变化等待机会
五月二十四日 等待变化等待机会
五月二十六日 等待变化等待机会
guidance编译器会不知所措或者误解你的意思的。总之我避免了声明这样子的varaint类型因为这个是由使用者来决定的,比如 那么怎么使用这样子一个怪物呢?这里就明白visit的强大了,对于这个奇妙的函数我以前是不能理解的,因为只有真正的使用才能明白它是怎么样子解除你的痛苦,可是真正的理解它远远不止于这里,它的实现肯定现在对于我还是一个比较复杂的,我的体会是它让你可以自由的访问variant的各个可能的成员的一个通用方法,你不用再去自己写那些令人尴尬的index或者是捕捉异常的std::get等等if-switch之类的。总之visit把你可能遇到的variant的成员类型都包含了,剩下的就是你自己去写一个通用处理的方法了,这里有意思的就是假如我们的variant包含一些复杂的类型我要怎么处理呢?比如对于普通的POD类型我们可以轻易的使用std::cout输出,如果我定义个类比如这样子的无穷多种的模板结构 然后我生成了这么一个复杂的variant 我原本是可以在visit里这么自由输出变量 现在肯定是不可以了,因为很明显的新的结构是不支持的,我天真的想避开这个企图在visit的lambda里靠类型判断来避开编译错误比如 这个做法是不可能的尽管我使用了constexpr想让编译器对于结构做特殊处理,但是因为visit的实现机制导致这种类似于所谓的
虚方法的做法并不是一个真正的动态方法,它实际上是所谓的静态多态吧?这个是我的猜想总之唯一的解决方法是重载结构的operator 早晨起来,折腾了大半天感觉就像做了一些脑力体操,挺累的。
爱国者们,他们夙兴夜寐为他们所钟爱的祖国的前途所担心,作为
牧羊者他们有责任看护好
天选之民的国家国运长久,所以作为wakeup call,他们要用极端手段来唤醒美国民众给他们特权来保护他们,但是这个需要精确的数学计算到底要杀死多少美国人才能拯救多少美国人,这个是一个冷血的数学模型,比如蜘蛛993年俄克拉荷马的大爆炸死的人不够多,所以,恐怖主义的威胁没有引起美国人民的注意,因此要发动911恐怖攻击成为必要;而埃伯拉病毒同样没有引起美国人民对于生物战的重视,因此有必要发动这次世纪大瘟疫的生物战。具体实施者当然是极端伊斯兰恐怖分子,只不过中情局在恐怖组织的决策与执行机构的通讯中穿针引线帮助他们顺利实施而已,所以,严格说来的确是恐怖分子发动的,只不过在中情局的严密的监督下
成功实施而已。
五月二十七日 等待变化等待机会
指示std::in_place_index的话编译器会抱怨deduction之类的错误,这背后的机制很深奥,我还没有去看代码,估计会有困难吧?因为即便参数类型不需要转化的string也是会报错,所以,我不知道为什么不能依赖第一个匹配的类型而一定需要使用index来确定。
五月二十八日 等待变化等待机会
产生虚方法表是否是真的如同我们通常面向对象里编译器帮助产生的那样的虚方法表? 这里我先把这个神奇的overload万能类声明为一个变量。 然后制作一个lambda以便把variant当作函数参数传递进去, 我和原来的例子本质上没有变化,我仅仅想看看overloaded能不能在lambda或者函数里面依然能够根据传入的variant的正确类型来挑选相应的operator 其实,真正的硬核的代码是原来例子里的这个神奇的overloaded的定义,我现在才
再次意识到它是它constructor的传入的所有参数的子类,所以它是所有实参的子类,我以前错误的理解是
specialization,就是模板行为是编译期挑选最接近的类型,那么从现在使用lambda来看,以及实现代码来看我以为这个是动态的就是运行期的行为。这个variant的实现代码非常的复杂,我只能说它肯定是
动态选择的,当然constexpr也许可以让这个选择是编译期就决定,也就是针对里的各个类型提前选择相应的overloaded里的各个operator(),也许我可以gdb看看运行期到底有多少代码在执行?
Using-declarations can be used to introduce namespace members into other namespaces and block scopes, or to introduce base class members into derived class definitions, or to introduce enumerators into namespaces, block, and class scopes把基类的成员引进到子类定义里!我一直以为using仅仅是用来声明一个类就是替代typedef的新玩意,现在才意识到在没有引进新的类型的
别名的话它就是仅仅
引进到名字空间或者类的空间,这个是它最主要的功能之一啊!难怪我始终不理解using和using namespace的区别!但是作为基类的成员难道子类不能从继承的渠道为什么非要使用using来引进呢?struct所有成员不都是公开的吗?当我尝试把using Ts::operator()...;注释掉后我得到了编译错误
error: request for member ‘operator()’ is ambiguous看来这里并非访问空间的问题,而是explicitly使用的问题吧?这个错误很难看明白,但是最起码它的性质我有所明白了。
The class template std::integer_sequence represents a compile-time sequence of integers. When used as an argument to a function template, the parameter pack Ints can be deduced and used in pack expansion.作为模板类型,我们当然可以使用它的模板参数了,因为这个参数不是类型而是一个整型。然后是我们要帮助编译器认识到这个lambda的返回值是一个vector,否则当我们return {Seq...};的时候编译器会想当然的认为我们返回的是一个initializer_list,这个比vector更贴近编译器的想法。随后作为familiar template lambda的精髓就是立刻把make_index_sequence作为参数传给我们刚刚声明的这个lambda。我们之所以需要使用这个familiar template lambda的根本原因就在于从一个模板参数的一个整数转换为一个自然数列需要内嵌一个模板函数,只有使用make_index_sequence作为实参才能达到这个目的。 到此结束了吗?我又一次卡在了怎么调用模板lambda了,过了几个月之后我几乎忘记了作为lambda的模板参数你是针对这个所谓的lambda的唯一成员operator()的所谓成员函数模板,所以,现在就不难理解调用必须是这样子的
五月二十九日 等待变化等待机会
anyis a dressed-upvoid*.variantis a dressed-upunion.
anycannot store non-copy or non-move able types.variantcan.
Anyone who has been frustrated by statically typeless languages will understand the dangers of any.
究竟有多少种case呢?似乎在我天真的心底里只有简单的是或者不是两种case啊?在家还是不在家?难道还有薛定谔的猫一样的不确定状态,就是出错的状态吗?会吗?也许吧,因为variant实际上是一个type-safe的模式,当你把一个不兼容的类型赋值给variant的时候会出错的,这个错误不像any那样是内存不足造成的,是不可挽回的,不过这个应该是编译期就能发现吧?在运行期可能吗?我很怀疑,因为type-safe本身就说明了是编译期就能掌控了。比如这个根本也不能说是错误,只能是程序员强制转化得到垃圾结果,编译器是不会抗议的。variantguarantees that it contains one of a list of types (plus valueless by exception). It provides a way for you to guarantee that code operating on it considers every case in the variant withstd::visit; even every case for a pair ofvariants (or more).
五月三十日 等待变化等待机会
std::string s3{0x61, 'a'}; // initializer-list ctor is preferred to (int, char)
五月三十一日 等待变化等待机会
Otherwise, the constructors ofTare considered, in two phases:
- All constructors that take std::initializer_list as the only argument, or as the first argument if the remaining arguments have default values, are examined, and matched by overload resolution against a single argument of type std::initializer_list
- If the previous stage does not produce a match, all constructors of
Tparticipate in overload resolution against the set of arguments that consists of the elements of the braced-init-list, with the restriction that only non-narrowing conversions are allowed. If this stage produces an explicit constructor as the best match for a copy-list-initialization, compilation fails (note, in simple copy-initialization, explicit constructors are not considered at all).
second hello world second abcde05.08.2021,我过了三个月回头来看花了好久才明白是怎么回事,这里的关键是我不熟悉string的新版的ctor的一个形式就是参数是initializer_list的情况! 因为我们是
显式的调用了ctor而不是list_initialization,所以我本来预计这个会有歧义,可是居然没有! 它应该是上述情况的第二种就是进入了overload resolution阶段,首先参数'n','o','a', 'm','b','i','g','u','o','u','s'被作为string的参数成为initializaer_list<char> 而真正有歧义的是这样子的
显式的要求调用ctor而不是list_initialization,而参数本身{'a','m','b','i','g','u','o','u','s'}强调了它是一个initializer_list,它被convert成了一个string那么这样子首选的ctor当然是第一个,那么这样子有什么歧义呢?没有想到的是编译器认为还有第二种可能,我一开始没有想到,后来就想明白了,既然编译器能够接受MyStruct{'n','o','a', 'm','b','i','g','u','o','u','s'}那么在考虑overload conversion的时候它就也是一个选项,也就是说编译器认为copy constructor是另一个选项!换言之{'a','m','b','i','g','u','o','u','s'}已经被当作ctor创建了一个对象然后作为copy constructor的参数了!这个脑回路太长了吧! 05.08.2021但是当我声明强制禁止copy ctor的时候这个错误依然不能解决,这个难道是GCC的一个bug吗?事实上msvc根本就不认为这里有什么歧义,压根没有GCC的脑回路长,完全没有想到这里会牵扯到copy ctor。还是clang最好,因为它的错误信息是比较简单明了的,也是指出了copy ctor也是候选人,并且我试图delete它也是解决不了问题的。 这里的转换相当的复杂,比如一开始我认为这个无法解释因为{'a','m','b','i','g','u','o','u','s'}是否会顺理成章的解释为string呢?编译器否认了,因为作为一个
无名的这么一个braced-init-list编译器拒绝做任何的猜测,所以,从上下文来看就做出了。
六月一日 等待变化等待机会
出路,换言之就是一定要给编译器一个永远能够保证正确的last resort。否则,替换失败就不再是安静的走开,而是把错误浮出水面了,就达不到静静的选择一个无奈的选择。比如在这个try_add_lvalue_reference的一个实现范例里,为什么要提供一个人畜无害的永远正确的形似费话的选项呢? 原因是我们真正需要检验的这个选项有可能失败 有什么样的类型的引用类型会失败呢?换言之什么类型是不存在引用类型的类型呢?一个答案是void,这是一个热搜的题目,这里是一个比较不错的答案。总结来说就是void是一个good for nothing的类型,你不能合法的把它转换为其他任何有用的类型,当然这个是相对于c++程序员的,对于暴力的c程序员眼里一切都是浮云,因为一切都是一个地址而已,所以,一切都可以用一个void来代表,如果一个void代表不了,那么就用两个void代表:void**,也就是指针的指针。而在c++里,void也不能是一个函数指针,这里指的不是函数的返回类型,而是说在c++里几乎任何类型都支持一个称之为call operator就是anytype(),这个可以是类型的ctor,也可以是它的所谓的operator(),
假函数,我们仅仅指明它的返回值类型,而使用函数的返回值类型是metaprogramming的一个利器,很多难以实现的类型判断都要么是检验它作为函数返回类型或者参数类型的技巧来判断的。所以这个技巧就是我们要调用我们定义的模板try_add_lvalue_reference(0)以便明确指示编译器我们要用更加speicialization的形式,也就是参数类型明确是int,只有当它返回类型是非法的void&时候,编译器无声的放弃转而使用那个永远正确的万能形式。所以,明白了这一点才能看懂它的使用 当T不是void类型的时候我们的参数0强调我们优先使用了添加引用类型作为函数返回值,注意decltype对于一个函数来说永远指的是它的返回值。所以,我们得到了T的引用类型,可是当T是void的时候,我们只能得到它本身,所以,通过判断add_lvalue_reference的类型是否是void就可以了。这里有一个细节就是add_lvalue_reference使用了继承的做法而try_add_lvalue_reference指示的返回值类型是type_identity,我一开始脑子蒙了没有注意到这一点一直在怀疑为什么没有重定义type,因为这个是在type_identity里定义了!
这里之所以记录下来因为例子给出的实现远远比std的实现来的简洁,我不知道是否是完全正确,抑或是版本兼容等复杂问题,总之这个样本实现比实际代码要清晰简洁的多。
运行期免费的效率倍增器,我错误的认为所有的计算都是在编译期完成了,只要冠以constexpr的名义的话,似乎天上掉下了大馅饼,直到使用gdb跟踪了才意识到宾非如此,比如这个在chrono定义的系统定义的literal 对于这个__check_overflow我抱以很大希望认为是编译期检查的,有些简单的overflow是可以靠类型判断的,不是吗?实际上不完全是。看代码到这里我才意识到我的误解,对于chrono有两重的意思,如果是简单的代表时间的一天12/24小时的那个类似enum的当然可以简单的使用enum类型转换是否成功来检验,我几乎可以确定如果声明为constexpr是完全可以在编译期做类似一个meta utility function比如is_within_hourly_range之类的吧,应该不难。可是chrono另一重的含义是时长,也就是duration这个是几乎所有整数都可以代表的吧?(我模糊印象中因为最小的纳秒nano second是用整型表示所以最大的可能的分钟小时天等等就有一个天然的可能的上限,所以,这个检查就不太可能做到那么容易了,我不确定是否可以做到编译期的类型转换就能行? 我再浏览了一下代码我的感觉这个边际检查的确是编译期实现的,而且不是我所天真的以为的所谓的enum类型转换的思路,是实实在在的整数的范围的检查,相当的复杂,但是我至少可以放心的是大部分的计算的确是编译期完成的,不过运行期并非完全没有操作,因为总要返回一个结果吧,只不过计算都是编译期做的。这里代码看不懂的是overflow的检查是否仅仅是通常的整数类型的检查还是有针对小时分钟天的范围检查呢?似乎没有吧。这个太繁琐了还是留给程序员自己做吧?
六月二日 等待变化等待机会
sprintf / snprintfstringstreamto_stringitoa做后一个to_chars和from_chars能够做到互为逆函数也许是实现的难点吧?我怀疑这个是gcc没有实现的一个原因,应该不是我想像的实现者的偏见的因素,我这个人太主观了。
- non-throwing
- non-allocating
- no locale support
- memory safety
- error reporting gives additional information about the conversion outcome
- bound checked
- explicit round-trip guarantees - you can use
to_charsandfrom_charsto convert the number back and forth, and it will give you the exact binary representations. This is not guaranteed by other routines like printf/sscanf/itoa, etc.
六月三日 等待变化等待机会
for ( init-statementoptopt for-range-declaration : for-range-initializer ) statement我以前有时候会怀念旧版的counter,总在想两个如果能够结合就好了,因为总要额外在loop之外声明一个循环变量,现在才明白这个是可以在init-statement里声明的。看来不知道语法只是照猫画虎的模仿是不够的。 作为对比这个是我们从小就熟知的古老的for-loop
for ( init-statement conditionopt ; expressionopt ) statement其实我还是没有真正的理解这个语法,究竟
for-range-declaration : for-range-initializer代表什么呢? 首先for-range-declaration还没有什么特别的,因为就是一个变量的声明,基本上你都可以想像的出来的,当然实际上也可以很复杂,比如究竟要怎么声明所谓的declarator,但是最起码的今天我意识到 for-range-initializer可以是一个braced-init-list比如我从来没有想到过循环可以这么写 还有多少其他的可能呢?这个例子实际上告诉了你一部分吧?
幸福的,因为你有各种各样的新的玩意,比如braced-init-list可以自动替你初始化数组,这个在古老的c++98里就是不可能的,至于说模板能否自动推理类型我也不是很肯定。总之,现在的人生活的如此
幸福却完全感觉不到。
这其中的duck type我还是一知半解,它指的是对象不要求有一致的接口方法和继承关系吗?我却一直是往模板的类型隐藏方面去想。也许不是一个概念吧?Advantages of
std::variantpolymoprhism
- Value semantics, no dynamic allocation
- Easy to add a new “method”, you have to implement a new callable structure. No need to change the implementation of classes
- There’s no need for a base class, classes can be unrelated
- Duck typing: while virtual functions need to have the same signatures, it’s not the case when you call functions from the visitor. They might have a different number of argument, return types, etc. So that gives extra flexibility.
Disadvantages of
std::variantpolymorphism
- You need to know all the types upfront, at compile time. This forbids designs such as plugin system. It’s also hard to add new types, as that means changing the type of the variant and all the visitors.
- Might waste memory, as
std::varianthas the size which is the max size of the supported types. So if one type is 10 bytes, and another is 100 bytes, then each variant is at least 100 bytes. So potentially you lose 90 bytes.- Duck typing: it’s an advantage and also disadvantage, depending on the rules you need to enforce the functions and types.
- Each operation requires to write a separate visitor. Organising them might sometimes be an issue.
- Passing parameters is not as easy as with regular functions as
std::visitdoesn’t have any interface for it.
六月四日 等待变化等待机会
Name lookup is the procedure by which a name, when encountered in a program, is associated with the declaration that introduced it.看来函数的搜索是从参数开始的吗?我以为这可能是因为是operator<<造成的这个顺序吧?接下去的说明是For example, to compile std::cout << std::endl;, the compiler performs:
- unqualified name lookup for the name
std, which finds the declaration of namespace std in the header<iostream>- qualified name lookup for the name
cout, which finds a variable declaration in the namespacestd- qualified name lookup for the name
endl, which finds a function template declaration in the namespacestd- both argument-dependent lookup for the name
operator <<which finds multiple function template declarations in the namespace std and qualified name lookup for the namestd::ostream::operator<<which finds multiple member function declarations in classstd::ostream
For function and function template names, name lookup can associate multiple declarations with the same name, and may obtain additional declarations from argument-dependent lookup. Template argument deduction may also apply, and the set of declarations is passed to overload resolution, which selects the declaration that will be used. Member access rules, if applicable, are considered only after name lookup and overload resolution.所以,对于函数的解决是相当的复杂的运用了这么多的技术,能写出这样的技术档案的大牛很可能是实现者吧? 对于函数名以外的搜索似乎简单一些吧?
For all other names (variables, namespaces, classes, etc), name lookup must produce a single declaration in order for the program to compile. Lookup for a id in a scope finds all declarations of that name, with one exception, known as the "struct hack" or "type/non-type hiding": Within the same scope, some occurrences of a id may refer to a declaration of a class/struct/union/enum that is not a typedef, while all other occurrences of the same name either all refer to the same variable, non-static data member (since C++14), or enumerator, or they all refer to possibly overloaded function or function template names. In this case, there is no error, but the type name is hidden from lookup (the code must use elaborated type specifier to access it).看到这里我才明确什么是qualified name lookup
If the name appears immediately to the right of the scope resolution operator :: or possibly after :: followed by the disambiguating keyword template.所以,所谓的qualified identifier包含了
- class member (including static and non-static functions, types, templates, etc)
- namespace member (including another namespace)
- enumerator
自主创新的倡导的
中文编码吗? 你觉得这个代码编译不行吗?这么做的好处是代码完全中文化可以保证以中文为母语的程序员的工作岗位,这个制度一旦在一个公司确立可以很大程度上确保自有知识产权的可靠性,因为这么大量的代码如果几乎都是以中文来命名变量与函数的话,非中文程序员读代码将是一件非常困难的事情,这无形中就是一个知识产权的
额外的保护。
| Code points | Description | Characters |
|---|---|---|
| U+00A8 | DIARESIS | ¨
|
| U+00AA | FEMININE ORDINAL INDICATOR | ª
|
| U+00AD | SOFT HYPHEN |
|
| U+00AF | MACRON | ¯
|
| U+00B2 - U+00B5 | SUPERSCRIPT TWO - MICRO SIGN | ²³´µ
|
| U+00B7 - U+00BA | MIDDLE DOT - MASCULINE ORDINAL INDICATOR | ·¸¹º
|
| U+00BC - U+00BE | VULGAR FRACTION ONE QUARTER - VULGAR FRACTION THREE QUARTERS | ¼½¾
|
| U+00C0 - U+00D6 | LATIN CAPITAL LETTER A WITH GRAVE - LATIN CAPITAL LETTER O WITH DIAERESIS | ÀÁÂ...ÔÕÖ
|
| U+00D8 - U+00F6 | LATIN CAPITAL LETTER O WITH STROKE - LATIN SMALL LETTER O WITH DIAERESIS | ØÙÚ...ôõö
|
| U+00F8 - U+167F | LATIN SMALL LETTER O WITH STROKE - CANADIAN SYLLABICS BLACKFOOT W | øùú...ᙽᙾᙿ
|
| U+1681 - U+180D | OGHAM LETTER BEITH - MONGOLIAN FREE VARIATION SELECTOR THREE | ᚁᚂᚃ...᠋᠌᠍
|
| U+180F - U+1FFF | SYRIAC LETTER BETH - GREEK DASIA | ᠏ܒܓ...´῾
|
| U+200B - U+200D | ZERO WIDTH SPACE - ZERO WIDTH JOINER |
|
| U+202A - U+202E | LEFT-TO-RIGHT EMBEDDING - RIGHT-TO-LEFT OVERRIDE | |
| U+203F - U+2040 | UNDERTIE - CHARACTER TIE | ‿⁀
|
| U+2054 | INVERTED UNDERTIE | ⁔
|
| U+2060 - U+218F | WORD JOINER - TURNED DIGIT THREE | ...↉↊↋
|
| U+2460 - U+24FF | CIRCLED DIGIT ONE - NEGATIVE CIRCLED DIGIT ZERO | ①②③...⓽⓾⓿
|
| U+2776 - U+2793 | DINGBAT NEGATIVE CIRCLED DIGIT ONE - DINGBAT NEGATIVE CIRCLED SANS-SERIF NUMBER TEN | ❶❷❸...➑➒➓
|
| U+2C00 - U+2DFF | GLAGOLITIC CAPITAL LETTER AZU - COMBINING CYRILLIC LETTER IOTIFIED BIG YUS | ⰀⰁⰂ...
|
| U+2E80 - U+2FFF | CJK RADICAL REPEAT - IDEOGRAPHIC DESCRIPTION CHARACTER OVERLAID | ⺀⺁⺂...⿹⿺⿻
|
| U+3004 - U+3007 | JAPANESE INDUSTRIAL STANDARD SYMBOL - IDEOGRAPHIC NUMBER ZERO | 〄々〆〇
|
| U+3021 - U+302F | HANGZHOU NUMERAL ONE - HANGUL DOUBLE DOT TONE MARK | 〡〢〣...
|
| U+3031 - U+D7FF | VERTICAL KANA REPEAT MARK - HANGUL JONGSEONG PHIEUPH-THIEUTH | ...
|
| U+F900 - U+FD3D | CJK COMPATIBILITY IDEOGRAPH-F900 - ARABIC LIGATURE ALEF WITH FATHATAN ISOLATED FORM | 豈更車...ﴻﴼﴽ
|
| U+FD40 - U+FDCF | ARABIC LIGATURE TEH WITH JEEM WITH MEEM INITIAL FORM - ARABIC LIGATURE NOON WITH JEEM WITH YEH FINAL FORM |
|
| U+FDF0 - U+FE44 | ARABIC LIGATURE SALLA USED AS KORANIC STOP SIGN ISOLATED FORM - PRESENTATION FORM FOR VERTICAL RIGHT WHITE CORNER BRACKET |
...﹂﹃﹄
|
| U+FE47 - U+FFFD | PRESENTATION FORM FOR VERTICAL LEFT SQUARE BRACKET - REPLACEMENT CHARACTER | ﹇﹈﹉...�
|
| U+10000 - U+1FFFD | LINEAR B SYLLABLE B008 A - CHEESE WEDGE (U+1F9C0) | |
| U+20000 - U+2FFFD | <CJK Ideograph Extension B, First> - CJK COMPATIBILITY IDEOGRAPH-2FA1D (U+2FA1D) | |
| U+30000 - U+3FFFD | ||
| U+40000 - U+4FFFD | ||
| U+50000 - U+5FFFD | ||
| U+60000 - U+6FFFD | ||
| U+70000 - U+7FFFD | ||
| U+80000 - U+8FFFD | ||
| U+90000 - U+9FFFD | ||
| U+A0000 - U+AFFFD | ||
| U+B0000 - U+BFFFD | ||
| U+C0000 - U+CFFFD | ||
| U+D0000 - U+DFFFD | ||
| U+E0000 - U+EFFFD | LANGUAGE TAG (U+E0001) - VARIATION SELECTOR-256 (U+E01EF) |
六月五日 等待变化等待机会
王八拳战术,也就是漫无目的把非军工企业活生生的逼上梁山转型为军工企业,现在看起来还是有一定针对性的,具体看来就是阻止真正的军民融合战略造成
军是军,民是民的条块分割状况,这个战术有一点点像是当年日军围困八路军的所谓
囚笼战术,那么打破这个囚笼是否需要发动一场
百团大战的战役呢?
六月六日 等待变化等待机会
From [expr.prim.lambda#2]:
The evaluation of a lambda-expression results in a prvalue temporary . This temporary is called the closure object.
And from [expr.prim.lambda#3]:
这个是我所不知道的,居然要防止你复用吗?目的是什么?难道是只能当作rvalue来使用?The type of the lambda-expression (which is also the type of the closure object) is a unique, unnamed non-union class type — called the closure type.
What's more [expr.prim.lambda]:
The closure type associated with a lambda-expression has a deleted ([dcl.fct.def.delete]) default constructor and a deleted copy assignment operator.
And an important quote:
The C++ closures do not extend the lifetimes of the captured references.
这个例子是相当的有深度的 首先我们必须要定义baz的conversion operator能够允许转化为函数指针类型,其次才是定义了call operator能够调用,而这里返回的是类的成员函数指针确实是让人有些担忧,所以,才需要把call定义为static的,否则我以为你是没办法不使用bind的,因为this指针必须要bind才行啊。我觉得这里的技巧就是你不是简单的传递函数指针f_ptr类型,而是实际上使用了conversion operator才能顺利的把结构baz的实例作为参数传递了,这个是比使用繁琐的bind-this来的高明的多的做法!The closure type for a lambda-expression with no lambda-capture has a public non-virtual non-explicit const conversion function to pointer to function having the same parameter and return types as the closure type’s function call operator. The value returned by this conversion function shall be the address of a function that, when invoked, has the same effect as invoking the closure type’s function call operator.
Basically, in C++98⁄03 you couldn't instantiate a template with a local type.
六月七日 等待变化等待机会
To recall, in C++17 a
constexprfunction has the following rules:
- it shall not be virtual;
- its return type shall be a literal type;
- each of its parameter types shall be a literal type;
- its function-body shall be
= delete,= default, or a compound-statement that does not contain
- an
asm-definition,- a
gotostatement,- an identifier label,
- a try-block, or
- a definition of a variable of non-literal type or of static or thread storage duration or for which no initialization is performed.
六月八日 等待变化等待机会
所以,这里有两层意思,首先是虽然你强制转换了类型提醒了编译器,但是编译器懵懵懂懂的说我你让我重新翻译这个foo指针但是我从一开始就不知道它是哪一个。其次,就算我知道它是哪一个你要是不明确的强制转换我是不会帮你做的。这个实在是一个奇怪的行为。因为古老的c-style的强制转换是没有问题的: 所以,问题出在reinterpret_cast身上。看这里的说明我是一头雾水。 当然我尝试使用static_cast是成功的因为它和c-style-cast几乎是等效的吧?这里的著名的比较所有六种类型的cast的帖子绝对值得收藏,可是要真正理解却很难。
- Compiler does not know, which overload of
cbto chose.- Even if it did know, it would not convert from
void*to, sayvoid(*)(int), without any explicit conversion.
static_castdynamic_castconst_castreinterpret_cast- C-style cast
(type)value- Function-style cast
type(value)How does one decide which to use in which specific cases?
static_castis the first cast you should attempt to use. It does things like implicit conversions between types (such asinttofloat, or pointer tovoid*), and it can also call explicit conversion functions (or implicit ones). In many cases, explicitly statingstatic_castisn't necessary, but it's important to note that theT(something)syntax is equivalent to(T)somethingand should be avoided (more on that later). AT(something, something_else)is safe, however, and guaranteed to call the constructor.
static_castcan also cast through inheritance hierarchies. It is unnecessary when casting upwards (towards a base class), but when casting downwards it can be used as long as it doesn't cast throughvirtualinheritance. It does not do checking, however, and it is undefined behavior tostatic_castdown a hierarchy to a type that isn't actually the type of the object.
const_castcan be used to remove or addconstto a variable; no other C++ cast is capable of removing it (not evenreinterpret_cast). It is important to note that modifying a formerlyconstvalue is only undefined if the original variable isconst; if you use it to take theconstoff a reference to something that wasn't declared withconst, it is safe. This can be useful when overloading member functions based onconst, for instance. It can also be used to addconstto an object, such as to call a member function overload.
const_castalso works similarly onvolatile, though that's less common.
dynamic_castis exclusively used for handling polymorphism. You can cast a pointer or reference to any polymorphic type to any other class type (a polymorphic type has at least one virtual function, declared or inherited). You can use it for more than just casting downwards – you can cast sideways or even up another chain. Thedynamic_castwill seek out the desired object and return it if possible. If it can't, it will returnnullptrin the case of a pointer, or throwstd::bad_castin the case of a reference.
dynamic_casthas some limitations, though. It doesn't work if there are multiple objects of the same type in the inheritance hierarchy (the so-called 'dreaded diamond') and you aren't usingvirtualinheritance. It also can only go through public inheritance - it will always fail to travel throughprotectedorprivateinheritance. This is rarely an issue, however, as such forms of inheritance are rare.
reinterpret_castis the most dangerous cast, and should be used very sparingly. It turns one type directly into another — such as casting the value from one pointer to another, or storing a pointer in anint, or all sorts of other nasty things. Largely, the only guarantee you get withreinterpret_castis that normally if you cast the result back to the original type, you will get the exact same value (but not if the intermediate type is smaller than the original type). There are a number of conversions thatreinterpret_castcannot do, too. It's used primarily for particularly weird conversions and bit manipulations, like turning a raw data stream into actual data, or storing data in the low bits of a pointer to aligned data.
C-style cast and function-style cast are casts using
(type)objectortype(object), respectively, and are functionally equivalent. They are defined as the first of the following which succeeds:
const_caststatic_cast(though ignoring access restrictions)static_cast(see above), thenconst_castreinterpret_castreinterpret_cast, thenconst_castIt can therefore be used as a replacement for other casts in some instances, but can be extremely dangerous because of the ability to devolve into a
reinterpret_cast, and the latter should be preferred when explicit casting is needed, unless you are surestatic_castwill succeed orreinterpret_castwill fail. Even then, consider the longer, more explicit option.C-style casts also ignore access control when performing a
static_cast, which means that they have the ability to perform an operation that no other cast can. This is mostly a kludge, though, and in my mind is just another reason to avoid C-style casts.
We create a generic lambda and then forward all the arguments we get. To
define it correctly we need to specify noexcept and return type.
That’s why we have to duplicate the calling code - to get the proper
types.
为什么需要duplicate calling code?这个是lambda的语法吗?我的感觉它属于lambda-specifiers注意到它既可以出现在参数之前也可以出现在参数之后。
lambda-declarator:
lambda-specifiers
( parameter-declaration-clause ) lambda-specifiers requires-clauseopt
lambda-specifiers:
decl-specifier-seqopt noexcept-specifieropt attribute-specifier-seqopt trailing-return-typeopt
六月九日 等待变化等待机会
A lambda can only be converted to a function pointer if it does not capture.这里是说明。
The closure type for a lambda-expression with no lambda-capture has a public non-virtual non-explicit const conversion function to pointer to function having the same parameter and return types as the closure type’s function call operator. The value returned by this conversion function shall be the address of a function that, when invoked, has the same effect as invoking the closure type’s function call operator.所以我无法返回lambda作为函数指针,可是我又不能直接返回成员函数指针因为它的签名不一样,所以之前作者的例子是返回一个static方法指针,这就是我一直想避免的地方,看来是不太可能的,因为核心的问题就是怎么传递this指针的问题,这个无法回避。难道我可以使用band吗? 结果我花了快一个多小时才搞明白几个小问题:
its operand is a qualified-id not enclosed in parentheses也就是说有类的名字空间的
A pointer to member is only formed when an explicit & is used and its operand is a qualified-id not enclosed in parentheses. [ Note: That is, the expression &(qualified-id), where the qualified-id is enclosed in parentheses, does not form an expression of type “pointer to member”. Neither does qualified-id, because there is no implicit conversion from a qualified-id for a non-static member function to the type “pointer to member function” as there is from an lvalue of function type to the type “pointer to function” ([conv.func]). Nor is &unqualified-id a pointer to member, even within the scope of the unqualified-id's class. — end note ]
伪装成一个自由函数,这个是从使用的无差别上来看的,但是从编译器的角度来看两者的类型依然是不兼容的。这个道理其实很容易理解,因为如果不是这样子的话何必要发明std::function呢?
六月十日 等待变化等待机会
标志类作为实验对象。 然后定义一个双重的lambda用来产生一个这个标志类的tuple,这里最伤脑筋的地方是make_tuple的参数是什么?我脑子里又像短路一样希望先使用foldoperation来展开参数然后再传递给make_tuple,全然忘记了函数参数本身就能够对于参数进行展开,哪怕参数是模板参数,我以前对于这一点不肯定结果饶了一个大圈子在Struct的ctor里定义实参让它通过ctor来展开,现在看来完全不需要,根本不需要引入ctor的参数。
玩具integral_constant和integer_sequence它们的目的都是如此。这个lambda的结果是什么呢? 那么这么一个怪物要怎么使用它呢?对于tuple的apply方法我始终会和variant的visit方法产生莫名其妙的联想,其实两者唯一的联系就是它们都很神奇,除此之外完全不同! 这个神奇的无用的玩具究竟能做什么呢?
玩具可能更加的复杂一些,就是如何用以上的标志类去创建一个包含它们的variant的一个vector呢?比如这个类型当N=3时 这个lambda会不会让人看的头晕呢? 这里值得注意的是我又一次的错误的使用了
braced-list-initialization,相对照的这个是错误的
comma operator其结果就是返回一个长度为1的数组,其元素是最后一个也就是包含实际元素为Struct<2>的一个variant而已! 让我们做一下鉴定如何? 如果我们visit会有什么结果呢? 注意这里的visit的访问函数没有使用模板或者那个神奇的overload范式,原因当然是我们的处理比较的简单因为我们访问的是一致的一个共同的成员变量m_id,如果不是这样子的话那就要使用那个神奇的overload来实现动态多态了。 结果当然是这样子的
0,1,2,不过话说回来了,是否一定需要使用那个复杂的overload呢?比如我使用一个简单的lambda不行吗? 注意这里使用decay_t的必要性因为我们实在是无法预料这个参数到底是什么const还是reference等等。
六月十一日 等待变化等待机会
这里有一个小小的关于c++20的改进
Lambdas in unevaluated contexts - you can now create a map or a set and use a lambda as a predicate.这句话的理解上我出了偏差,这个到底是什么意思呢?最后通过实验我再次证明我的记忆是对的,在map或者set里predicate是一个类型而不是指的实例这一点也许有争议但是我绝的意思对就可以,就是说我们指的是set/map的类型的模板参数,而不是说ctor里传入的用于比较的functor,因为如果是后者根本就不存在什么unevaluate的意思,它是ctor的实参是一定是一个实际的运行期使用的代码,根本不搭界。所以,这个一定是指的是模板参数部分。那么如果要让一个lambda成为unevaluated,那么当然是使用decltype,这里我一直有一个模糊认识就是说我以为一个lambda如果声明为constexpr就可以看作是编译期可用,似乎就是unevaluate的,这简直是毫无道理,因为归根结底这里需要的是一个type,其他都是废话。
utility里的一个内部函数_Build_index_tuple的做法,首先,我决定只是针对最原始的数列而不是integer_sequence来操作,因为我遇到模板参数的小困难,这里是定义 我知道对于数组越界有更漂亮的SFINAE的技巧,可惜我不知道怎么做就只能让他报错,不过效果上也没有什么差别。 然后这个递归定义就是核心,我为了这个小东西想了好久。这里算不算specialization呢? 然后这里是
收获结果,这里我还在犹豫value这个返回值能否变成static的,其实这个想法是荒谬i的,一点意义也没有。 这样子使用是不行的,因为我要用的类型是integer_sequence,所以这里加了一个小lambda来包装一下,这里我再一次为了lambda避免使用模板而转实参。 我非常肯定mpl之类的应该有现成的实现,可是没有找到。
| 战区机关驻地 | 集团军番号 | 军部驻地 |
|---|---|---|
| 东部战区机关驻福建福州 | 陆军第七十一集团军 | 军部驻江苏徐州 |
| 陆军第七十二集团军 | 军部驻浙江湖州 | |
| 陆军第七十三集团军 | 军部驻福建厦门 | |
| 南部战区机关驻广西南宁 | 陆军第七十四集团军 | 军部驻广东惠州 |
| 陆军第七十五集团军 | 军部驻云南昆明 | |
| 西部战区机关驻甘肃兰州 | 陆军第七十六集团军 | 军部驻青海西宁 |
| 陆军第七十七集团军 | 军部驻四川成都 | |
| 北部战区机关驻山东济南 | 陆军第七十八集团军 | 军部驻黑龙江哈尔滨 |
| 陆军第七十九集团军 | 军部驻辽宁辽阳 | |
| 陆军第八十集团军 | 军部驻山东潍坊 | |
| 中部战区机关驻河北石家庄 | 陆军第八十一集团军 | 军部驻河北张家口 |
| 陆军第八十二集团军 | 军部驻河北保定 | |
| 陆军第八十三集团军 | 军部驻河南新乡 |
2017年组建的陆军第七十一集团军下辖:
- 重型合成第二旅
- 重型合成第三十五旅
- 重型合成第一六〇旅
- 中型合成第一七八旅
- 轻型合成第一七九旅
- 重型合成第二三五旅
- 陆航第七十一旅
- 炮兵第七十一旅
- 防空第七十一旅
- 特战第七十一旅
- 工化第七十一旅
- 勤务支援第七十一旅
2017年组建的陆军第七十二集团军下辖:
- 两栖合成第五旅 (05两栖突击炮+05两栖步战车)
- 重型合成第十旅 (96A坦克+04/04A 步战车)
- 中型合成第三十四旅
- 中型合成第八十五旅
- 轻型合成第九十旅
- 两栖合成第一二四旅(05两栖突击炮+05两栖步战车)
- 特战第七十二旅
- 炮兵第七十二旅
- 防空第七十二旅
- 陆航第七十二旅
- 工化第七十二旅
- 勤务支援第七十二旅
2017年组建的陆军第七十三集团军下辖:
- 轻型合成第三旅
- 两栖合成第十四旅
- 重型合成第八十六旅(96系列坦克 +04)
- 两栖合成第九十一旅
- 轻型合成第九十二旅
- 中型合成第一四五旅
- 特战第七十三旅
- 陆航第七十三旅
- 炮兵第七十三旅
- 防空第七十三旅
- 工化第七十三旅
- 勤务支援第七十三旅
2017年陆军第七十四集团军组建后,下辖:
- 两栖合成第一旅
- 重型合成第十六旅(96+86A)
- 两栖合成第一二五旅
- 轻型合成第一三二旅
- 中型合成第一五四旅
- 轻型合成第一六三旅
- 特战第七十四旅
- 陆航第七十四旅
- 炮兵第七十四旅
- 防空第七十四旅
- 工程防化第七十四旅
- 勤务支援第七十四旅
2017年组建的陆军第七十五集团军下辖:
- 重型合成第三十一旅
- 山地合成第三十二旅
- 轻型合成第三十七旅
- 轻型合成第四十二旅
- 中型合成第一二二旅
- 重型合成第一二三旅
- 空中突击第一二一旅
- 特战第七十五旅
- 炮兵第七十五旅
- 防空第七十五旅
- 工程防化第七十五旅
- 勤务支援第七十五旅
2017年陆军第七十六集团军组建后,下辖:
- 重型合成第十二旅 (96A+04A)
- 重型合成第十七旅(99+04A)
- 轻型合成第五十六旅
- 重型合成第六十二旅(99A+04A)
- 中型合成第一四九旅
- 轻型合成第一八二旅
- 特战第七十六旅
- 陆航第七十六旅
- 炮兵第七十六旅
- 防空第七十六旅
- 工程防化第七十六旅
- 勤务支援第七十六旅
2017年陆军第七十六集团军组建后,下辖:
- 重型合成第十二旅 96A+04A)
- 重型合成第十七旅(99+04A)
- 轻型合成第五十六旅
- 重型合成第六十二旅(99A+04A)
- 中型合成第一四九旅
- 轻型合成第一八二旅
- 特战第七十六旅
- 陆航第七十六旅
- 炮兵第七十六旅
- 防空第七十六旅
- 工程防化第七十六旅
- 勤务支援第七十六旅
2017年陆军第七十七集团军组建后,下辖:
- 中型合成第三十九旅
- 山地合成第四十旅
- 轻型合成第五十五旅
- 重型合成第一三九旅
- 轻型合成第一五〇旅
- 中型合成第一八一旅
- 陆航第七十七旅
- 特战第七十七旅
- 炮兵第七十七旅
- 防空第七十七旅
- 工程防化第七十七旅
- 勤务支援第七十七旅
2017年陆军第七十八集团军组建后,下辖:
- 重型合成第八旅
- 轻型合成第四十八旅
- 重型合成第六十八旅
- 中型合成第一一五旅
- 重型合成第二〇二旅
- 重型合成第二〇四旅
- 特战第七十八旅
- 陆航第七十八旅
- 炮兵第七十八旅
- 防空第七十八旅
- 工程防化第七十八旅
- 勤务支援第七十八旅
2017年陆军第七十九集团军组建后,下辖:
- 中型合成第四十六旅
- 重型合成第一一六旅
- 轻型合成第一一九旅
- 重型合成第一九〇旅
- 轻型合成第一九一旅
- 中型合成第二〇〇旅
- 陆航第七十九旅
- 特战第七十九旅
- 炮兵第七十九旅
- 防空第七十九旅
- 工化第七十九旅
- 勤务支援第七十九旅
2017年组建后,陆军第八十集团军下辖:
- 轻型合成第四十七旅
- 重型合成第六十九旅
- 中型合成第一一八旅
- 轻型合成第一三八旅
- 轻型合成第一九九旅
- 中型合成第二〇三旅
- 陆航第八十旅
- 特战第八十旅
- 炮兵第八十旅
- 工化第八十旅
- 防空第八十旅
- 勤务支援第八十旅
2017年组建的陆军第八十一集团军下辖:
- 重型合成第七旅
- 轻型合成第七十旅
- 中型合成第一六二旅
- 中型合成第一八九旅
- 重型合成第一九四旅
- 重型合成第一九五旅(96A+04A)
- 特战第八十一旅
- 炮兵第八十一旅
- 防空第八十一旅
- 工化第八十一旅
- 陆航第八十一旅
- 勤务支援第八十一旅
2017年组建的陆军第八十二集团军下辖:
- 重型合成第六旅
- 轻型合成第八十旅
- 重型合成第一一二旅
- 中型合成第一二七旅
- 重型合成第一五一旅
- 重型合成第一八八旅
- 轻型合成第一九六旅
- 特战第八十二旅
- 炮兵第八十二旅
- 防空第八十二旅
- 工兵第八十二旅(以平战结合形式承担国家地震灾害紧急救援队任务)
- 防化第八十二旅
- 陆航第八十二旅
- 勤务支援第八十二旅
2017年组建的陆军第八十三集团军下辖:
- 重型合成第十一旅(96系列+86)
- 中型合成第五十八旅
- 中型合成第六十旅
- 中型合成第一一三旅
- 中型合成第一三一旅
- 中型合成第一九三旅
- 空中突击第一六一旅
- 特战第八十三旅
- 炮兵第八十三旅
- 防空第八十三旅
- 工化第八十三旅
- 勤务支援第八十三旅
六月十二日 等待变化等待机会
A functor is a mapping between categories. Given two categories, C and D, a functor F maps objects in C to objects in D — it’s a function on objects.
triviallycopyable的概念,所以,我还专门去做一个检验是否支持这里的Counter是我定义的一个简单的结构,如果我故意定义数据结构导致没有指针长度对齐,这个显然就不行了,我的意思是不一定是所谓指针长度,而是处理器最基本的load/store的单位长度对齐吧?总之,这个没有什么问题很好理解,但是我要怎么实现这个结构的一个加加减减来展示它的作用呢?我当然可以去实现这个结构Counter本身的操作符operator++(int)(注意是postfix++因为有一个操作符类型int)然后使用atomic_ref的方法compare_exchange_weak(localCounter, localCounter--);可是编译可以链接会失败抱怨load/store没有实现,我一开始还以为这个是不被接受的后来才明白这个是需要动态库-latomic链接的。但是对于怎么使用fetch_add我依然不知道怎么办,同样的compare_exchange_weak似乎和我设想的不一样,肯定是我理解错了。当然我也找到一个例子就是说绕开自定义类型这个坑,因为假如我们还是瞄准基本的类型的话,我还是可以直接对于基本类型操作,比如 但是怎么解决自定义类型呢?我要再找找。太累了歇一下吧。
error: invalid application of ‘sizeof’ to a bit-field
六月十四日 等待变化等待机会
六月十五日 等待变化等待机会
奇迹的时代,当年的大英帝国不断的在它日不落的殖民地描绘各种充满传奇的铁路建设计划来吸引英国本土的资本来追逐,今天美国不断上演传奇的科技
奇迹来吸引全世界的资本来追捧,但是无论多么豪华奢侈的盛宴总有落幕的那一天,只不过鼎盛总是出现在顶峰之后一点点而已。
六月十六日 等待变化等待机会
parameter pack,这两个Ints1和Ints2同时出现在模板参数里在老版本的c++里是不可想像的! 那么我现在要调用这个lambda就出现了编译器反复抱怨我定义的操作符重载找不到的问题,直到我把它放在了和调用的lambda相同的名字空间才行,这个原则就是因为integer_sequence定义在std的名字空间里,作为编译器它解决操作符是依赖于参数的定义空间来查找的,当他找到一系列的操作符<<的重载之后就一个个来解决,失败以后是不会在去我定义的名字空间来查找的。这个是操作符重载时候的一个大问题,尽量不要对全局或者std名字空间类型做这个事情! 这个是完整的lambda的定义,我为了偷懒都是用
现学现卖的模式,就是马上定义马上调用,这个大大增加了调试的难度! 这里关于
parameter pack是一个再次训练的好机会,首先第一重的lambda是把一个整数模板参数转化为一个自动生成的integer_sequence,第二重是把这一个从0到N-1的integer_sequence变成N个长度为1的integer_sequence然后再把这些使用fold operation。这里需要注意的任何一次的parameter pack都不要有comma(,),因为编译器实在是太聪明了,比如我们把一个integer_seqeunce变成N个integer_sequence这个是函数的参数自动展开,我一开始担心这个模板参数不懂的这么做,真的是太出乎意料了。当然了要打印结果我们还是需要简单的重载一下 这里(os<<...<<Ints);使用的依然是fold operation的第四种形式,我觉的有的人喜欢使用comma operation,这个也的确不错(os<<Ints<<",",...);它的好处是可以插入一个分隔符","所以,这个也许是更好的选择,但是切勿不要混淆这两种截然不同的操作!
六月十八日 等待变化等待机会
矫情来形容是太温文尔雅了,能不能说
未富先婊呢?也许可以创造一个英文短语叫做
get bitchy before getting richy。
六月十九日 等待变化等待机会
六月二十日 等待变化等待机会
下标index集合了唯一要做的就是去应用它到这个用户提供的targetTuple上就行了,不过要注意我们的这个抽象的t是一个包含了tuple的tuple。我们不仅需要模拟apply的做法使用一个index_sequence把这个tuple中的每一个tuple都取出来还要在内部的无名lambda里去应用每一个包含的index_sequence于用户提供的targetTuple上然后在make_tuple的参数里应用parameter pack expansion使得我们返回的也是tuple of tuple。我觉得这个代码的可读性是及其差的,几乎没有打算让初学者理解。
From the c++11 standard §14.3.2.1
我只看懂了这个结论。Template non-type arguments
A template-argument for a non-type, non-template template-parameter shall be one of:
- for a non-type template-parameter of integral or enumeration type, a converted constant expression (5.19) of the type of the template-parameter; or
- the name of a non-type template-parameter; or
- a constant expression (5.19) that designates the address of an object with static storage duration and external or internal linkage or a function with external or internal linkage, including function templates and function template-ids but excluding non-static class members, expressed (ignoring parentheses) as & id-expression, except that the & may be omitted if the name refers to a function or array and shall be omitted if the corresponding template-parameter is a reference; or
- a constant expression that evaluates to a null pointer value (4.10); or
- a constant expression that evaluates to a null member pointer value (4.11); or
- a pointer to member expressed as described in 5.3.1; or
- an address constant expression of type std::nullptr_t.
Note: A string literal (2.14.5) does not satisfy the requirements of any of these categories and thus is not an acceptable template-argument.
六月二十一日 等待变化等待机会
六月二十二日 等待变化等待机会
| 这个是目前编译器所能支持的变通的办法传统的做法是把参数组成一个tuple然后再capture,然后再使用apply解开tuple,这个确实是比较的繁琐,当然这个是一个很好的技巧,在我看来tuple应该是运行期无差别的吧? | |
|---|---|
| 这个是作者提议编译器增加的功能 | |
| 这个是我觉得实际程序员会做的,因为真的有必要capture吗?使用参数难道会增加成本吗?也许吧?如果说使用rvalue-reference比capture-initialization有更高的成本的话,我就完全同意作者的提议 |
An expression of the form (e1 op1 ... op2 e2) where op1 and op2 are fold-operators is called a binary fold. In a binary fold, op1 and op2 shall be the same fold-operator, and either e1 shall contain an unexpanded pack or e2 shall contain an unexpanded pack, but not both就是说fold不可能使用在两个parameter pack上!.
If e2 contains an unexpanded pack, the expression is called a binary left fold.
If e1 contains an unexpanded pack, the expression is called a binary right fold.
六月二十三日 等待变化等待机会
六月二十四日 等待变化等待机会
{12,hello,0.67}
{hello,0.67}
{0.67}
{}
{0,{1,2,3,4}}
{1,{0,2,3,4}}
{2,{0,1,3,4}}
{3,{0,1,2,4}}
{4,{0,1,2,3}}
{1,6,4,5,3,6}
{6,4,5,3,6}
{4,5,3,6}
{5,3,6}
{3,6}
{6}
六月二十五日 等待变化等待机会
{1}
{1,6}
{1,6,4}
{1,6,4,5}
{1,6,4,5,3}
{1,6,4,5,3,6}
六月二十六日 等待变化等待机会
鼠式坦克歼击车。
六月二十七日 等待变化等待机会
A metafunction is a class template or a template alias whose parameters are all types对于mp11的说明里一个结构里的模板成员函数和一个模板结构的一个成员这两者之间究竟有和使用的玄妙呢?
A quoted metafunction is a class with a public metafunction member called fn
六月二十八日 等待变化等待机会
手技是值得学习的,因为不依赖于任何现有的库完全凭借标准库来实现那都是多年积累的功力,是最值得仔细临摹观赏的。我决定再次领会记录。
list就先入为主的以为有什么存储的结构,在元编程里它们是虚无的,没有什么结构能够存储类型,就好像index_squence是类型而不是作为实际的存储来体现的。说到底这个typelist就是一个模板结构为
化身的类型,神仙在
凡间都有着无数的
肉身因为它们所代表的类型列表本身就不是一个运行期能够表达的
物件,所以你才能理解所谓的
神龙见尾不见首的奇妙之处,也才能体会用类型来定义一个本来看起来是一个操作对象的真谛。因此typelist就是一个类型 它的使用是一个
万能的template template,这个可以是包罗万象的
乾坤一气袋。任何定义都无出其右也。
无中生有彷佛宇宙大爆炸理论一样可以
道生一,一生二,二生三,三生万物。或者是针对佛家的断言:空即为色,色即为空。我们不去评论它是否为循环定义,总之释道两家都没有一个科学的判断依据。std::is_empty这个神器是提供这个功能的:
这个实现是相当不容易的,我简单搜索看不到它是在标准库有实现的痕迹,似乎连编译器都未必有,也许是所谓的builtin吧,总之__is_empty一时还不知道出处。不过不重要,知道empty的判断标准是纯粹的空结构:union和struct的区分是SFINAE据说做不到的?这里唯一不清楚的是bit-fields。 这里我的实验表明首先static member不能是bit-fields,这个是违法的。其次,我对于这种英语霸权主义非常气愤,为什么使用英语定义的呢?cplusplus的定义也是一样,不知道谁抄谁,我始终不能理解什么是If T is an empty type (that is, a non-union class type with no non-static data members other than bit-fields of size 0, no virtual functions, no virtual base classes, and no non-empty base classes), provides the member constant value equal to true. For any other type, value is false.
If T is a non-union class type, T shall be a complete type; otherwise, the behavior is undefined.
The behavior of a program that adds specializations for is_empty or is_empty_v (since C++17) is undefined.
has no non-static members other than bit-fields of length 0,这句话是什么意思?你定义一个bit-fields如果size为0,编译器直接报错,这个是不可能的也无意义。终于在标准里我找到了答案:
As a special case, an unnamed bit-field with a width of zero specifies alignment of the next bit-field at an allocation unit boundary. Only when declaring an unnamed bit-field may the width be zero.,所以如下的例子是我添加的,简单的说就是以下是成立的: 这就是定义里为什么要强调other than bit-fields。定义的严谨是多么的重要,c++里每一步都是坑!
六月二十九日 等待变化等待机会
模样我不知道它究竟有何必要列名? 注意这个X<int> x;最能说明问题,就是这里T只是作为一个placeholder的角色,本身不能参与到具体的类型的声明计算。所以根本没有必要出现命名。
Within the scope of a class template, when the name of the template is neither qualified nor followed by <, it is equivalent to the name of the template followed by the template-parameters enclosed in <>.我的理解是模板类。复习一下,所谓qualified意味着有scope::操作符。
但是如果改动一下,这个是成立的,它说明了什么呢? 指针不是递归定义,这个即便不是模板类也是如此,那么现在这个和模板就无关了吗?这个是否说明了这里的A成了类而不是模板类呢?我都要吐了。Qualified identifiers
A qualified id-expression is an unqualified id-expression prepended by a scope resolution operator ::, and optionally, a sequence of enumeration(since C++11), class or namespace names or decltype expressions(since C++11) separated by scope resolution operators.
空白噪音比如typelist<>,并不改变 结果 这个不禁让我怀疑作者的is_empty是否有必要?这个我现在不确定。这个是误解作者的用意是排除空结构和我说的是风马牛不相及的事情。
六月三十日 等待变化等待机会
七月一日 等待变化等待机会
According to 9.3.4.6 [dcl.fct] paragraph 5,
The type of a function is determined using the following rules. The type of each parameter (including function parameter packs) is determined from its own decl-specifier-seq and declarator也就是说函数的签名只决定于这两样,这个是小学生都明白的道理,不是吗?. After determining the type of each parameter, any parameter of type “array of T” or “function returning T”为什么要单单提这两样呢?因为函数参数传递数组是不允许的,只能传递指针,这个是尽人皆知的,这里是再次提醒。至于说函数参数是一个函数表达式这个需要计算它的返回值类型,可是这里的细节是如果函数返回值类型是传值还是传引用还是传指针,这个是回答,一派胡言!人家说的是参数是一个函数的话要把参数改成是一个函数指针。这个例子说明了一切!本来参数f是一个函数,但是签名必须改成指针! 这个是我从来没有想到过的问题! is adjusted to be “pointer to T” or “pointer to function returning T,” respectively. After producing the list of parameter types, any top-level cv-qualifiers modifying a parameter type are deleted when forming the function type. The resulting list of transformed parameter types and the presence or absence of the ellipsis or a function parameter pack is the function's parameter-type-list. [Note: This transformation does not affect the types of the parameters. For example, int(*)(const int p, decltype(p)*) and int(*)(int, const int*) are identical types. —end note]
别名alias应该被像宏一样的替换而这个应该发生在预处理阶段,所以,在parsing阶段就是重复定义了。
不可描述的!因为这个断言不成立: 我不论怎么尝试都不行,因为编译器说A的类型是template<class T, T* <anonymous> > struct A,结果是T是int,但是编译器不承认T*是int*,这简直就是
白马非马!这是哪家的王法?! 顺便说一下,对于is_empty的必要性要明确就是sizeof是有很大局限性的是不能用于判断一个类型是否为空的,比如以上的类型A的sizeof就不为0,这个是因为编译器至少gcc统一对于没有成员的结构做了一个
虚假陈述,更不要说bit-fields对于sizeof的误导了
“你很快就会知道一切的,所有人都会知道。汪教授,你的人生中有重大的变故吗?这变故突然完全改变了你的生活,对你来说,世界在一夜之间变得完全不同。” “没有。” “那你的生活是一种偶然,世界有这么多变幻莫测的因素,你的人生却没什么变故。” “大部分人都是这样嘛。” “那大部分人的人生都是偶然。” “可多少代人都是这么平淡地过来的。” “都是偶然。” “是的,整个人类历史也是偶然,从石器时代到今天都没什么重大变故,真幸运。但既然是幸运,总有结束的一天;现在我告诉你,结束了,做好思想准备吧。”
七月二日 等待变化等待机会
不可描述的模板的问题,作者想表达的是什么我至今没有理解,他引用的相对照的例子我在体会这个是一个典型的教科书式的SFINAE的例子:首先一个名如其人的alias是使用第一个参数first_of 然后关键的关键是在返回值上做文章 因为它的核心就是编译器要替换模板参数的时候生成函数返回值,虽然函数返回值不是函数重载所必须的,但是它是函数签名的一部分,这里我就觉得有些矛盾,具体细节想不清楚。 这个是与之对照的万能的fallback 那么对于 为什么第一个f偏好第一个模板呢?很显然的是因为函数参数起了决定作用,因为函数首先使用参数类型匹配来决定最佳的选择。而模板X能够让函数返回值成立,但是第二个f很显然的试图追随同样原则,但是它的返回值不成立,编译器默默的吞下苦果无声的退而求其次使用了万能的第二个f,这个就是整个SFINAE的过程。但是作者的核心问题是什么呢?我现在总算明白了一点昨天的<不可描述的问题是Non-type_template_parameter 也就是说我昨天糊涂的没有注意到第二个模板参数并不是一个类型参数,而是non-typed。而我明白这一点后居然发现了如何描述这个不可描述的类型是什么: 这个是否是很神奇?同样的另外一个例子它是这样子的 这个是不是很让人惊讶一个变量的类型居然依赖于它传入参数的变量的id,这个说明我是看不太懂,也许说的就是这个意思吧?
An id-expression naming a non-type template-parameter of class type T denotes a static storage duration object of type const T, known as a template parameter object, whose value is that of the corresponding template argument after it has been converted to the type of the template-parameter.我想最关键的说明就是这句An id-expression naming a non-type template-parameter of class type T,这个就是这个static_assert成立的来源。我现在也开始领悟到作者的问题是什么,就是说为什么对于这个non-type template parameter没有经历类似的SFINAE的过程呢?很显然的int::size是不成立的,但是这个并不影响结果,似乎是模板参数先转换类型确定T是int之后顺理成章的认定第二个non-type的就是合法的T*或者说int*而完全不用考虑int::size不成立的问题。
The 2nd parameter is necessary to be used for template specialization, but we don't use it in our "fallback"所以核心是specialization的需求,如果没有默认参数我们就没有理由做specialization!它使得编译器structso we just default tovoid.
有了选择犹豫进而尝试使用所谓的更加匹配的形式。用我自己的话来说所谓的spcialization都是让编译器有了似是而非的选择困难之后才有的结果。
前卫知识分子以社会公益为己任希望引进美欧文明来解决中国本地的社会问题,但是事实上美国为代表的外部文明的真正目的却仅仅是为了维持其自身的既得利益而意图彻底消除威胁自身的潜在对手的潜力。这个现象像极了
地球三体组织(ETO)意图引进三体文明来拯救地球文明的初衷却达到了引狼入室的效果一样,作为三体文明争取生存空间是唯一重要的内容,其他是否消灭曾经客观上帮助它们达到这一目的的ETO以及人类文明的利益与诉求都是不重要的。可怜的公知团体中有很多成员也许都怀着一些天真的期待认为文明进化的更高阶段意味着道德水平的更高阶段,因此像当然的认为出于食物链高端的美欧社会应该出于更高的道德高地来帮助发展中国家来改善其生活状况,却不知争取更大的生存空间始终是围绕着任何发展阶段的文明的最核心的内容,在生存第一的目的面前,所谓的道德也是作为约束限制麻痹对手的工具。
七月三日 等待变化等待机会
程序正义,欧美的律师都是编程的好手,能够把现行法律体系玩的滴流转需要的就是这种敢于冒天下之大不韪的离经叛道,不计较社会成本的个性自由。这个在和平年代都是社会的引领精英为人津津乐道,一旦战争爆发或者大灾大难来临,等着排队枪毙的就是这类人。
error: unnamed scoped enum is not allowed然后我可以定义一个模板类 注意成员变量是不能声明为constexpr的,除非是static的,成员只能声明为const,只有成员函数才能声明为constexpr 注意这里我有意把ctor也定义为constexpr是为了能够使用static_assert 但是当我理所当然的以为我可以这样子断言t1的类型的时候: 发现编译错误, 原因是enum_1并不是一个模板类型参数,而是一个值,但是它的类型因为是匿名的enum,所以我无法命名它的类型。这里我常常会潜意识里认为enum的值好像是不同的类型一样,可是实际上不是的。另一个很有意思的观察就是t1,t2,t3的类型
七月四日 等待变化等待机会
There are two distinct kinds of enumerations: unscoped enumeration (declared with the enum-key也就是说如果我声明为enum class/struct,那么它就应该是所谓的scoped enumeration。所以,我遇到的问题和non-typed template parameter是两个截然不同的问题。我遇到的是一个typed template parameter,只不过它的enum type是一个匿名的。enum) and scoped enumeration (declared with the enum-keyenum classorenum struct).
opaque enum declaration for a scoped enumeration whose underlying type is int比如 这个就是它的典型的应用就是它给了你一个enum的class,根本就是一个
标志类比如你在dispatch的时候可以作为case来使用的标识。当然这个用途的确不大,我们能够使用其他的做法达到同样目的还能够应用index,它能吗?因为它就是一个int的别名吧,但是它是一个类,你不能给它赋任何值,纯粹的无意义的东西。
error: 'f' declared as function returning a function所以,基于这个原因你只能返回函数指针typedef int (*functPtr)();然后才可以定义functPtr f(){return functPtr{};} 所以,这里对于这样子的模板的错误不是模板specialization本身的错误而是任何函数都不能返回函数类型的返回值:
含义的吧?
Sun Jul 4 2021 20:54:39 UTC
In a world without Borders and Fences who needs Windows and Gates?
 很明显的GCC是一个反对微软的政治组织?哈哈,在
很明显的GCC是一个反对微软的政治组织?哈哈,在独立日贴这样一个snapshot是有意义的因为GNU的宗旨就在于摆脱垄断与独裁争取自由与独立。
Drafting: Informal consensus has been reached in the working group and is described in rough terms in a Tentative Resolution, although precise wording for the change is not yet available.那么是否是gcc要等待结果再去修正呢?可能是吧?
七月五日 等待变化等待机会
If同时添加cv这类的const不能简单的添加const,而是要使用add_const 换言之 但是当我尝试这样子对于模板原型的时候失败了,就是说这些type_traits是针对Tnames the type "array ofU" or "reference to array ofU", the member typedeftypeis U*.
实际类型对于模板来说它们更像是一个变化的形式,实际上编译器在解决的过程中就是在使用类似的过程吧?总而言之,我觉得这个是编译器的实现问题,而gcc在等待委员会的决定。那么clang和其他编译器如何呢?clang居然已经解决了这个问题!MSVC也没有问题!看来gcc实在是老了!
章北海与父亲的重要对话一共有三句:
父:要多想。
海:想了以后呢?
父:北海,我只能告诉你在那以前要多想。
这三句对话出现在《黑暗森林》前半部分,而在本书后半部分,章北海率领自然选择号逃亡后与亚洲舰队司令的第一次通讯之中,他才将这三句对话发生的背景——即他们父子坚定不移的逃亡主义思想之来源做出了说明。
父亲和北海从三体危机一开始就在思考这场战争最基本的问题,后来在章父身边出现了同样在思考战争基本的 “未来史学派” ,早在太空军建立之前,早在面壁计划开始之前,这群人就对人类的未来进行了详细周密的推演,他们不但预言了大低谷,预言了人类文明的复兴,也预言了末日之战中人类将一败涂地。
如果说章北海是自己给自己烙下了另一种形式的“思想钢印”,那么他对战败的预测和逃亡的信念,就是源自未来史学派内部的研究和讨论。
要多想,
意思就是要比别的人想的更多,更全面,不但要知道人类必定失败,更要想出应对最坏情况的详细计划并且提前部署实施。
在对话之前,父子两人都知道彼此对这场战争的看法,两人都坚信人类必败,那么注定失败的战争应该怎么打?无非两种情况,一种是无谓的牺牲,那么父亲的话应该是“要勇敢”或者“别多想”。而“要多想”,就是另一种选择:准备逃亡,保存火种!所以章北海在听到这三个字的时候,心中很感慨,父亲和自己不只对战争的预测一致,对应对战争的想法也一致,父亲也是逃亡主义者。
但他不知道在逃亡之后应该怎么办。于是又问了“想了以后呢?”
章父回答:“北海,我只能告诉你在那以前要多想。”
“在那以前”这四个字可以把时间线分为三段,“那”代表的是逃亡机会出现的时段,在这个时段之前要多想。而在这个时段之中和这之后则不用多想,因为机会出现的瞬间需要果断不能多想,之后则是人类进入新的状态,星舰文明诞生谁也不知道会有什么事情发生,想了也没用。
这三句对话,是章父对北海的最后指导,也决定了章北海对待未来的态度发展为坚定的逃亡主义。
后文北海的一切行为和遭遇都是以这次对话为基点展开的,他的周密计划和果断的出逃为人类星舰文明的开始提供了宝贵机会。也正是因为对逃亡成功之后的事情缺少计划(并非没有预测,只是没有行动计划),导致自然选择号没有能够在黑暗战役的残酷对决中胜出,但是对于北海来说,这件事并不重要。他继承父亲志愿,唯一坚守的目标已经达成,人类文明的火种已经保存下来,所以对他来说,谁是最后的幸存者,“都一样”。
(书中还着重描述了在逃亡之后章北海精神面貌的巨大变化,由一个紧绷着的弦放松下来,结合他早已对黑暗战役中星舰之间的猜疑链有所预估,却拖延了一个月还迟迟没有动手,这和逃亡成功之前的果决形成了鲜明对比,说明比起人类的延续,自身个体的存亡在北海心中分量要轻得多。)
。。。
在对话结束后,章北海还有一段内心独白:“爸爸,我们想的一样,这是我的幸运,我不会给您带来荣耀,但会让您安息。”
有着无与伦比的远见卓识,刚毅绝伦的坚强信念,加上过人的胆魄,高超的智慧,以及那一点人性的善良。
章北海,无愧是三体这套书中最闪耀的“人类四杰”之一。
自古中秋月最明, 凉风届后夜弥清。 一天气象沉银汉, 四海鱼龙耀水清。
七月六日 等待变化等待机会
max<T1,T2> function.这里面的原因我不想追究,我只关心平常模板函数如果我不使用specialization的语法的话是不是就是说编译器自己从实参类型推导模板参数类型?所以,从这个角度来看就是函数重载?
The type of a function is determined using the following rules.这里翻译成中文就是函数的签名取决于函数的参数组,那么参数的类型的决定却有一个转换的过程,就是
The type of each parameter (including function parameter packs) is determined from its own parameter-declaration ([dcl.decl]). After determining the type of each parameter, any parameter of type “array of T” or of function type T is adjusted to be “pointer to T”. After producing the list of parameter types, any top-level cv-qualifiers modifying a parameter type are deleted when forming the function type. The resulting list of transformed parameter types and the presence or absence of the ellipsis or a function parameter pack is the function's parameter-type-list.
top-level cv-qualifiersmodifying a parameter type deleted这里指的是最上层的那些const被最后去除了,也就是说函数的签名居然不包含那些最上层的const/volatile等等。这个本身就让我有些意外,这个难道会导致函数的类型签名不需要const之类的吗?这是不是违反常理呢? 但是这个却是事实: 同时更让人困惑的是这个过程并不会改变参数的类型?(这句话我就觉得别扭) 而上面的这个core 1001的问题也和这个有着密切的关系,作者认为标准含糊不清,但是后来的讨论又似乎是说这个是
The CWG agreed that this behavior is intrinsic to the different ways cv-qualification applies to array types and non-array types.由此我得出的猜测是这个现象只有数组才会有? 比如如果不是数组类型根本就不会有任何的问题。注意到标准提到函数转为函数指针和数组转为指针的过程都发生 ,但是即便是我们把上面的例子改为函数类型也没有问题,这个做正了问题的核心是数组的某些和cv-qualifier加载相关的特殊性的问题: 我花了两天时间debug但是依然没有很多的头绪,我现在走出了最最原始的一步就是在gcc的pt.c里determine_specialization对于要比较的两个函数声明的参数类型,其实很原始的warning打印的参数不是printf而是自成一派,比如 而我还没有找到这个%E是在哪里定义的,很多地方打印函数声明又使用了别的%qD之类的,我还要学习,不过这个过程却很简单,因为我之前编译过了debug版本的gcc,现在任何小小的修改只是编译一个文件是非常快的一个过程,所以,这个给了我一个很好的探索的机会。
七月七日 等待变化等待机会
漂亮输出。我现在就打算在compparms函数里面对面的输出参数来比较看看为什么不符合。不成功因为这里面远比我想的要复杂,因为TREE_CODE判断的不是所谓的tcc(tree code class),还要使用TREE_CODE_CLASS来包。。。总之,思路是有了,无非就是打印这个还是比较容易的。休整一下再说吧?
(gdb) p TREE_CODE(TYPE_CANONICAL(TREE_VALUE(t1)))
$102 = POINTER_TYPE
(gdb) p TREE_CODE(TREE_TYPE(TYPE_CANONICAL(TREE_VALUE(t1))))
$104 = INTEGER_TYPE
(gdb) p TREE_CODE(TYPE_CANONICAL(TREE_VALUE(t2)))
$105 = POINTER_TYPE
(gdb) p TREE_CODE(TREE_TYPE(TYPE_CANONICAL(TREE_VALUE(t2))))
$106 = INTEGER_TYPE
if (TREE_TYPE(TREE_VALUE(t1))!=NULL_TREE && TREE_CODE(TREE_TYPE(TREE_VALUE(t1))) !=VOID_TYPE)
warning(0, "t1: %qD", TREE_TYPE(TREE_VALUE(t1)));
if (TREE_TYPE(TREE_VALUE(t2))!=NULL_TREE && TREE_CODE(TREE_TYPE(TREE_VALUE(t2))) !=VOID_TYPE)
warning(0, "t2: %qD", TREE_TYPE(TREE_VALUE(t2)));
基因导弹所采用的思路和当前的新冠疫情如出一辙,都有可能是某个神秘组织研发出来的针对某个特定的人的基因或者某一类人的基因的
导弹,因为对于大多数人都是轻感冒的症状,可是对于某些特定基因类型的人群则是致命的。如果我们现在能够把这一年多来死亡的人群做一个全面的扫描也许就能够发现其中的端倪。在已经死去的几百万人类里也许就有罗辑。ETO今天为了杀死那个躲在地球的某个不为人知的地下的罗辑不惜杀死几百万人也要达成目的。为了杀死第四个面壁者,不惜消灭几百万人,而对于未达目的不择手段的ETO来说杀死这么多人一点问题都没有,他们担心的不是杀死更多的人而是担心三体要杀死罗辑的目的会暴露,所以不得不把杀死罗辑掩盖在杀死几百万以至于上千万人里。
七月八日 等待变化等待机会
美国:给文明以岁月; 中国:给岁月以文明;
文明体系中,所有地球大国都衰落了,而一个个军事帝国崛起了,可以想像的是强大的美军各个司令部各自独立成为一个个雄霸一方的独立王国。各个司令部垄断了本地区的资源作为其维持统治的经济基础,比如美军各个司令部分别控制着所在大洲的各种资源。
每次我发出对于gcc开发前辈的惊叹的时候脑子里就回想着这些歌词。也只有这些词句能够表达我对于这些前辈的崇敬敬仰之情:
我们的王成,是毛泽东的战士,是顶天立地的英雄,是特殊材料制成的人。他的豪迈气概从那里来?因为他对朝鲜人民无限的爱,对侵略者切齿的恨!在我们志愿军队伍里,有千千万万个王成,这就是我们伟大祖国的骄傲和光荣!
烽烟滚滚唱英雄,
四面青山侧耳听,侧耳听
晴天响雷敲金鼓,
大海扬波作和声
人民战士驱虎豹,
舍生忘死保和平
为什么战旗美如画,
英雄的鲜血染红了它
为什么大地春常在,
英雄的生命开鲜花;
英雄猛跳出战壕,
一道电光裂长空,裂长空
地陷进去独身挡,
天塌下来只手擎
两脚熊熊趟烈火,
浑身闪闪披彩虹
为什么战旗美如画,
英雄的鲜血染红了它
为什么大地春常在,
英雄的生命开鲜花;
一声呼叫炮声隆,
翻江倒海天地崩,天地崩
双手紧握爆破筒,
怒目喷火热血涌
敌人腐烂变泥土,
勇士辉煌化金星
为什么战旗美如画,
英雄的鲜血染红了它
为什么大地春常在,
英雄的生命开鲜花!
七月九日 等待变化等待机会
人人皆知的加密传输方法:
后来,有人想到了一个办法:A先把信放到箱子里后上一把锁,然后让邮差把箱子送给B。B在接到箱子后不打开,而是再上一把锁,这样箱子上就有两把锁了。B再让邮差把箱子送回给A,然后A把箱子上自己那把锁打开,让邮差再把箱子送回给B。这时箱子上只有B的一把锁了,B用自己的钥匙把箱子打开就可以了。这个过程中,邮差接触不到任何一把钥匙。原文是有意引出RSA的公钥私钥,但是假如我们降低一些要求能不能这样子呢?
一秘一钥的原则,每次通讯都使用和电文等长的密钥不重复,理论上是不能破解的。这个说法对吗?
%A function argument-list. %C tree code. %D declaration. %E expression. %F function declaration. %G gcall * %H type difference (from). %I type difference (to). %K tree %L language as used in extern "lang". %O binary operator. %P function parameter whose position is indicated by an integer. %Q assignment operator. %S substitution (template + args) %T type. %V cv-qualifier. %X exception-specification. */
七月十日 等待变化等待机会
warning: fn_arg_types: ‘(int (*)(int))’; decl_arg_types: ‘(int (*)(int))’七月十一日 等待变化等待机会
TREE_CODE(TREE_VALUE(TYPE_ARG_TYPES(t)))===>POINTER_TYPE
TREE_CODE(TREE_TYPE(TREE_VALUE(TYPE_ARG_TYPES(t))))==> INTEGER_TYPE
TYPE_QUALS(TREE_TYPE(TREE_VALUE(TYPE_ARG_TYPES(t))))==>1TREE_CODE(TREE_VALUE(TREE_CHAIN(TYPE_ARG_TYPES(t))))==>VOID_TYPETREE_CODE(TREE_TYPE(TREE_VALUE(TREE_CHAIN(TYPE_ARG_TYPES(t)))))执剑人候选人选的章节是最能说明整个
黑暗森林理论的实质。对于威慑的本质的理解决定了整个人类文明和三体文明博弈的最基础战略,三体派驻人类的大使
智子要以最柔美的外形来麻痹人类世界的战略,这本身就是要作为一种公关政策来掩盖三体本质上为争取生存空间的不择手段的看似邪恶的本质,另一个小小的细节就是绝对不暴露三体人生物形态的细节而只以智子的形态来与人类交流是为了减小人类公众对于三体文明异类的印象。另一方面,威慑力的计算是无法评估民主体制下的多权力决策机制的,也就是说三体文明和人类文明都明白威慑力的实现必须用个人独裁机制实现,结合当前美国国会剥夺总统交战权的权力法案可以明白美国已经丧失了威慑力。
/* A type designated by `typename T::t'. TYPE_CONTEXT is `T', TYPE_NAME is an IDENTIFIER_NODE for `t'. If the type was named via template-id, TYPENAME_TYPE_FULLNAME will hold the TEMPLATE_ID_EXPR. TREE_TYPE is always NULL. */问题是在typename之前的const是否被丢掉了? 这里有一个观点是这样子的:就是说typename后面要紧跟所谓的qualified name,在我理解就是通常的scoped name。如果是这样子的话那么const只能放在typename之前了。所以,这个是没有选择的。我现在越来越感到这个问题的复杂,我开始迷茫这个问题到底是在parse的时候就出现了问题还是说在specialization的时候呢?或者问题的根源究竟是什么?
七月十二日 等待变化等待机会
const enum tree_code_class tree_code_type[] = {
#include "all-tree.def"
};
s-alltree: Makefile
rm -f tmp-all-tree.def
echo '#include "tree.def"' > tmp-all-tree.def
echo 'END_OF_BASE_TREE_CODES' >> tmp-all-tree.def
echo '#include "c-family/c-common.def"' >> tmp-all-tree.def
ltf="$(lang_tree_files)"; for f in $$ltf; do \
echo "#include \"$$f\""; \
done | sed 's|$(srcdir)/||' >> tmp-all-tree.def
$(SHELL) $(srcdir)/../move-if-change tmp-all-tree.def all-tree.def
$(STAMP) s-alltree
lang_tree_files= ../../gcc-10.2.0/gcc/ada/gcc-interface/ada-tree.def ../../gcc-10.2.0/gcc/cp/cp-tree.def ../../gcc-10.2.0/gcc/d/d-tree.def ../../gcc-10.2.0/gcc/objc/objc-tree.def
七月十三日 等待变化等待机会
parameter-declaration-clause:
parameter-declaration-listopt ...opt
parameter-declaration-list , ...
parameter-declaration-list:
parameter-declaration
parameter-declaration-list , parameter-declaration
parameter-declaration:
attribute-specifier-seqopt decl-specifier-seq declarator
attribute-specifier-seqopt decl-specifier-seq declarator = initializer-clause
attribute-specifier-seqopt decl-specifier-seq abstract-declaratoropt
attribute-specifier-seqopt decl-specifier-seq abstract-declaratoropt = initializer-clause
attribute-specifier-seq:
attribute-specifier-seqopt attribute-specifier
attribute-specifier:
[ [ attribute-using-prefixopt attribute-list ] ]
alignment-specifier
decl-specifier-seq:
decl-specifier attribute-specifier-seqopt
decl-specifier decl-specifier-seq
decl-specifier:
storage-class-specifier
defining-type-specifier
function-specifier
friend
typedef
constexpr
consteval
constinit
inline
defining-type-specifier:
type-specifier
class-specifier
enum-specifier
type-specifier:
simple-type-specifier
elaborated-type-specifier
typename-specifier
cv-qualifier
cv-qualifier:
const
volatile
typename-specifier:
typename nested-name-specifier identifier
typename nested-name-specifier templateopt simple-template-id
nested-name-specifier:
::
type-name ::
namespace-name ::
decltype-specifier ::
nested-name-specifier identifier ::
nested-name-specifier templateopt simple-template-id ::
qualified name或者是scoped identifier之类的,这里我们选择哪一个呢?散步回来我觉得是type-name
type-name:
class-name
enum-name
typedef-name
class-name:
identifier
simple-template-id
simple-template-id:
template-name < template-argument-listopt >>
declaration sepecifiers比如ds_const这个enum cp_decl_spec是对应于const等等。这个是我要重点debug的地方,之前我在gdb已经打印觉得不太正确,接下来要确认这一点!
./1001.cpp:2:20: warning: grokdeclarator:declspecs: T
2 | typedef T arr[3];
| ^
cp_parser_explicit_specialization ->cp_parser_single_declaration ->cp_parser_init_declarator ->cp_parser_declarator ->cp_parser_direct_declarator ->cp_parser_parameter_declaration_clause ->cp_parser_parameter_declaration_list ->grokdeclarator
这里的结果是完全正确的 这里打印的aka在error.c里应该是strip_typedefs的结果,大概是把TREE_LIST用TREE_CHAIN做遍历,对于每一个TREE_VALUE针对不同的类型的TREE_TYPE做调整,这些类型包含POINTER_TYPE,REFERENCE_TYPE,等等几乎所有类型都包含。这里针对TYPENAME_TYPE的做法是TYPENAME_TYPE_FULLNAME。。。非常的复杂我看不下去了。。。 总而言之这里的const依旧保存着。也就是说模板实例化得到的参数是正确的。
七月十四日 等待变化等待机会
七月十五日 等待变化等待机会
/* A template-id, like foo<int>. The first operand is the template. The second is NULL if there are no explicit arguments, or a TREE_VEC of arguments. The template will be a FUNCTION_DECL, TEMPLATE_DECL, or an OVERLOAD. If the template-id refers to a member template, the template may be an IDENTIFIER_NODE. */我目前看到的是这样子的:DEFTREECODE (TEMPLATE_ID_EXPR, "template_id_expr", tcc_expression, 2)
The return type, the parameter-type-list, the ref-qualifier, and the cv-qualifier-seq, but not the default arguments or the exception specification, are part of the function type.就是标准里的关于函数的标准定义:
D1 ( parameter-declaration-clause ) cv-qualifier-seqopt也就是说函数的签名包含了D1,parameter-declaration-clause, cv-qualifier-seqopt和ref-qualifieropt。 注意这里没有提到 attribute-specifier-seqopt,这个是和函数签名无关的,它是所谓的
ref-qualifieropt noexcept-specifieropt attribute-specifier-seqopt
attribute-specifier-seq:
attribute-specifier-seqopt attribute-specifier
attribute-specifier:
[ [ attribute-using-prefixopt attribute-list ] ]
alignment-specifier
alignment-specifier:
alignas ( type-id ...opt )
alignas ( constant-expression ...opt )
attribute-using-prefix:
using attribute-namespace :
七月十八日 等待变化等待机会
peek再下一个token以及再下一个,如果看到的是<>,这个就说明是模板的specialization,于是就进入到了cp_parser_explicit_specialization,这里是非常的形象,要lookahead两个token才能决定,但是这个也不是最主要的,关键是同样的模板也许在不同的上下文也许语法是不同的吧?我这个仅仅是为了帮助理解context-sensitive的例子,就是说parser还有所谓的一个成员变量来描述上下文,这个才导致语法解析的复杂之处。这个是由语法本身的歧义性造成的和实现无关,哪怕是clang也会遇到同样的问题,所以,这里是实现不能回避的困难。
explicit-specialization:
template < > declaration
explicit-specialization:
template < > decl-specifier [opt] init-declarator [opt] ;
template < > function-definition
template < > explicit-specialization
template < > template-declaration
peek函数,等于是lookahead并没有consume这些token,这也就是为什么进入到函数以后调用
cp_parser_require_keyword (parser, RID_TEMPLATE, RT_TEMPLATE);
cp_parser_require (parser, CPP_LESS, RT_LESS);
cp_parser_require (parser, CPP_GREATER, RT_GREATER);
declaration或者说函数specitialization的instantiation,因为它的参数是正确的const int*,我看到的问题是出在模板声明的参数为什么是int*?不是吗?太平洋上的台风已经形成了,但是它的起源应该在数千英里以外的某只不知名的蝴蝶在无意识的煽动了几下翅膀造成的?总之我的头脑又一次的混乱了,我需要再次理清思路,还是要再次检查来的路。这个不是在原地打转,因为每次我都看清楚一些以前不知道的足迹,这个正好像人类认识世界的过程是一个反复螺旋上升的过程,每次的旋转setback并不是back to square one,而是在提高了一个维度的情况下看待原来的二维坐标,就是说我在二维空间的坐标是回到了起点,可是我先在是站在三维空间的第三维的更高的坐标上了,也就是螺旋上升的那个高度来俯视我之前的足迹。这就是学习的过程。 吃早饭以后再说吧?
黑洞一般的函数的噩梦grokdeclarator。现在的问题是在进入这个黑洞之前我得到的所谓的decl_specifier到底是怎样的呢?这里我的一个朴素的感悟是start_function是解析函数的一个入口,这个感想是多么的朴素啊!而那个
黑洞grokdeclarator会被很多函数所调用,因为顾名思义它就是语法里的declarator啊!
declarator:
ptr-declarator
noptr-declarator parameters-and-qualifiers trailing-return-type
noptr-declarator:
declarator-id attribute-specifier-seqopt
noptr-declarator parameters-and-qualifiers
noptr-declarator [ constant-expressionopt ] attribute-specifier-seqopt
( ptr-declarator )
declarator-id:
...opt id-expression
ptr-declarator:
noptr-declarator
ptr-operator ptr-declarator
ptr-operator:
* attribute-specifier-seqopt cv-qualifier-seqopt
& attribute-specifier-seqopt
&& attribute-specifier-seqopt
nested-name-specifier * attribute-specifier-seqopt cv-qualifier-seq
explicit-instantiation:
externopt template declaration
A function template defines an unbounded set of related functions.而不要小看这个定义,我居然没有这个overloading的概念,因为以下的代码让我感到震惊 你可以这样做,这个是合法的,可是这个不是推翻了使用模板的全部意义吗?你对于这样子的overloading有意义吗?你明明就是在无所不包的模板参数里包含了各种各样的overloading了何必要再来一个呢?你不能直接使用specialization达到所谓的overloading的效果吗?定义两个本质上一样的模板函数不是浪费编译器的工作吗?也许这个就是c++语法设计之初不允许禁止程序员自杀的初衷吧?也许很多语言设计之初就瞄准了特定的使用场景根本就不浪费在无意义的语法场景,把程序员的胡思乱想限制掉了,可是c++没有,也不允许。这个是所谓的
绝对的自由吗?而且这个例子还强调说Such specializations are distinct functions and do not violate the one-definition rule. 我对于这两个几乎相同的模板函数分别进行specialization 然后如果我们直接调用的话它是否优先匹配specialization呢?这个答案是必然的,这个是基本的常识啊。
int number=10;
int*pNumber=&number;
my(number);
my(&pNumber);
倾向性似乎很难界定吧?
七月十九日 等待变化等待机会
TREE_CODE(TREE_VALUE(TREE_CHAIN(params))) ==> VOID_TYPETREE_CODE(TREE_TYPE(TREE_VALUE(params))) ==> TYPENAME_TYPETYPE_QUALS(TREE_TYPE(TREE_VALUE(params))) ==> 1TREE_CODE(TYPE_NAME(TREE_TYPE(TREE_VALUE(params)))) ==> TYPE_DECLDECL_ORIGINAL_TYPE(TYPE_NAME(TREE_TYPE(TREE_VALUE(params)))) ==> 0x0TYPENAME_IS_ENUM_P(TREE_TYPE(TREE_VALUE(params))) ==> 0TYPENAME_IS_CLASS_P(TREE_TYPE(TREE_VALUE(params))) ==> 0(TYPE_CONTEXT(TREE_TYPE(TREE_VALUE(params)))) ==> RECORD_TYPETYPE_LANG_SPECIFIC(TYPE_CONTEXT(TREE_TYPE(TREE_VALUE(params)))) && CLASSTYPE_DECLARED_CLASS(TYPE_CONTEXT(TREE_TYPE(TREE_VALUE(params))))TYPE_QUALS(TYPE_CONTEXT(TREE_TYPE(TREE_VALUE(params)))) ==> 0 TREE_CODE(TYPE_NAME(TYPE_CONTEXT(TREE_TYPE(TREE_VALUE(params))))) ==> TYPE_DECLCP_DECL_CONTEXT(TYPE_NAME(TYPE_CONTEXT(TREE_TYPE(TREE_VALUE(params))))CP_DECL_CONTEXT(TYPE_NAME(TYPE_CONTEXT(TREE_TYPE(TREE_VALUE(params)))) == global_namespaceDECL_NAME(TYPE_NAME(TYPE_CONTEXT(TREE_TYPE(TREE_VALUE(params))))IDENTIFIER_POINTER(DECL_NAME(TYPE_NAME(TYPE_CONTEXT(TREE_TYPE(TREE_VALUE(params)))) ==> Awarning(0, "TREE_TYPE(TREE_VALUE(params)) as T: %T", TREE_TYPE(TREE_VALUE(params)));七月二十日 等待变化等待机会
#3 0x00000000009fdbf0 in grokdeclarator (declarator=0x36ca7b0, declspecs=0x7fffffffda50,
decl_context=NORMAL, initialized=1, attrlist=0x7fffffffd858)
at ../../gcc-10.2.0/gcc/cp/decl.c:13574
#4 0x0000000000a0484b in start_function (declspecs=0x7fffffffda50, declarator=0x36ca8d0,
attrs=0x0) at ../../gcc-10.2.0/gcc/cp/decl.c:16493
七月二十一日 等待变化等待机会
type = union tree_node {
tree_base base;
tree_typed typed;
tree_common common;
tree_int_cst int_cst;
tree_poly_int_cst poly_int_cst;
tree_real_cst real_cst;
tree_fixed_cst fixed_cst;
tree_vector vector;
tree_string string;
tree_complex complex;
tree_identifier identifier;
tree_decl_minimal decl_minimal;
tree_decl_common decl_common;
tree_decl_with_rtl decl_with_rtl;
tree_decl_non_common decl_non_common;
tree_parm_decl parm_decl;
tree_decl_with_vis decl_with_vis;
tree_var_decl var_decl;
tree_field_decl field_decl;
tree_label_decl label_decl;
tree_result_decl result_decl;
tree_const_decl const_decl;
tree_type_decl type_decl;
tree_function_decl function_decl;
tree_translation_unit_decl translation_unit_decl;
tree_type_common type_common;
tree_type_with_lang_specific type_with_lang_specific;
tree_type_non_common type_non_common;
tree_list list;
tree_vec vec;
tree_exp exp;
tree_ssa_name ssa_name;
tree_block block;
tree_binfo binfo;
tree_statement_list stmt_list;
tree_constructor constructor;
tree_omp_clause omp_clause;
tree_optimization_option optimization;
tree_target_option target_option;
} *
考古式的修补方式,也就是模仿前人的风格尽量小的添加自己的代码并且以把自己的代码彻底融入原来的历史为最高原则,这个经年累月的沉积层等到足够厚实以后对于后来者也就成了新的历史沉积导致后来者花几倍的力气来做同样类似的添加工作,这个称之为软件开发的一个类似
沉积岩的规律,所有的程序员都知道的现象,但是面对这个庞然大物没有程序员敢凭一己之力来对抗它,这才有了后来的clang的出现。不接受现实就只有出走另立山头。
面包屑,因为你探索了进入迷宫的路,要能够安全的出迷宫自己手头没有设立一些标识是困难的,而在gdb里依靠tree的记录的信息才能让你知道你处于哪一层迷宫。
美好年代人们对于c++带来的革命还在消化阶段,也许很多人认为模仿生物进化的类的继承就足以描述整个
MATRIX,也许大多数人根本没有想到c++语言还能有这么大的发展演绎空间,而那个时代编译器之间的比拼的指标是更快更兼容,为了能够在同类中脱颖而出,尽可能多的兼容古代的语言和使用尽可能小的内存和最大限度提高单个文件语法解析速度是生存的唯一指标。毕竟在那个年代很多大公司的一个很大的野心就是垄断编译器垄断计算机操作系统垄断计算机架构。于是乎,那个时代的烙印深深的打印在gcc的沉积岩代码里了。
面包屑撒在了什么地方,也就是说各个函数调用之后具体怎样把语法解析的结果存储起来的部分,尤其要留心我心目中期待的链表的头在哪里。
七月二十二日 等待变化等待机会
#define RNG_SEED (((__TIME__[7] - '0') * 1 + (__TIME__[6] - '0') * 10 + \
(__TIME__[4] - '0') * 60 + (__TIME__[3] - '0') * 600 + \
(__TIME__[1] - '0') * 3600 + (__TIME__[0] - '0') * 36000) + \
(__LINE__ * 100000))
特殊,至少前几天我们已经知道了gcc会首先匹配非模板的普通函数,那么在不同的模板特例的排序就是我今后要注意留心的地方。
七月二十三日 等待变化等待机会
女子岂应关大计,英雄无奈怨红颜?
七月二十四日 等待变化等待机会
extern GTY(()) struct function *cfun;
/* Nonzero if function being compiled needs to be given an address
where the value should be stored. */
unsigned int returns_struct : 1;
/* The scope in which names should be looked up. If NULL_TREE, then
we look up names in the scope that is currently open in the
source program. If non-NULL, this is either a TYPE or
NAMESPACE_DECL for the scope in which we should look. It can
also be ERROR_MARK, when we've parsed a bogus scope.
This value is not cleared automatically after a id is looked
up, so we must be careful to clear it before starting a new look
up sequence. (If it is not cleared, then `X::Y' followed by `Z'
will look up `Z' in the scope of `X', rather than the current
scope.) Unfortunately, it is difficult to tell when name lookup
is complete, because we sometimes peek at a token, look it up,
and then decide not to consume it. */
tree scope;
/* OBJECT_SCOPE and QUALIFYING_SCOPE give the scopes in which the
last lookup took place. OBJECT_SCOPE is used if an expression
like "x->y" or "x.y" was used; it gives the type of "*x" or "x",
respectively. QUALIFYING_SCOPE is used for an expression of the
form "X::Y"; it refers to X. */
tree object_scope;
tree qualifying_scope;
/* A stack of parsing contexts. All but the bottom entry on the
stack will be tentative contexts.
We parse tentatively in order to determine which construct is in
use in some situations. For example, in order to determine
whether a statement is an expression-statement or a
declaration-statement we parse it tentatively as a
declaration-statement. If that fails, we then reparse the same
token stream as an expression-statement. */
cp_parser_context *context;
statement:
labeled-statement
attribute-specifier-seqopt expression-statement
attribute-specifier-seqopt compound-statement
attribute-specifier-seqopt selection-statement
attribute-specifier-seqopt iteration-statement
attribute-specifier-seqopt jump-statement
declaration-statement
attribute-specifier-seqopt try-block
A declaration statement introduces one or more new names into a block;
ifstream in1("/tmp/word1-1.txt"), in2("/tmp/word1-2.txt");
ofstream out("/tmp/word1.txt");
in1.imbue(std::locale("zh_CN.UTF8"));
in2.imbue(std::locale("zh_CN.UTF8"));
out.imbue(std::locale("zh_CN.UTF8"));
乾坤有序,宇宙无疆,数一下吧有几个字符?中文编码是三个字符一个啊,不对吗?我使用midnightcommander来数也是啊。所以,
char buffer1[36], buffer2[36];
while (in1.get(buffer1, 30) && in2.get(buffer2, 30))
,)总是漏掉,然后再看文档才发现读的字符是30-1=29!
basic_istream& get( char_type* s, std::streamsize count );所以上面的30应该改成31! 唉,我一直想避免自己设定这些读取的字符数,结果还是在这上面栽跟头了。
... that is, reads at most count-1 characters and stores them into character string pointed to by s
...
while (in1.get(buffer1, 31) && in2.get(buffer2, 31)){
string str1(buffer1, 30), str2(buffer2, 30);
out<<(str1+str2)<<endl;
}
脱氧核酸和
颗粒籽核。
R语言检验的仁兄也不错,不过我把我的输入文件这个不知道是否有侵犯中华字经的版权呢?不过我想作者既然是大学教授他们也是没有版权的。净化了一下。
struct Word{
char m_utf8[3]={};
Word(){}
constexpr Word(const char utf8[3]){
m_utf8[0]=utf8[0];
m_utf8[1]=utf8[1];
m_utf8[2]=utf8[2];
}
auto operator <=>(const Word& other)const{
if (auto cmp=m_utf8[0]<=>other.m_utf8[0]; cmp!=0){
return cmp;
}else if (auto cmp=m_utf8[1]<=>other.m_utf8[1]; cmp!=0){
return cmp;
}else{
return m_utf8[2]<=>other.m_utf8[2];
}
}
bool operator ==(const Word&other)const{
return *this<=>other ==0;
}
};
set<Word> s;
ifstream in("/tmp/chinese.txt");
Word word;
const char CommaAry[3]={'\xEF','\xBC','\x8C'}, PeriodAry[3]={'\xE3','\x80','\x82'};
const Word Comma(CommaAry), Period(PeriodAry);
int counter=0;
while (in.get(word.m_utf8, 4)){
if (s.contains(word)){
if ((Comma<=>word)!=0 && (Period<=>word)!=0){
string str(word.m_utf8, 3);
cout<<"repeating..."<<str<<endl;
counter++;
}
}else{
s.insert(word);
}
}
cout<<"repeating total:"<<counter<<endl;
if ((Comma!=word)&&(Period!=word)){..
bool operator ==(const Word&other){
return *this<=>other ==0;
}
藏长行率调传核乐弹陆朝校圈膀重参畜咽厦曾。
七月二十五日 等待变化等待机会
struct Word{
array<char,3> m_utf8;
Word(){}
constexpr Word(const array<char,3>& ary):m_utf8{ary}{}
constexpr Word(const char utf8[3]){
m_utf8=std::experimental::make_array(utf8[0], utf8[1], utf8[2]);
}
auto operator<=>(const Word& other)const =default;
};
const char A[3]={'a','b','c'};
constexpr Word a(A), b({'a','b','c'});
static_assert(a==b);
提前计算的!怎么计算呢?我以前对于common_type这个类型计算工具感到有些无聊,现在才体会到它的重要。而对于这个样本实现和我看到的实际实现代码的差别的微妙之处我现在还难以领会。但是感觉有很多的学习之处比如一个简单的对于paramter pack样式的参数类型要求他们都不能是引用类型的判断使用了!__or_或者像参考代码std::conjunction,这些对于我来说都还是挺高级的。
宇宙飞船还理解不够,昨天的错误我还是没有找到答案,虽然我找到了正确的做法。
暴力执法使用static_assert了。 这个是使用的场景,只不过数组作为函数参数传递的时候
失去了它的本性被退化成了指针导致我的模板参数类型推导无法认出它是数组类型,我尝试使用什么forward也不行,也许是用反了?总之我只能使用模板参数来明确指示模板函数类型 我觉得这个还是很贴心的,不是吗?能不能把这个加入标准库呢?不过牵扯到使用experimental让人感到希望不大了。实际上我心目中的make_array就是这样子接受一个数组作参数然后返回array,不是吗?如果让我把一个extent_v为100的数组转化为一个array我要怎么办?难道手写一百个元素吗?也许我可以写一篇paper提个建议?不过这个要specialization模板函数make_array可能有些困难吧?我能够特例化数组类型吗?比如make_array<T []>()吗?我累了回头再想吧?
七月二十六日 等待变化等待机会
七月二十七日 等待变化等待机会
核糖核酸在外文里作为外来字是否就有了不同的含义呢?
中国国家标准总局1980年发布了《信息交换用汉字编码字符集》,1981年5月1日开始实施的一套国家标准,标准号是GB 2312—1980,简称GB2312。
GB2312标准共收入汉字6763个和非汉字图形字符682个。整个字符集分成94个区,每区有94个位。每个区位上只有一个字符,因此可用所在的区和位来对汉字进行编码,称为区位码。
对于人名、古汉语等方面出现的罕用字,GB 2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。
GBK全称《汉字内码扩展规范》(GBK即“国标”、“扩展”汉语拼音的第一个字母,英文名称:Chinese Internal Code Specification) ,中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订,国家技术监督局标准化司、电子工业部科技与质量监督司1995年12月15日联合以技监标函1995 229号文件的形式,将它确定为技术规范指导性文件。
GBK编码,是在GB2312标准基础上的内码扩展规范,使用了双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字,完全兼容GB2312标准。
After producing the list of parameter types, any top-level cv-qualifiers modifying a parameter type are deleted when forming the function type.要怎么理解呢?我现在有一个新的理解我以为函数的类型是一回事,它实际的参数是独立于它的,也就是说这个note说的很重要,我以前看过很多遍但是依然不能把握其中的真谛。为什么说
This transformation does not affect the types of the parameters.强调这一点的用意在哪里?难道这个不是显而易见的吗?那么这个例子的理解更加的重要,我以前没有看懂,这是多么让人汗颜的事实啊,写了这么多年的函数第一次对于什么是重载开始疑惑:
Overload resolution is a mechanism for selecting the best function to call given a list of expressions that are to be the arguments of the call and a set of candidate functions that can be called based on the context of the call.这里就看出了要害,我们是把expression的实参来和函数的所谓型参来比较,那么之前说了函数的型参列表是要去除top level cv-qualifier的,那么这个是resolution而我的问题是要回到overload的定义的本源来看。
The selection criteria for the best function are the number of arguments, how well the arguments match the parameter-type-list of the candidate function, how well (for non-static member functions) the object matches the implicit object parameter, and certain other properties of the candidate function.
Each of two or more entities with the same name in the same scope, which must be functions or function templates, is commonly called an “overload”.这里只是说了结果如果同时存在同名同
域的实体那么他必定是重载,可是它们为什么能够存在而不违反ODR呢?我要追寻一下关于函数的ODR是什么,现在要去买菜了。
Functions are not objects: there are no arrays of functions and functions cannot be passed by value or returned from other functions. Pointers and references to functions are allowed, and may be used where functions themselves cannot.不存在函数数组!我们平常用到的难道是函数指针数组?函数的引用我用过吗?
Each function has a type, which consists of the function's return type, the types of all parameters (after array-to-pointer and function-to-pointer transformations, see parameter list) , whether the function is noexcept or not (since C++17), and, for non-static member functions, cv-qualification and ref-qualification (since C++11). Function types also have language linkage. There are no cv-qualified function types (not to be confused with the types of cv-qualified functions such as int f() const; or functions returning cv-qualified types, such as std::string const f();). Any cv-qualifier is ignored if it is added to an alias for a function type.这里是我们熟悉的函数重载的定义,没毛病啊!
Multiple functions in the same scope may have the same name, as long as their parameter lists and, for non-static member functions, cv/ref (since C++11)-qualifications are different. This is known as function overloading. Function declarations that differ only in the return type and the noexcept specification (since C++17) cannot be overloaded.所以我的理解是函数的类型并不等同于它的参数就应该被
纯化,因为计算函数类型的这个
transformation过程并不影响函数的参数原本的类型,否则怎么可能又重载呢?这个是两个不同的概念吧。
Parameter list determines the arguments that can be specified when the function is called. It is a comma-separated list of parameter declarations, each of which has the following syntax :这里的很多东西我都是似曾相识的,因为这些天的gdb整天都在和它们打交道,现在是系统的整理思路的时机了。只有第5个的单个模板函数参数为void的时候我有些疑惑,需要做一下实验。
attr(optional) decl-specifier-seq declarator (1) Declares a named (formal) parameter. For the meanings of decl-specifier-seq and declarator, see declarations. int f(int a, int *p, int (*(*x)(double))[3]);attr(optional) decl-specifier-seq declarator =initializer(2) Declares a named (formal) parameter with a default value. int f(int a = 7, int *p = nullptr, int (*(*x)(double))[3] = nullptr);attr(optional) decl-specifier-seq abstract-declarator(optional) (3) Declares an unnamed parameter int f(int, int *, int (*(*)(double))[3]);attr(optional) decl-specifier-seq abstract-declarator(optional) =initializer(4) Declares an unnamed parameter with a default value int f(int = 7, int * = nullptr, int (*(*)(double))[3] = nullptr);void(5) Indicates that the function takes no parameters, it is the exact synonym for an empty parameter list: int f(void); and int f(); declare the same function. Note that the type void (possibly cv-qualified) cannot be used in a parameter list otherwise: int f(void, int); and int f(const void); are errors (although derived types, such as void* can be used). In a template, only non-dependent void type can be used (a function taking a single parameter of type T does not become a no-parameter function if instantiated with T = void).
The type of each function parameter in the parameter list is determined according to the following rules:看到没有,cppreference特意强调了这个
- First, decl-specifier-seq and the declarator are combined as in any declaration to determine the type.
- If the type is "array of T" or "array of unknown bound of T", it is replaced by the type "pointer to T"
- If the type is a function type F, it is replaced by the type "pointer to F"
- Top-level cv-qualifiers are dropped from the parameter type (This adjustment only affects the function type, but doesn't modify the property of the parameter: int f(const int p, decltype(p)*); and int f(int, const int*); declare the same function)
Top-level cv-qualifiers are dropped from the parameter type的行为并不会改变参数本身的属性This adjustment only affects the function type, but doesn't modify the property of the parameter,我能够相信这个是权威的解读吗?就是说函数本身的类型虽然取决于参数但是是被净化的参数列表,但是当函数类型和它的真实的参数列表合起来以后才是作为函数重载的依据? 首先这两个函数的类型就是不同的,这个要怎么解释static_assert(!is_same_v<void(const char*), void(char*)>);,你就不能说这两个函数的参数去掉top-level cv qualifier就一样了,这个const根本就不能算什么top level cv qualifier,那么什么情况下才是top level呢?
A top-level const qualifier affects the object itself. Others are only relevant with pointers and references. They do not make the object const, and only prevent modification through a path using the pointer or reference.这个概念在c++标准中似乎并没有很清晰的定义:
For a type cv T, the top-level cv-qualifiers of that type are those denoted by cv.但是接下来的例子反而让人糊涂了
The type corresponding to the type-id const int& has no top-level cv-qualifiers. The type corresponding to the type-id volatile int * const has the top-level cv-qualifier const. For a class type C, the type corresponding to the type-id void (C::* volatile)(int) const has the top-level cv-qualifier volatile.
| 例子代码 | const是否为top-level |
|---|---|
| T *const p; | 是 |
| T const *volatile q; | the top-level cv-qualifier is volatile |
| T const volatile *q; | has no top-level cv-qualifiers. In this case, the cv-qualifiers const and volatile appear at the second level. |
| int f(char const *p); | the const qualifier is not at the top level in the parameter declaration, so it is part of the function's signature. |
| int f(char *const p); | the const qualifier is at the top level, so it is not part of the function’s signature. This function has the same signature as: int f(char *p); |
七月二十八日 等待变化等待机会
void take_pf(int(* const pf)(char)); // declaration #1
void take_pf(int(* pf)(char)); // declaration #2
void take_pf(int(*pf)(char)){} // definition of both #1,#2 which are identical
重载,可是c++编译器看到的是相同的函数签名应该就是碰运气看不同的动态库的查找顺序吧?这个是我的想像还没有实际证明过。以后再说吧,太累了。
#define defineType char*
defineType d1,d2;
static_assert(is_same_v<decltype(d1), char*>);
static_assert(is_same_v<decltype(d2), char>);
typedef char* typedefType;
typedefType t1,t2;
static_assert(is_same_v<decltype(t1), char*>);
static_assert(is_same_v<decltype(t2), char*>);
static_assert(is_same_v<const typedefType, char*const>);static_assert(is_same_v<typedefType const, char*const>);宏替换的时候会很自然的把它在脑海里改成了char*const, 而且从右往左念出声来也对就是const pointer to char,这个方法真好!我决定把这篇小品文收藏在本地。
How did I know that *x[N] is an “array of ... pointer to ...” rather than a “pointer to an array of ...?” It follows from this rule:而这一段话是很有教育意义的,大师说明了()的两个大的功能,而且我以为是c/c++里最重要的两个功能,可以说就是核心与灵魂:first, as the function call operator, and second, as grouping.The operators in a declarator group according to the same precedence as they do when they appear in an expression.
For example, if you check the nearest precedence chart for either C or C++, you’ll see that [] has higher precedence than * . Thus the declarator *x[N] means that x is an array before it’s a pointer.
而接下来的这个考题才是检验你是否真的明白了大师的讲解Parentheses serve two roles in declarators: first, as the function call operator, and second, as grouping. As the function call operator, () have the same precedence as [] . As grouping, () have the highest precedence of all.
For example, *f(int) is a declarator specifying that f is a “function ... returning a pointer ... .” In contrast, (*f)(int) specifies that f is a “pointer to a function ... .”这里把declarator和declaration-specifier分开来是有帮助的,头脑中脑补一下,这个时候我觉得我需要一个例子来帮助我理解比如我们声明一个函数返回一个const指针指向int,它的参数是一个char,它是镇样子的int*const f(char);,那么f的类型是什么呢? static_assert(is_same_v<decltype(f), int*const(char)>); 这里我稍稍改变一下
int*const fp(char){return nullptr;} // a function returning a const pointer pointing to int
decltype(fp) *const g=&fp; //a const function pointer initialized to pointing to fp
static_assert(is_same_v<decltype(g), int*const(*const)(char)>);
static_assert(is_same_v<decltype(call_fp), void(int*const(*const)(char))>);
void call_fpc(const decltype(fp)*);
void call_fpc(decltype(fp) const*);
void call_fpc(decltype(fp) *const);
七月二十九日 等待变化等待机会
int ary[3];
static_assert(is_same_v<decltype(&ary), int(*)[3]>);
decltype(ary)& ary_ref=ary;
static_assert(is_same_v<decltype(ary_ref), int(&)[3]>);
void f_IntPtr(const IntPtr);
static_assert(is_same_v<decltype(f_IntPtr), void(int*)>); // #1
static_assert(is_same_v<decltype(f_IntPtr), void(int*const)>); // this is identical to #1 because top-level cv-qualifier is dropped
static_assert(std::is_same_v<decltype(f_Arr3), void(const int[3])>);
static_assert(std::is_same_v<decltype(f_Arr3), void(const int*)>);
七月三十日 等待变化等待机会
七月三十一日 等待变化等待机会
八月一日 等待变化等待机会
The TYPE_NAME field contains info on the name used in the program for this type (for GDB symbol table output). It is either a TYPE_DECL node, for types that are typedefs, or an IDENTIFIER_NODE in the case of structs, unions or enums that are known with a tag, or zero for types that have no special name.这个信息是非常有用的。
The TYPE_CONTEXT for any sort of type which could have a id or which could have named members (e.g. tagged types in C/C++) will point to the node which represents the scope of the given type, or will be NULL_TREE if the type has "file scope". For most types, this will point to a BLOCK node or a FUNCTION_DECL node, but it could also point to a FUNCTION_TYPE node (for types whose scope is limited to the formal parameter list of some function type specification) or it could point to a RECORD_TYPE, UNION_TYPE or QUAL_UNION_TYPE node (for C++ "member" types).
For non-tagged-types, TYPE_CONTEXT need not be set to anything in particular, since any type which is of some type category (e.g. an array type or a function type) which cannot either have a id itself or have named members doesn't really have a "scope" per se.
TYPE_FIELDS chain of FIELD_DECLs for the fields of the struct, VAR_DECLs, TYPE_DECLs and CONST_DECLs for record-scope variables, types and enumerators and FUNCTION_DECLs for methods associated with the type.
TREE_TYPE type of value returned. TYPE_ARG_TYPES list of types of arguments expected. this list is made of TREE_LIST nodes. In this list TREE_PURPOSE can be used to indicate the default value of parameter (used by C++ frontend).
METHOD_TYPE is the type of a function which takes an extra first argument for "self", which is not present in the declared argument list. The TREE_TYPE is the return type of the method. The TYPE_METHOD_BASETYPE is the type of "self". TYPE_ARG_TYPES is the real argument list, which includes the hidden argument for "self".
Declarations. All references to names are represented as ..._DECL nodes. The decls in one binding context are chained through the TREE_CHAIN field. Each DECL has a DECL_NAME field which contains an IDENTIFIER_NODE. (Some decls, most often labels, may have zero as the DECL_NAME). DECL_CONTEXT points to the node representing the context in which this declaration has its scope. For FIELD_DECLs, this is the RECORD_TYPE, UNION_TYPE, or QUAL_UNION_TYPE node that the field is a member of. For VAR_DECL, PARM_DECL, FUNCTION_DECL, LABEL_DECL, and CONST_DECL nodes, this points to either the FUNCTION_DECL for the containing function, the RECORD_TYPE or UNION_TYPE for the containing type, or NULL_TREE or a TRANSLATION_UNIT_DECL if the given decl has "file scope".
The TREE_TYPE field holds the data type of the object, when relevant.
For TYPE_DECL, the TREE_TYPE field contents are the type whose name is being declared.
PARM_DECLs use a special field:
DECL_ARG_TYPE is the type in which the argument is actually passed, which may be different from its type within the function.
FUNCTION_DECLs use four special fields:我觉得这个一定要自己亲自实践才能真正理解。
DECL_ARGUMENTS holds a chain of PARM_DECL nodes for the arguments.
DECL_RESULT holds a RESULT_DECL node for the value of a function.
The DECL_RTL field is 0 for a function that returns no value. (C functions returning void have zero here.)
The TREE_TYPE field is the type in which the result is actually returned. This is usually the same as the return type of the FUNCTION_DECL, but it may be a wider integer type because of promotion.
DECL_FUNCTION_CODE is a code number that is nonzero for built-in functions. Its value is an enum built_in_function that says which built-in function it is.
DECL_SOURCE_FILE holds a filename string and DECL_SOURCE_LINE holds a line number. In some cases these can be the location of a reference, if no definition has been seen.
DECL_ABSTRACT is nonzero if the decl represents an abstract instance of a decl (i.e. one which is nested within an abstract instance of a inline function.
八月二日 等待变化等待机会
/* An OFFSET_REF is used in two situations:
1. An expression of the form `A::m' where `A' is a class and `m' is
a non-static member. In this case, operand 0 will be a TYPE
(corresponding to `A') and operand 1 will be a FIELD_DECL,
BASELINK, or TEMPLATE_ID_EXPR(corresponding to `m').
The expression is a pointer-to-member if its address is taken,
but simply denotes a member of the object if its address is not
taken.
This form is only used during the parsing phase; once semantic
analysis has taken place they are eliminated.
2. An expression of the form `x.*p'. In this case, operand 0 will
be an expression corresponding to `x' and operand 1 will be an
expression with pointer-to-member type. */
/* A pointer-to-member constant. For a pointer-to-member constant
`X::Y' The PTRMEM_CST_CLASS is the RECORD_TYPE for `X' and the
PTRMEM_CST_MEMBER is the _DECL for `Y'. */
/* A reference to a member function or member functions from a base
class. BASELINK_FUNCTIONS gives the FUNCTION_DECL,
TEMPLATE_DECL, OVERLOAD, or TEMPLATE_ID_EXPR corresponding to the
functions. BASELINK_BINFO gives the base from which the functions
come, i.e., the base to which the `this' pointer must be converted
before the functions are called. BASELINK_ACCESS_BINFO gives the
base used to name the functions.
A BASELINK is an expression; the TREE_TYPE of the BASELINK gives
the type of the expression. This type is either a FUNCTION_TYPE,
METHOD_TYPE, or `unknown_type_node' indicating that the function is
overloaded. */
消灭人类暴政,世界属于三体开始,经过了
毁灭你与你何干?,终于结束于
小宇宙回归大宇宙。
struct GTY(()) tree_template_decl {
struct tree_decl_common common;
tree arguments;
tree result;
};
macro remarks DECL_ARGUMENTS In FUNCTION_DECL, a chain of ..._DECL nodes. DECL_TEMPLATE_INFO /* If non-NULL for a VAR_DECL, FUNCTION_DECL, TYPE_DECL, TEMPLATE_DECL, or CONCEPT_DECL, the entity is either a template specialization (if DECL_USE_TEMPLATE is nonzero) or the abstract instance of the template itself. In either case, DECL_TEMPLATE_INFO is a TEMPLATE_INFO, whose TI_TEMPLATE is the TEMPLATE_DECL of which this entity is a specialization or abstract instance. The TI_ARGS is the template arguments used to specialize the template. Consider: template <typename T> struct S { friend void f(T) {} }; In this case, S<int>::f is, from the point of view of the compiler, an instantiation of a template -- but, from the point of view of the language, each instantiation of S results in a wholly unrelated global function f. In this case, DECL_TEMPLATE_INFO for S<int>::f will be non-NULL, but DECL_USE_TEMPLATE will be zero.DECL_VINDEX This field is NULL for a non-virtual function. For a virtual function, it is eventually set to an INTEGER_CST indicating the index in the vtable at which this function can be found. When a virtual function is declared, but before it is known what function is overridden, this field is the error_mark_node. Temporarily, it may be set to a TREE_LIST whose TREE_VALUE is the virtual function this one overrides, and whose TREE_CHAIN is the old DECL_VINDEX.
struct A{
int A::* const p;
};
int A::* const A::* p1 = &A::p;
static_assert(is_same_v<decltype(A::p), int A::* const>);
static_assert(is_same_v<decltype(p1), int A::* const A::*>);
struct A{
int m;
int A::* const p1;
int A::* p2;
};
A a{1, &A::m};
a.p2=a.p1;
偏移,明白了这一点就能够理解A::m的代表偏移的意义了。
struct B{
void base(){}
static void base(int){};
};
void (B::* pMember)()= &B::base;
void (*pStatic)(int)=&B::base;
(B{}.*pMember)();
(*pStatic)(0);
包裹着变量名的,这里我一开始还担心取地址&B::base得到的有可能有歧义需要static_cast,事实证明编译器足够聪明不会选择静态函数,事实上从类型也可以理解所谓的static成员函数根本和类没有关系,它们不是method而是procedure,仅仅是不同
scope而已,也就是说它是一个scope在类里的普通
自由函数,它们的签名是截然不同,没有任何歧义!最后要记住函数指针的调用也是一样遵循它们的定义,必须要在{}里使用dereference的*。这一点我一开始感到不可思议,这个实在是太平常不过了。
多数人因为看到才相信,少数人因为相信所以才看到。
不足为外人道也!不应该被外界程序员所了解,因为没有意义,除非你是开发者,但是如果你是开发者你基本不需要看文档,直接看代码就好了呀?这个真的是另一个悖论,就和我遵循的看电影的原则是一样的,因为我从来不看我没有看过的电影,因为我讨厌看烂片一定是看那些我喜欢看的电影。很多公司招人也是一定要有本行工作经验的才行,如果全部公司都遵守这个原则那么永远都不会有新人能够入行了。这就是难题啊。所谓的tree一定是要包含tree_base,它是所有的类型的核心或者如同基类一样的东西,它包含了几个最重要的共同的部分,其中有TREE_CODE,这个大都定义在tree.def里的enum。 算了我还是遇到具体问题再去搜索相关的tree吧。
八月三日 等待变化等待机会
(gdb) p TREE_CODE(current_class_type)
$426 = RECORD_TYPE
(gdb) p TREE_CODE(TYPE_FIELDS(current_class_type))
$427 = TYPE_DECL
(gdb) p TREE_CODE(DECL_NAME(TYPE_FIELDS(current_class_type)))
$428 = IDENTIFIER_NODE
/* Setup a TYPE_DECL node as a typedef representation.
X is a TYPE_DECL for a typedef statement. Create a brand new
..._TYPE node (which will be just a variant of the existing
..._TYPE node with identical properties) and then install X
as the TYPE_NAME of this brand new (duplicate) ..._TYPE node.
The whole point here is to end up with a situation where each
and every ..._TYPE node the compiler creates will be uniquely
associated with AT MOST one node representing a typedef name.
This way, even though the compiler substitutes corresponding
..._TYPE nodes for TYPE_DECL (i.e. "typedef name") nodes very
early on, later parts of the compiler can always do the reverse
translation and get back the corresponding typedef name. For
example, given:
typedef struct S MY_TYPE;
MY_TYPE object;
Later parts of the compiler might only know that `object' was of
type `struct S' if it were not for code just below. With this
code however, later parts of the compiler see something like:
struct S' == struct S
typedef struct S' MY_TYPE;
struct S' object;
And they can then deduce (from the node for type struct S') that
the original object declaration was:
MY_TYPE object;
Being able to do this is important for proper support of protoize,
and also for generating precise symbolic debugging information
which takes full account of the programmer's (typedef) vocabulary.
Obviously, we don't want to generate a duplicate ..._TYPE node if
the TYPE_DECL node that we are now processing really represents a
standard built-in type. */
if (DECL_IS_BUILTIN (x) && TREE_CODE (TREE_TYPE (x)) != ARRAY_TYPE){
if (TYPE_NAME (TREE_TYPE (x)) == 0)
TYPE_NAME (TREE_TYPE (x)) = x;
}
if (TREE_TYPE (x) != error_mark_node && DECL_ORIGINAL_TYPE (x) == NULL_TREE){
tree tt = TREE_TYPE (x);
DECL_ORIGINAL_TYPE (x) = tt;
tt = build_variant_type_copy (tt);
TYPE_STUB_DECL (tt) = TYPE_STUB_DECL (DECL_ORIGINAL_TYPE (x));
TYPE_NAME (tt) = x;
TREE_TYPE (x) = tt;
}
/* It's important that push_template_decl below follows set_underlying_type above so that the created template carries the properly set type of VALUE. */因为接下来的push_template_decl是一个相当复杂的过程,而且这些部分已经不再有严格的语法规范的要求了,我的感觉这里更多的是内部实现的细节部分吧?总之,究竟怎么保存typedef的信息这一点我还是不太明确。
一道闪电裂长空,裂长空。我感觉我可能是发现了可能的问题的根源,但是要确认和找到可能的修补的办法可能还是非常的遥远,大概还需要gdb几万行代码吧?在c++的parsing几行看似简单的模板源代码的解析工作可能是要走过几万行代码,稍不留神错过一个函数可能就是错过了几千行代码。这个让我想起了《三体》最后的章节,程心和关一帆在蓝星上考察回来被困在黑域里的几天时间结果大宇宙就经历了一千七百多万年的时间,这个比神话里的
天上方一日,世上已千年还要久远的多得多。而
云天明的三个童话里的长帆没想到却暗合着关一帆,这个露珠公主最后的归宿的那个长帆竟然不是云天明自己,这个预言实在是太让人哀叹了,但是难道云天明已经看到了未来?也许三体文明有某种预测未来的手段?
八月四日 等待变化等待机会
无用的const,so what?这个就是出错了吗?用户违法语法了吗?至少gcc的处理方式是错误的,深层次的问题是gcc忽略了这个类型是dependent-type的时候没有保持在这个id下检查它的context以便保持typedef的定义来源特性,因为reference只有在typedef的情况下才允许引入类型。相对应的clang处理的最好,因为它接受并且给出了警告说那个const被忽略了,其次msvc也还可以因为接受了但是没有给警告,这个应该是有可能加开关输出的吧?总之,gcc做的不对,我准备提一个bug。
八月五日 等待变化等待机会
Johannes Schaub says "in both situations the question is whether the parameter type adjustments happen immediately or after instantiation (when T is replaced by the actual type)", regarding the possibility that http://gcc.gnu.org/bugzilla/show_bug.cgi?id=49051 is related.我一开始也是这样子认为的,可是,我总是觉得有什么地方不是很清楚。
八月六日 等待变化等待机会
八月七日 等待变化等待机会
八月八日 等待变化等待机会
If a typedef-name ([dcl.typedef], [temp.param]) or a decltype-specifier ([dcl.type.decltype]) denotes a type TR that is a reference to a type T, an attempt to create the type “lvalue reference to cv TR” creates the type “lvalue reference to T”, while an attempt to create the type “rvalue reference to cv TR” creates the type TR.我是这么总结reference collapsing的:
八月九日 等待变化等待机会
elt这类的iterator把模板声明和参数代入一些所谓的hashtable来搜索,这些构成了GCC庞大复杂的搜索体系,这些虽然复杂但是我们不需要关心它的实现,我在想clang之类的在这种实现上不一定就不如GCC因为毕竟GCC很多实现是很古老的纯粹C语言的方式,还需要强制的实现垃圾回收,而不是依赖引用计数的自动方式,也许效率高了一点点,代价是太难以维护了吧?
停下来试试看吧?我对于她的这句话始终理解不透
如果有个人拯救了人类或毁灭了人类,那你可能的功绩和罪恶,都将正好是他的一倍。为什么正好是一倍呢?似乎主人公汪淼和史强也都问过同样的问题。
申玉菲这个名字也许是作者找的一个歌手的影子,应该很容易联想到她和
王菲的形象有一点类似,因为她有可能来自上海就是申,而玉菲就是有一点的王菲了。《三体》里很多名字都是来自英文,这个是最容易理解的部分,可是这里居然这么瞎联系。史强(strength/strong),罗辑(logic)这个是最明显的例子。艾AA我觉得是来自于中文和法语的结合,艾就是中文的爱,而AA就是法语的Amour, Amour,也就是爱啊爱啊,这个暗示她就是一个多情的种子,和书中描述的未来人代表的率性滥爱是一致的,她最后和云天明的结合似乎也是顺理成章的吧?两个截然相反的男女在地球文明毁灭之后的伊甸园里发生的必然。
八月十日 等待变化等待机会
implicit typedef的概念,但是忘记了具体是什么,这里看到的情况是它的DECL_IMPLICIT_TYPEDEF_P被设定了,而它的TYPE_NAME和TYPE_STUB_DECL都指向一个刚才设定的为typedef的TYPE_DECL,就是说在TYPE_DECL包裹了一层。这个实在是太复杂了,我希望我不会遇到。
小函数lookup_template_class_1我总感到一丝的狐疑,英文就是
fishy,说它小是也不过几百行的代码,但是它的复杂程度让人感到头疼,注释自己都流露出对于它的不安,因为它在完全不同的阶段被调用过两次。而最让我不愿意看到的是对于传入参数好几个地方都进行了修改与替换,这个是代码里我以为最头疼的地方,它为了营造一种虚假的参数一致性把多个实质上的函数集成在一个函数里来处理,这个应该是当年c程序员对于变量名惜字如金的
习惯,这让我想起了从前的前辈导师介绍远古时代编程的时候甚至要节约纸带上的常量。总之,第一次看这个函数是看不懂的,以后可能会反复在这里打圈子先留一个记号吧。
/* For FIELD_DECLs, this is the RECORD_TYPE, UNION_TYPE, or
QUAL_UNION_TYPE node that the field is a member of. For VAR_DECL,
PARM_DECL, FUNCTION_DECL, LABEL_DECL, RESULT_DECL, and CONST_DECL
nodes, this points to either the FUNCTION_DECL for the containing
function, the RECORD_TYPE or UNION_TYPE for the containing type, or
NULL_TREE or a TRANSLATION_UNIT_DECL if the given decl has "file
scope". In particular, for VAR_DECLs which are virtual table pointers
(they have DECL_VIRTUAL set), we use DECL_CONTEXT to determine the type
they belong to. */
八月十一日 等待变化等待机会
一鱼两吃的做法,使用location_t来记录位置同时表达有哪些cp_decl_spec遇到过,这个投机的做法我很担心会被遗漏。,至于说参数本身的类型则是在cp_decl_specifier_seq的成员type里保存着,它的TREE_CODE(parameter->decl_specifiers.type)是TYPENAME_TYPE,所以,这里最让我感到收获的是对于const并不是类型本身的一部分,比如使用TYPE_QUALS(parameter->decl_specifiers.type)是得不到它的真实的cv-qualifier的,那么代码是如何处理的就是以后的关注的重点。换句话说,就是parser得到的参数类型的所有信息是要依赖于两部分的,这个部分我不知道是不是因为是typename的特殊情况呢?我以前看到过讨论说const是不能放在typename后面的,这个是语法本身的设定,这个是否是一个因素呢?
/* In grokdeclarator, distinguish syntactic contexts of declarators. */
enum decl_context
{ NORMAL, /* Ordinary declaration */
FUNCDEF, /* Function definition */
PARM, /* Declaration of parm before function body */
TPARM, /* Declaration of template parm */
CATCHPARM, /* Declaration of catch parm */
FIELD, /* Declaration inside struct or union */
BITFIELD, /* Likewise but with specified width */
TYPENAME, /* Typename (inside cast or sizeof) */
TEMPLATE_TYPE_ARG, /* Almost the same as TYPENAME */
MEMFUNCDEF /* Member function definition */
};
八月十二日 等待变化等待机会
三花聚顶,五气朝元的基本道家术语也看不懂,竟然要在交战中套路马钰才能理解,这个就是没有基础看不懂
黑话或者叫做行业术语的痛苦。
Knowing the path is completely different from walking the path。否则《Matrix》里Morpheus从Oracle那里已经知道全部的路径为什么自己不去趟路非要苦苦寻找Neo来走那条路呢?知易行难是人人都知道的道理,但是依然未必人人都能亲自实践。归根结底是在它的context是FUNCDEF的时候,传入的declarator是函数的参数,而declspecs指的是函数它包含了函数的返回值以及其他信息,所以,只有在这个时间点才是问题的关键!我这里重复了昨晚的战术,就是这里参数不能直接实用%qA来打印只能使用它的类型%aT来打印TREE_TYPE(TREE_VALUE(declarator->u.function.parameters))。当然grokdeclarator返回的是一个函数声明是可以使用函数声明的%qF来打印的。结果就是输入的参数是const typename A<T>::Type返回的函数签名是void f(typename A<T>::Type),参数的const丢失了,我认为是typedef的信息没有被考虑,但是这个函数至少是
四舍五入看成了四千行代码!我真的是老糊涂了。好消息就是需要debug的代码
减少了一千多行!
/*
* Cv-qualified references are ill-formed except when the cv-qualifiers
* are introduced through the use of a typedef-name ([dcl.typedef],
* [temp.param]) or decltype-specifier ([dcl.type.decltype]),
* in which case the cv-qualifiers are ignored.
*/
八月十三日 等待变化等待机会
八月十四日 等待变化等待机会
假的吗?而克隆的TYPE_NAME指向了原先的TYPE_DECL,这里我都看晕了,到底这些东西在哪里有文档描述呢?这些只能考验程序员的读码能力,但是不同场景的需求是不一样的,没有说明记忆力差就痛苦了。
variant,核心就是使用TYPE_NAME
/* Setup a TYPE_DECL node as a typedef representation.
X is a TYPE_DECL for a typedef statement. Create a brand new
..._TYPE node (which will be just a variant of the existing
..._TYPE node with identical properties) and then install X
as the TYPE_NAME of this brand new (duplicate) ..._TYPE node.
The whole point here is to end up with a situation where each
and every ..._TYPE node the compiler creates will be uniquely
associated with AT MOST one node representing a typedef name.
This way, even though the compiler substitutes corresponding
..._TYPE nodes for TYPE_DECL (i.e. "typedef name") nodes very
early on, later parts of the compiler can always do the reverse
translation and get back the corresponding typedef name. For
example, given:
typedef struct S MY_TYPE;
MY_TYPE object;
Later parts of the compiler might only know that `object' was of
type `struct S' if it were not for code just below. With this
code however, later parts of the compiler see something like:
struct S' == struct S
typedef struct S' MY_TYPE;
struct S' object;
And they can then deduce (from the node for type struct S') that
the original object declaration was:
MY_TYPE object;
Being able to do this is important for proper support of protoize,
and also for generating precise symbolic debugging information
which takes full account of the programmer's (typedef) vocabulary.
Obviously, we don't want to generate a duplicate ..._TYPE node if
the TYPE_DECL node that we are now processing really represents a
standard built-in type. */
八月十五日 等待变化等待机会
八月十六日 等待变化等待机会
八月十七日 等待变化等待机会
八月十八日 等待变化等待机会
typename-specifier:
typename nested-name-specifier identifier
typename nested-name-specifier templateopt simple-template-id
八月十九日 等待变化等待机会
一个定义的原则(ODR)。但是仔细阅读我才发现这里着重讲的是所谓的ADL(Argument-Dependent-Lookup这个和我关注的有距离。
我感觉我的情况包含了至少两种:The following types are dependent types:
- template parameter
- a member of an unknown specialization (see below)
- a nested class/enum that is a dependent member of unknown specialization (see below)
- a cv-qualified version of a dependent type
- a compound type constructed from a dependent type
- an array type whose element type is dependent or whose bound (if any) is value-dependent
- a function type whose parameters include one or more function parameter packs
(since C++11)
- a function type whose exception specification is value-dependent
(since C++17)
- a template-id where either
- the template name is a template parameter, or
- any of template arguments is type-dependent, or value-dependent, or is a pack expansion (since C++11) (even if the template-id is used without its argument list, as injected-class-name)
- the result of
decltypeapplied to a type-dependent expressionThe result of
decltypeapplied to a type-dependent expression is a unique dependent type. Two such results refer to the same type only if their expressions are equivalent.(since C++11) Note: a typedef member of a current instantiation is only dependent when the type it refers to is.
void f1(auto); // same as template<class T> void f(T)C++ Concepts Technical Specification,这个应该是GCC报出来警告的源头。
科学边界如果人类不把自己的地位让度给人工智能的话,所以从这个意义来看让有着某种人工智能特征的记忆传递的三体人应该是人类文明的主宰。当然如果将来人类发明了记忆输入输出能力也许这个是可以改变的,但是我对于这个相当的不乐观,除非人类发展出了所谓的体外记忆辅助存储方式才有希望。
Yet another approach for constrained declarations是标准的出处。
P1141R2,那么就应该报错而不是给出模凌两可的警告?
warning: use of ‘auto’ in parameter declaration only available with ‘-fconcepts-ts’
1 | void f(auto i){}
| ^~~~
八月二十日 等待变化等待机会
template<class T> T::R f(); // OK, return type of a function declaration at global scope
error: need ‘typename’ before ‘T::R’ because ‘T’ is a dependent scope
1 | template<class T> T::R f();
| ^
| typename
The global scope contains the entire program;基本上这个定义是对于实际操作是无用的,只能是用反证来定义
every other scope S is introduced by a declaration, parameter-declaration-clause, statement, or handler (as described in the following subclauses of [basic.scope]) appearing in another scope which thereby contains S.我现在在想也许这个和是否是global scope无关,而是说这个是所谓的type-only context,因为这个id一定就是一个type,没有其他,period。
The locus of a declaration ([basic.pre]) that is a declarator is immediately after the complete declarator ([dcl.decl]).这个简直就是绕口令,locus是一个declarator身后的影子吗?可是它是另一个declarator!而且是紧接着之前刚声明完的那个,所以,活脱脱就是
影武者!这个例子说明了什么是locus,可是我已经没有胃口看了,这个和我有什么关系?我为什么要关心它?
#include<type_traits>
typedef int T;
template<class T
= T // lookup finds the typedef-name
>
struct A { };
static_assert(std::is_same<A<>, A<int>>::value,"template parameter locus!");
影武者根本和我的问题无关,它是解决特定declarator身后紧接着的那个重名declarator的问题。我没有这个烦恼。不过现在知道了locus好烦人啊,难怪代码里反复出现。
True if SCOPE designates the global scope binding contour,这个contour是什么概念?
late return type这里终于看到它是什么了。这个和
trailing return type是一回事吗? 我试图使用模板的默认参数来解决,但是才意识到模板类型是无法作为表达式来结算操作结果的,也就是说这个是不可能的 所以,只有使用所谓的late return type 这个才是正解!
int main(){
for (int i=0; i<10; i++){
int i=10;
}
}
1010.cpp: In function ‘main’:
1010.cpp:4:7: warning: declaration of ‘i’ shadows a previous local [-Wshadow]
int i=10;
^
1010.cpp:2:11: note: shadowed declaration is here
for (int i=0; i<10; i++)
^
1010.cpp: In function ‘int main()’:
1010.cpp:4:7: error: redeclaration of ‘int i’
int i=10;
^
1010.cpp:2:11: note: ‘int i’ previously declared here
for (int i=0; i<10; i++)
^
八月二十一日 等待变化等待机会
xxx_diagnose_invalid_type_name函数的原因。
(gdb) p TREE_CODE(TREE_TYPE((tree)(0x7ffff7270b48)))
$1411 = ARRAY_TYPE
八月二十二日 等待变化等待机会
发现了它,很快的修改完善了,其中最重大的改进是不再手动下载GCC的配套程序,而是使用自带的下载工具download_prerequisites来下载。我相信它也很容易扩展为编译snapshot,这个随后再做吧。
丧心病狂的例子,结果GCC又失败了。 而clang和VC++表示毫无压力!唉!这就是号称当今业界标杆的GCC啊!我只能顺手再添加了一个补丁,我对于自己能够不到半小时就改出来表示不可思议,为什么之前花了两个月而现在犹如神助?其实我是闭着眼睛在resolve_typename_type添加了一个根据我的结果返回的选择,这个是属于no-brainer,我压根不明白为什么只是看到lookup_member找到了我需要的却没有返回就造了这么一个返回结果
/* If we failed to resolve it, return the original typename. */
if (!result)
{
if (TREE_CODE (fullname) == TEMPLATE_ID_EXPR
&& TREE_CODE (decl) == TEMPLATE_DECL)
return TREE_TYPE(decl);
return type;
}
八月二十四日 等待变化等待机会
这就不是事!,而MSVC++弱弱的说不太对吧? GCC给出的错误让人摸不着头脑。
八月二十六日 等待变化等待机会
E.g. consider the following declarations:
typedef const int ConstInt;
typedef ConstInt* PtrConstInt;
If T is PtrConstInt, this function returns a type representing
const int*.
In other words, if T is a typedef, the function returns the underlying type.
The cv-qualification and attributes of the type returned match the
input type.
They will always be compatible types.
The returned type is built so that all of its subtypes
recursively have their typedefs stripped as well.
struct A;
template <class T> void f (void (A::* const)(T)) {}
void (*p)(void (A::* const)(int)) = f;
八月二十七日 等待变化等待机会
八月二十八日 等待变化等待机会
错误:keyword ‘template’ not allowed in declarator-id [-Wpedantic]
11 | void f(const typename A<TA>::template B<TB>::Arr3){}
| ^~~~~
#pragma GCC diagnostic ignored "-Wpedantic"
void f(const typename A<TA>::template B<TB>::Arr3){}
八月二十九日 等待变化等待机会
弱类型语言里不是问题的问题,在c++里是大问题。就是说编译器随时随地都要知道自己在干什么,怎么干。也就是说不能有丝毫的模糊性。一个id是类型还是变量名是
兹事体大的问题。我上一次看到那篇c++20消除typename的论文好像题目是down typename吧?里也是相关的就是在某些情况下typename是不必须的,因为除了类型它不可能有别的可能性。我记得它也是说的所谓的dependent-name吧?还是nested-specifier?总之这里说的是标准里的name lookup的概念
Some names denote types or templates. In general, whenever a id is encountered it is necessary to determine whether that name denotes one of these entities before continuing to parse the program that contains it. The process that determines this is called name lookup.
In particular, types and expressions may depend on types of type template parameters and values of non-type template parameters.
Non-dependent names are looked up and bound at the point of template definition. This bindingholds even if at the point of template instantiation there is a better match那么真的有better match这个情况吗?
If the meaning of a non-dependent name changes between the definition context and the point of instantiation of a specialization of the template, the program is ill-formed, no diagnostic required.
the lookup of a dependent name used in a template is postponed until the template arguments are known, at which time这里其实非常的难懂,首先,我虽然明白ADL是什么,但是怎么判断的?意思应该都是是在本scope范围内找不到函数的声明对吗?所以non-ADL才要看external linkage,这里也许是说已经使用ADL-lookup了吗?这里的template definition context做何解呢?ADL是明显的,肯定就是要去模板名的所在的模板定义项下去找?总之这里其实很复杂的一个过程。我在代码里看到不少的lookup但是不理解什么时候用什么。
- non-ADL lookup examines function declarations with external linkage that are visible from the template definition context
- ADL examines function declarations with external linkage that are visible from either the template definition context or the template instantiation context
A name used in a template declaration or definition and that is dependent on a template-parameter is assumed not to name a type unless the applicable name lookup finds a type name or the name is qualified by the keyword typename.这里我们学到了什么?就是说typename不是随便给的,如果不是dependent name是一个dependent type的话是不能随便给typename头衔的,就像例子里的,如果
typename T::A* a6; // declare pointer to T's A
T::A* a7; // T::A is not a type name:
// multiplication of T::A by a7; ill-formed, no visible declaration of a7
人狠话不多!就那么几个字我看的头晕目眩,信息量极其的大,说一句顶一万句也不夸张!我实在是没有能力读了。因为牵扯到parameter-declaration的情况就有五种,可是我算哪一种呢?而且它是允许不使用typename,并不是不可以。似乎很难把握吧。至少我怀疑编译器没有真的严格执行。
int type_quals = 0;
/* Inside template declaration, typename and decltype indicating
dependent name and cv-qualifier are preserved until
template instantiation.
PR101402/PR102033/PR102034/PR102039/PR102044 */
if (processing_template_decl
&& (TREE_CODE (type) == TYPENAME_TYPE || TREE_CODE (type) == DECLTYPE_TYPE))
type_quals = CP_TYPE_CONST_P(type);
type = cp_build_qualified_type (type, type_quals);
八月三十一日 等待变化等待机会
typename only before qualified names这句话画龙点睛。
After name lookup (3.4) finds that a id is a template-name, if this name is followed by a <, the < is always taken as the beginning of a template-argument-list and never as a id followed by the less-than operator.我似乎看到过类似的代码在GCC里,看来严格遵守标准是无二法则。但是作者的那个模板的例子我觉得似乎不是很有说服力,因为我想不出怎么能够在同一个名字空间重复定义,这个违反了ODR吧?
九月一日 等待变化等待机会
组,我不知道怎么翻译parameter pack。那么要访问它可以使用ARGUMENT_PACK_ARGS,这个是一个TREE_VEC。与之相对应的是TYPE_PACK_EXPANSION,这个我现在脑子比较乱,这个是声明部分吗?可以使用PACK_EXPANSION_PATTERN取的那个领头的id。还有什么尾追部分。牵扯到parameter pack,别说编译了,就是使用我都犯难。
九月二日 等待变化等待机会
乍起秋风扑面寒, 朝雨匆匆路半干。 秋叶秋实随风曳, 落与不落都两难。
九月三日 等待变化等待机会
九月四日 等待变化等待机会
蜕变成指针,可是这个过程真的很复杂,我在反反复复的tsubst_xxx的函数里兜了一圈又一圈。而我对于这段代码
pt.c:tsubst_arg_types的正确性感到迷茫
/* Do array-to-pointer, function-to-pointer conversion, and ignore
top-level qualifiers as required. */
type = cv_unqualified (type_decays_to (type));
九月五日 等待变化等待机会
九月六日 等待变化等待机会
聪明就是说能省则省,非常的令人讨厌,不要轻易的认为代码有问题,即便有问题也是有理由,老牌的程序员就是这种怪脾气,代码没有错是改bug的人改出来的错,如果一定是运行结果有问题,那就是标准改了,总之代码没有错,是读码的人水平不够看不懂,如果,你一定认为代码错了,那是你的母语不是英语,你看不懂注释。这种牛气冲天的霸道让无数的自认为不够霸气的程序员去了clang。这就是GCC和clang的故事。
type unification的过程,简而言之就是把实参和不确定个数的型参的比对统一的过程,实际上也是一个验证声明与表达式之间是否合法的过程,这个的确是一个非常复杂的过程,其中的代码非常的复杂,想想看单单使用这些...就是程序员的一个噩梦不要说编译器怎样条理清晰的检验匹配了,我个人对于这些让人看着发毛的小点点是有说不出来的敬畏之心的,因为不知道怎么才是正确的使用方法。
九月七日 等待变化等待机会
p IDENTIFIER_POINTER(DECL_NAME(TYPE_NAME(TREE_TYPE(t))))p IDENTIFIER_POINTER(DECL_NAME(TYPE_NAME(TREE_TYPE(parm))))九月八日 等待变化等待机会
or和我的意思不一样,我是说我的问题同时牵涉到了两个方面。
九月九日 等待变化等待机会
/* Whether the argument pack is "incomplete", meaning that more
arguments can still be deduced. Incomplete argument packs are only
used when the user has provided an explicit template argument list
for a variadic function template. Some of the explicit template
arguments will be placed into the beginning of the argument pack,
but additional arguments might still be deduced. */
/* In VAR_DECL, PARM_DECL and RESULT_DECL nodes, nonzero means address
of this is needed. So it cannot be in a register.
In a FUNCTION_DECL it has no meaning.
In LABEL_DECL nodes, it means a goto for this label has been seen
from a place outside all binding contours that restore stack levels.
In an artificial SSA_NAME that points to a stack partition with at least
two variables, it means that at least one variable has TREE_ADDRESSABLE.
In ..._TYPE nodes, it means that objects of this type must be fully
addressable. This means that pieces of this object cannot go into
register parameters, for example. If this a function type, this
means that the value must be returned in memory.
In CONSTRUCTOR nodes, it means object constructed must be in memory.
In IDENTIFIER_NODEs, this means that some extern decl for this name
had its address taken. That matters for inline functions.
In a STMT_EXPR, it means we want the result of the enclosed expression. */
[in]complete的属性的。暂时到这里吧。
九月十日 等待变化等待机会
九月十一日 等待变化等待机会
新语言的前端实际上并不那么容易,否则也不会有传闻这个无名的小公司EDG的产品居然被这么多大公司使用,据说微软的IDE也使用EDG,当然这个是我听说。总之我找到了问题的可能源头就是这个标志量ARGUMENT_PACK_INCOMPLETE_P的设定与消除,根据注解它是为了大概是什么默认参数的支持而设定
/* Mark the argument pack as "incomplete". We could
still deduce more arguments during unification.
We remove this mark in type_unification_real. */
/* The template parameter pack is used in a function parameter
pack. If this is the end of the parameter list, the
template parameter pack is deducible. */
九月十二日 等待变化等待机会
九月十三日 等待变化等待机会
九月十四日 等待变化等待机会
九月十五日 等待变化等待机会
x86_64-apple-darwin11.1.0那么binaryformat就不是ELF,苹果居然是MachO,我实在是太孤陋寡闻了,我一直以为苹果也是Linux,应该使用的binary是一样的ELF,没想到他们这么卑鄙竟然来了个釜底抽薪强制要把你封闭在外,这才是狠招子,操作系统的核心就在于可执行程序运行的操纵上,不在这个根本的load&run上做文章岂不是奇怪吗?我怎么会想不到呢?
immutable once created所带来的好处似乎处处都是瞄准了GCC的核心问题,因为最近这个bug我之所以放弃的一个原因就是程序员在解析的时候随手修改了ARGUMENT_PACK_INCOMPLETE_P,注解上说这个是一个类似临时的标志量,在随后的过程会消除,结果在不同的路径上它起了不同的作用导致了这个bug,我看了无语也不敢改,天知道有多少问题会牵连出来呢?所以,clang设计的哲学这一点很关键。另一个就是和我遇到的众多的模板问题息息相关,到底AST里要保留多少的原始信息,对于一个模板的声明和它众多的实例化是否保留多个声明,这些都是要害问题。我只能意会但是不能真的体会。究竟所谓的CanonicalType是怎么做到的?这些原则说起来容易做起来难,对于dependenttype你怎么能够一次定型呢?什么时候创建AST算是结束,不经过查找能行吗?那么这个过程是否有临时的半成品呢?这些对于我这个门外汉只能是瞎猜。这么看来这个小小的内部文档还是有价值收藏的。
九月十六日 等待变化等待机会
The difference is the name of the mangled identifier (这个只能说是不明觉厉了,前者是匿名的名字空间的mangle,后者是static的,这里我对于汇编的数据区不熟悉,也不想也不能深入了因为第一重第二重匿名名字空间是怎么办的太复杂了,对我也没有用了。 这里提到的local symbols,似乎在代码里哪里看到过,这个难道是所谓scope里lookup的一个特殊的表吗?这个是每个文件都分配一个那么在GCC里parse一个文件的时候分配一个结束就丢弃掉因为外界是不能访问的,以后也不可能被使用,在编译好的symbol里不加.global,这个是否就是和c语言的static一样了,当然除了mangled name之外,但是不同文件它重名也没有关系了吧?虽然mangled是一样的。我看到clang这个做法的好处是在本文件里使用这个匿名名字空间的元素不需要任何scope就好像全局变量一样,但是我一旦想把它纳入我自己的在另一个文件的同样的名字空间里就有问题了,这个是好事,它阻止了你的行为因为作者不想你这么干。_ZN12_GLOBAL__N_11bEvs_ZL1b, which doesn't really matter, but both of them are assembled to local symbols in the symbol table (absence of.globalasm directive).
九月十七日 等待变化等待机会
#include "clang/Lex/ModuleLoader.h"
clang::TrivialModuleLoader modLoader;
int main(){}
九月十八日 等待变化等待机会
linemarker的开关-P才能阻止,这个也就是导致在AST输出有一些系统固有的数组之类的吧。
-fno-rtti我的问题是clang::TrivialModuleLoader会导致undefined reference to `typeinfo for clang::ModuleLoader',那么怎么理解呢?
Disable generation of information about every class with virtual functions for use by the C++ runtime type identification features (dynamic_castandtypeid). If you don't use those parts of the language, you can save some space by using this flag. Note that exception handling uses the same information, but it will generate it as needed. Thedynamic_castoperator can still be used for casts that do not require runtime type information, i.e. casts tovoid *or to unambiguous base classes.
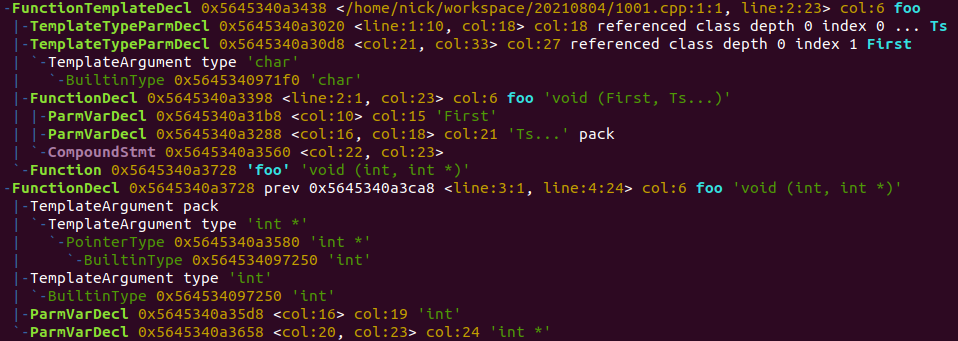
九月十九日 等待变化等待机会
九月二十日 等待变化等待机会
读懂。
A pack expansion consists of a pattern and an ellipsis, the instantiation of which produces zero or more instantiations of the pattern in a list (described below). The form of the pattern depends on the context in which the expansion occurs.这个列表是非常复杂的场景,有很多我始终理解不透,抄写来帮助机械记忆吧。
Pack expansion
A pattern followed by an ellipsis, in which the name of at least one parameter pack appears at least once这个我感到很难理解???, is expanded into zero or more comma-separated instantiations of the pattern, where the name of the parameter pack is replaced by each of the elements from the pack, in order.
If the parameter-declaration-clause terminates with an ellipsis or a function parameter pack ([temp.variadic]), the number of arguments shall be equal to or greater than the number of parameters that do not have a default argument and are not function parameter packs.要怎么理解呢?我的实验结果让我也怀疑这个是所有编译器的问题,但是大概率是我的错误理解,但是我还是提交了bug。 GCC和clang都认为这个是合法的,可是我怎么想也不对,Ts被实例化为int*,double这一点从参数结尾就看出来了,那么Extra是怎么被实例化为double的呢?这个肯定是不合理的。
九月二十一日 等待变化等待机会
Where syntactically correct and where “...” is not part of an abstract-declarator, “, ...” is synonymous with “...”.什么叫做不属于abstract-declarator?难道是说parameter-declaration-clause就已经包含了variadic function的variadic parameter了吗?
parameter-declaration-clause:
parameter-declaration-listopt ...opt
parameter-declaration-list , ...
noptr-abstract-pack-declarator:
noptr-abstract-pack-declarator parameters-and-qualifiers
noptr-abstract-pack-declarator [ constant-expressionopt ] attribute-specifier-seqopt
...
冒险的强制类型转换,根本不需要编译器的支持直接从栈里取指针,或者从寄存器里取参数,这里应该是对于调用约定相关的实现,根本无视语法的。而我们讨论的parameter pack是编译期的类型解析,是风马牛不相关的吧?22.09.2021这里是证明这个根本就不是parameter pack! 我折腾了好久才明白自己为什么总是搞不明白一个简单的道理,c++就是为了避免这个混淆才在函数参数声明里强制规定declarator-id一定是这样子的
noptr-declarator:
declarator-id attribute-specifier-seqopt
noptr-declarator parameters-and-qualifiers
noptr-declarator [ constant-expressionopt ] attribute-specifier-seqopt
( ptr-declarator )
declarator-id:
...opt id-expression
There are three forms of template-argument, corresponding to the three forms of template-parameter: type, non-type and template.,那么argument就是parameter吗?我脑子里还是函数的实参型参的概念,这里可能是误区吧?那么这里说
When the parameter declared by the template is a template parameter pack, it will correspond to zero or more template-arguments.,这句话的理解还真难啊,就是说parameter可以是由parameter pack组成,替换的过程是实例化template argument的过程,这个应该是对应于GCC里的tsubst之类的template substitution的各个函数吧?总之我的困惑就是我对于template-argument的语法的理解上的偏差,它到底和template-parameter是什么关系呢?
template-argument:
constant-expression
type-id
id-expression
template-parameter:
type-parameter
parameter-declaration
noptr-abstract-pack-declarator:
noptr-abstract-pack-declarator parameters-and-qualifiers
noptr-abstract-pack-declarator [ constant-expressionopt ] attribute-specifier-seqopt
...
type-parameter:
type-parameter-key ...opt identifieropt
type-parameter-key identifieropt = type-id
type-constraint ...optidentifieropt
type-constraint identifieropt = type-id
template-head type-parameter-key ...opt identifieropt
template-head type-parameter-key identifieropt = id-expression
declarator-id:
...opt id-expression
template-argument:
constant-expression
type-id
id-expression
type-id:
type-specifier-seq abstract-declaratoropt
abstract-declarator:
ptr-abstract-declarator
noptr-abstract-declaratoropt parameters-and-qualifiers trailing-return-type
abstract-pack-declarator
abstract-pack-declarator:
noptr-abstract-pack-declarator
ptr-operator abstract-pack-declarator
noptr-abstract-pack-declarator:
noptr-abstract-pack-declarator parameters-and-qualifiers
noptr-abstract-pack-declarator [ constant-expressionopt ] attribute-specifier-seqopt
...
error: pack expansion does not contain any unexpanded parameter packs,我决定使用gdb来探究一下。出乎意料的是在众多的DiagnoseUnexpandedParameterPack[s]和类似的函数并没有被调用,这个是我臆想中的clang的处理方式就是按照标准把这些场景都检验一遍,但是这个是在diagnose的方式下,也许是为了debug之类的需求吧?并不是程序运行的做法,反而是使用一个标志量来判断:
bool containsUnexpandedParameterPack() const {
return getDependence() & TypeDependence::UnexpandedPack;
}
/// A type that contains a parameter pack shall be expanded by the
/// ellipsis operator at some point. For example, the typedef in the
/// following example contains an unexpanded parameter pack 'T':
///
/// \code
/// template<typename ...T>
/// struct X {
/// typedef T* pointer_types; // ill-formed; T is a parameter pack.
/// };
/// \endcode
template<typename ...T>
struct X {
typedef T* pointer_types; // ill-formed; T is a parameter pack.
};
反继承的例子,因为没有这个必要使用继承,还不如把特征做成一个个小功能,谁有需要就加在它身上来的灵活,这个摆脱了继承带来的庞大的负担,因为继承是看似
免费的实现,因为语言本身帮你实现了背后的继承工作,就好像嘴里含着金钥匙诞生的富家子自己不用努力就得到了父辈的一切财富一样,而后天的组合是一种有目的的奋斗工作的结果,而且更加的不受前人的约束。所以,这个并非是
反进化论,而是反封建世袭制。所谓的只反贪官不反皇帝,继承的思想还是有的,只不过不再是那么明目张胆的世袭,而是通过内部特征的加载,仿佛现代贵族不再直接把巨额财富传承子女而是通过一些所谓的基金会巧妙的绕开继承税来输送给他的后代。这样做更有精准的避税功能。说了这么多我还是不懂的那个神奇的指针变换怎么就能够掩码三个bit仍能够是正确的指针,大概是精巧的数据结构的设计要考虑align的问题,在一个大内存不管静态动态的连续内存上分配才能做到吧?其实我不需要关心这个细节这个超出了我的能力也无意义。我关心的是怎么使用而已。而这种设计思想似乎比GCC的架构来的优越一些吧?具体是怎样我也不知道。总之是现代的设计。
九月二十二日 等待变化等待机会
九月二十三日 等待变化等待机会
The resulting substituted and adjusted function type is used as the type of the function template for template argument deduction. If a template argument has not been deduced and its corresponding template parameter has a default argument, the template argument is determined by substituting the template arguments determined for preceding template parameters into the default argument.看到这里我似乎有些明白我的例子有问题,就是说如果我已经可以从函数的实参
推理出了参数类型似乎就没有必要再使用default参数了,是吗?就是说默认参数是
最低的优先级要放在最后?也就是说这个函数DeduceTemplateArgumentsByTypeMatch是最后才被调用了。比如 首先从函数foo的模板参数和函数的实参来推测,到了最后再来讨论是否有必要调用那个deduce函数?换言之,default是到了山穷水尽的最后的选择? 我对于这一点还是有些疑惑具体是什么我也想不清楚,标准说的没有错,但是这个default是否解决了呢?因为函数不支持partial specialization,那么我用类来说明: 结果GCC和clang都认为第一个static_assert不成立,clang给的错误很清晰 为什么呢?难道我的模板特例化不成立吗?为什么这里默认参数又提高了优先级呢?
看上去不一样,但是需要明确一点的就是不是说模板型参的个数就能改变模板实参的个数,编译器最终还是要检查型参个数一致才放行的。 这里有两条我要体会:
这两条好像都是针对我的例子的吧?我还是无法体会真正的含义。
- Default arguments cannot appear in the argument list
- If any argument is a pack expansion, it must be the last argument in the list
九月二十四日 等待变化等待机会
如果一个模板需要两个参数,那么哪怕你在特例化下只需要一个模板类型参数,但是你最终传递的还是需要两个参数。这里中文很难表达清楚,英文似乎就比较清晰了,这个parameter你特指的是模板参数声明里的型参,而argument才是模板实例化时候的实参。也就是说不管你需要几个型参最后实例化的时候除非你的模板是parameter pack,否则实参个数是必须正确的,除非有默认参数。所以,昨天的问题是这么理解的,首先当你实例化的时候,编译器先根据模板名来查找primary的模板确定模板参数类型以及个数,这里立刻就引发错误如果个数不够而且又没有默认参数来补齐的话,只有通过了这一关之后才会去在各个特例化中挑选最接近的,这里就牵涉到一个我还始终只闻其名不明所以的partial-ordering,就是说特例化在模板列表里的排列决定了匹配的结果,这个是以后需要理解的,目前我还不够资格。
#include "..." search starts here:
#include <...> search starts here:
/usr/lib/gcc/x86_64-linux-gnu/7.5.0/../../../../include/c++/7.5.0
/usr/lib/gcc/x86_64-linux-gnu/7.5.0/../../../../include/x86_64-linux-gnu/c++/7.5.0
/usr/lib/gcc/x86_64-linux-gnu/7.5.0/../../../../include/c++/7.5.0/backward
/usr/local/include
/usr/local/src/clang-dev/clang-12-debug-build/lib/clang/12.0.1/include
/usr/include/x86_64-linux-gnu
/usr/include
九月二十五日 等待变化等待机会
~/Downloads/cmake-3.18.4/bin/cmake -DCMAKE_C_COMPILER=/home/nick/opt/gcc-10.2.0/bin/gcc -DCMAKE_BUILD_TYPE=RelWithDebInfo -DLLVM_ENABLE_PROJECTS="clang;llvm;libcxx;libcxxabi" -DBUILD_SHARED_LIBS=false -DLLVM_BUILD_DOCS=true -DLLVM_BUILD_EXAMPLES=true -DLLVM_USE_LINKER=gold -DLLVM_ABI_BREAKING_CHECKS="FORCE_OFF" -DDEFAULT_SYSROOT=/home/nick/opt/gcc-10.2.0/ ../llvm-project/llvm
../../../bin/llvm-tblgen: /usr/lib/x86_64-linux-gnu/libstdc++.so.6: version `GLIBCXX_3.4.26' not found (required by ../../../bin/llvm-tblgen)
cd /mnt/sda1/Shared/llvm-dev/llvm-build/include/llvm/IR && ../../../bin/llvm-tblgen -gen-attrs -I /mnt/sda1/Shared/llvm-dev/llvm-project/llvm/include/llvm/IR -I/mnt/sda1/Shared/llvm-dev/llvm-build/include -I/mnt/sda1/Shared/llvm-dev/llvm-project/llvm/include /mnt/sda1/Shared/llvm-dev/llvm-project/llvm/include/llvm/IR/Attributes.td --write-if-changed -o /mnt/sda1/Shared/llvm-dev/llvm-build/include/llvm/IR/Attributes.inc
九月二十六日 等待变化等待机会
Components
git_description- a leading text with git commit descriptioncommitter_timestamp- line with timestamp and an author name and email (2 spaces before and after name)
example:2020-04-23␣␣Martin Liska␣␣<mliska@suse.cz>additional_author- line with additional commit author name and email (starting with a tabular and 4 spaces)
example:\t␣␣␣␣Martin Liska␣␣<mliska@suse.cz>changelog_location- a location to a ChangeLog file
supported formats:a/b/c/ChangeLog,a/b/c/ChangeLog:,a/b/c/(where ChangeLog file lives in the folder),\ta/b/c/anda/b/cpr_entry- bug report reference
example:\tPR component/12345changelog_file- a modified file mentined in a ChangeLog: supported formats:\t* a/b/c/file.c:,\t* a/b/c/file.c (function):,\t* a/b/c/file1.c, a/b/c/file2.c:changelog_file_comment- line that follows achangelog_filewith description of changes in the file; must start with\tco_authored_by- GitHub format for a Co-Authored-By
九月二十七日 等待变化等待机会
/* If non-NULL for a VAR_DECL, FUNCTION_DECL, TYPE_DECL, TEMPLATE_DECL,
or CONCEPT_DECL, the entity is either a template specialization (if
DECL_USE_TEMPLATE is nonzero) or the abstract instance of the
template itself.
In either case, DECL_TEMPLATE_INFO is a TEMPLATE_INFO, whose
TI_TEMPLATE is the TEMPLATE_DECL of which this entity is a
specialization or abstract instance. The TI_ARGS is the
template arguments used to specialize the template.
Consider:
template <typename T> struct S { friend void f(T) {} };
In this case, S<int>::f is, from the point of view of the compiler,
an instantiation of a template -- but, from the point of view of
the language, each instantiation of S results in a wholly unrelated
global function f. In this case, DECL_USE_TEMPLATE for S<int>::f
will be non-NULL, but DECL_USE_TEMPLATE will be zero. */
九月二十八日 等待变化等待机会
clang;clang-tools-extra;compiler-rt;debuginfo-tests;libc;libclc;libcxx;libcxxabi;libunwind;lld;lldb;mlir;openmp;parallel-libs;polly;pstl;对应LLVM_EXTRA_PROJECTS是flang和mlir,后者是前者的依赖。
DEBUG|RELEASE|RELWITHDEBINFO|MINSIZEREL
AArch64 AMDGPU ARM AVR BPF Hexagon Lanai Mips MSP430 NVPTX PowerPC RISCV Sparc SystemZ WebAssembly X86 XCore 所以,可以投机取巧的直接拷贝这三个生成的文件。
cmake(to be filled) header(to be generated) ${SOURCE}/llvm/include/llvm/Config/config.h.cmake ${BUILD}/include/llvm/Config/config.h ${SOURCE}/llvm/include/llvm/Config/llvm-config.h.cmake ${BUILD}/include/llvm/Config/llvm-config.h ${SOURCE}/llvm/include/llvm/Config/abi-breaking.h.cmake ${BUILD}/include/llvm/Config/abi-breaking.h
"If set, an absolute path added as rpath on binaries that do not already contain an executable-relative rpath."我还理解不了
A null pointer constant is an integral constant expression (5.19) prvalue of integer type that evaluates to zero or a prvalue of type std::nullptr_t. A null pointer constant can be converted to a pointer type; the result is the null pointer value of that type and is distinguishable from every other value of object pointer or function pointer type. Such a conversion is called a null pointer conversion.
~/Downloads/cmake-3.18.4/bin/cmake -DLLVM_USE_LINKER=gold -DLLVM_ENABLE_PROJECTS="clang" -DCMAKE_BUILD_TYPE="RELWITHDEBINFO" -DLLVM_TARGETS_TO_BUILD="X86" -DBUILD_SHARED_LIBS=false -DLLVM_BUILD_STATIC=false -DLLVM_STATIC_LINK_CXX_STDLIB=true -DLLVM_ABI_BREAKING_CHECKS="FORCE_OFF" -DLLVM_INCLUDE_TOOLS=true -DLLVM_BUILD_TOOLS=false -DLLVM_INCLUDE_UTILS=false -DLLVM_BUILD_UTILS=false -DLLVM_BUILD_RUNTIMES=false -DLLVM_BUILD_RUNTIME=false -DLLVM_BUILD_EXAMPLES=false -DLLVM_INCLUDE_EXAMPLES=false -DLLVM_BUILD_TESTS=false -DLLVM_INCLUDE_TESTS=false -DLLVM_INCLUDE_GO_TESTS=false -DLLVM_INCLUDE_BENCHMARKS=false -DLLVM_BUILD_BENCHMARKS=false -DLLVM_INCLUDE_DOCS=false -DLLVM_ENABLE_OCAMLDOC=false -DLLVM_ENABLE_TERMINFO=false -DLLVM_ENABLE_ZLIB=false -DLLVM_ENABLE_BINDINGS=false -DCMAKE_INSTALL_PREFIX=/mnt/sda1/Shared/llvm-dev/llvm-install ../llvm-project/llvm
九月二十九日 等待变化等待机会
晚舟必归
晚霞映满天, 舟行碧水间。 必是故人来, 归心难熬煎。
晚舟必归
晚霞满眼映天边, 舟行荡漾碧水间。 必有经年远客访, 归心惴惴难熬煎。
晚舟必归
晚风吹面彻骨寒, 舟车劳顿不离鞍。 必有秋风送秋客, 归雁南飞报平安。
秋夜有感
晚风微雨路灯遥, 夜幕垂肩树更高。 寒冬未至秋未尽, 枯蝉蟋蟀尽自嚎。
秋夜有感
秋枫有叶自窈窕, 夜灯无伴更孤高。 微雨无心迎面唾, 化作莹泪挂眉梢。
秋夜有感
微雨秋枫夜妖娆, 晚风拂面意兴高。 一年一度中秋夜, 秋蝉声声叹离骚。
秋夜有感
夜幕低垂繁星逃, 小雨洗净夜更高。 遥想故乡夜何似? 碧海银沙听海涛。
秋夜有感
奈何中华言凿凿, 岂料加国逃夭夭。 不计美国听渺渺, 我自敞怀谆谆教。
秋夜有感
夜深才感霜露寒, 四海漂泊难自安。 纵使梦中归故里, 近乡情怯复蹒跚。
秋夜有感
少时弄海潮, 弱冠意气高。 人生磨难少, 怎知父母好?
秋夜有感
秋风秋雨秋夜寒, 身正影正心更坚。 但使残躯归故里, 报得春晖心才安。
九月三十日 等待变化等待机会
git gcc-verify --help
'gcc-verify' is aliased to '!f() { "`git rev-parse --show-toplevel`/contrib/gcc-changelog/git_check_commit.py" $@; } ; f'
老父谆谆教诲
四海为家无妨, 告老还乡正常。 随遇而安灵活, 亲情永世莫忘。
有感老父教诲
瓢泊海外虽无妨, 衣锦还乡却非常。 大风歌罢汉高祖, 犹盼猛士守四方。
1:这个出自于《庄子:逍遥游》,我辈凡夫俗子就如同偶感
隅居若等闲, 翱翔蓬蒿间。1 借得鲲鹏翅, 扶摇上云巅。
斥鷃一般在凡人琐事间腾跃上下几仞之间以为人生之巅峰,和扶摇羊角而上九万里绝云气负青天的大鹏相比是多么可怜可笑啊。可这就是普通人的现实生活。
感觉突然之间我能写诗了,也许就像这位大妈说的然则虚度半生无所得 必有好事者挖苦揶揄, 为防人讥讽不如我自 己先改了把他们想改 的路都堵死
隅居又一年, 扑腾蓬蒿间。 空想鲲鹏翅, 梦里上云巅。
艺术上成熟了。
十月一日 等待变化等待机会
Traceback (most recent call last):
File "./contrib/mklog.py", line 39, in <module>
from unidiff import PatchSet
ModuleNotFoundError: No module named 'unidiff'
gcc/cp/ChangeLog:
* decl.c (grokparms): Conditional drop
cv-qualifier.
十月二日 等待变化等待机会
[sendemail]
smtpEncryption = tls
smtpServer = smtp.gmail.com
smtpUser = yourname@gmail.com
smtpServerPort = 587
十月三日 等待变化等待机会
十月四日 等待变化等待机会
粘过去了,这样子就无法解析lambda了。这个简单的例子里有着多少的千言万语啊。
至简形式没有概念,就是说lambda的脊梁骨是什么?参数括号()是必须有的吗?这一点我一开始没有意识到。
lambda-expression:
lambda-introducer lambda-declarator compound-statement
lambda-introducer:
[ lambda-captureopt ]
compound-statement:
{ statement-seqopt }
lambda-declarator:
lambda-specifiers
( parameter-declaration-clause ) lambda-specifiers requires-clauseopt
lambda-specifiers:
decl-specifier-seqopt noexcept-specifieropt attribute-specifier-seqopt trailing-return-typeopt
using A=decltype(+[]{});
A a=[]{};
using A=decltype(+[]()->int{return 0;});
A a=[]()->int{return 5;};
十月五日 等待变化等待机会
decltype([]{}) (*s1)[3];
decltype([]{}) (*s2)[3];
static_assert(!__is_same(decltype(s1), decltype(s2)));
typedef decltype([]{}) C;
C (*s3)[3];
C (*s4)[3];
static_assert(__is_same(decltype(s3), decltype(s4)));
An unnamed class or enumeration C defined in a typedef declaration has the first typedef-name declared by the declaration to be of type C as its typedef name for linkage purposes ([basic.link]).这个不太好理解,但是阅读原作者的论文就明白其用意是不暴露lambda在链接中导致的很多问题,比如:
A typedef declaration involving a lambda-expression does not itself define the associated closure type, and so the closure type is not given a typedef name for linkage purposes.换言之typedef等于是掩盖了lambda。那么如果没有typedef的话,lambda作为unique unnamed closure type肯定就是一个个定义的实例都是不同的了,所以,以上的行为是预料之中的。
无题
一场秋雨一场寒, 夜半披衣凭雨栏。 疫情阻隔一年半, 千家万户盼团圆。
无题
秋雨连绵五更寒, 披衣倚栏望雨穿。 浮生一万五千日, 多少往事似雨烟。
<lambda()>,它的参数是__closure
s
重温了第一行代码的各个函数<lambda()>也就是这里 它的参数有些出乎我的意料居然是this,其实是意料之中的,因为lambda本质上是一个类似functor的实体。
The reason is that we remove many restrictions on lambda expressions, yet we still want to keep closure types out of the signature of external functions, which would be a nightmare for implementations.我完全同意这就是一场噩梦! 那么和unevaluated context是什么关系呢?原来这个是从unevaluated operand的context引申来的概念:
In some contexts, unevaluated operands appear ([expr.prim.req], [expr.typeid], [expr.sizeof], [expr.unary.noexcept], [dcl.type.decltype], [temp.pre], [temp.concept]). An unevaluated operand is not evaluated.这里并没有明确指出lambda的存在,这个是什么原因呢?我想这就是论文的核心,究竟lambda可以出现在以上哪些语境context里呢?我认为作者之所以煞费苦心就是为了不再预设任何限制lambda出现的语境的限制,难道不是吗?我现在渐渐理解了lambda就可以想像是这么一个结构
struct lambda._anon_xxx{
auto operator()()const{}
};
乾坤大挪移心法修炼到第一层普通资质悟性高者需要7年,差一点的要14年。第二层又是7年和14年的周期。。。总共七层,能够练到第七层的需要上百年,世上哪有这样子的天才?
十月六日 等待变化等待机会
void _M_data(pointer);
pointer _M_data(void) const;
十月七日 等待变化等待机会
rebuild_function_method_type的诱因是pr92010揭示的Core1001/1322的老问题,但是解决的途经是不对的,因为直接导致ICE的检查说参数类型不对并不是根源,不应该在模板参数替换发现了错误才去想办法补救,正确的做法是在一开始就防止它的发生。
+ if (processing_template_decl
+ && (TREE_CODE (type) == TYPENAME_TYPE
+ || TREE_CODE (type) == DECLTYPE_TYPE
+ || TREE_CODE (type) == TEMPLATE_TYPE_PARM
+ )
+ )
+ type_quals = (CP_TYPE_CONST_P(type)?TYPE_QUAL_CONST:0) |
+ (CP_TYPE_VOLATILE_P(type)?TYPE_QUAL_VOLATILE:0);
护栏强调gcc_assert (same_type_ignoring_top_level_qualifiers_p (type, parmtype));随着c++20的
lambda with unevaluated context的出现已经不正确了,比如任何的lambda重建就是不同的类型 这里的的函数调用部分当parser根据函数原型的参数类型来创建新的类型做conversion的时候一定会发现两者的类型不同,因为这个本来也不是必要的,为什么一定要一样的呢?难道不允许类型兼容吗?这一点我不是很确定,但是我以为lambda的出现改变了很多程序员的世界观,它就是编译器实现者的噩梦。
十月八日 等待变化等待机会
/home/nick/Downloads/gcc-dev/gcc/configure CFLAGS='-ggdb3 -O0' CXXFLAGS='-ggdb3 -O0' LDFLAGS=-ggdb3 --prefix=/home/nick/Downloads/gcc-dev/install --disable-bootstrap --enable-static --disable-shared --disable-checking --enable-languages=c,c++,lto --disable-multilib --enable-gcc-debug --enable-cpp-debug --enable-werror=no --build=x86_64-unknown-linux-gnu --target=x86_64-unknown-linux-gnu --host=x86_64-unknown-linux-gnu
十月九日 等待变化等待机会
十月十日 等待变化等待机会
User-defined conversion function is invoked on the second stage of the implicit conversion, which consists of zero or one converting constructor or zero or one user-defined conversion function.这里提到second stage of implicit conversion,那么什么是first stage呢?还有就是ctor和function两个可以同时存在那么要采用哪一个呢?
If both conversion functions and converting constructors can be used to perform some user-defined conversion, the conversion functions and constructors are both considered by overload resolution in copy-initialization and reference-initialization contexts, but only the constructors are considered in direct-initialization contexts.这一段我读来如同天书,
struct To { To() = default; To(const struct From&) {} // converting constructor }; struct From { operator To() const {return To();} // conversion function };
所以,这里说的是必须使用ctor,没有歧义。而且注解里解释说如果没有定义ctor的话要使用所谓的copy ctor,但是会先调用conversion operator(function)。这里让我想起来我在哪里看到的一种说法作者认为ctor实际上是一种特殊的conversion operator,当然这个是一个个人看法,其实看起来是有道理的。From f; To t1(f); // direct-initialization: calls the constructor // (note, if converting constructor is not available, implicit copy constructor // will be selected, and conversion function will be called to prepare its argument)
To t2 = f; // copy-initialization: ambiguous // (note, if conversion function is from a non-const type, e.g. // From::operator To();, it will be selected instead of the ctor in this case) To t3 = static_cast<To>(f); // direct-initialization: calls the constructor const To& r = f; // reference-initialization: ambiguous
十月十二日 等待变化等待机会
十月十三日 等待变化等待机会
十月十四日 等待变化等待机会
秋雨有感
绵绵秋雨无心至, 飘飘落叶刻意离。 秋色无边晴方好, 昏鸦枝头向天啼。
十月十五日 等待变化等待机会
秋夜有感之一
梦醒五更心彷徨, 半生漂泊多荒唐。 往事如梦难追索, 长夜漫漫盼月光。
秋夜有感之二
梦醒四更夜正凉, 索句不得卧在床。 半生浮沉寻常事, 世纪更迭人断肠。
秋夜有感之三
秋夜五更夜更长, 被窝虽暖夜正凉。 掌上看尽天下事, 坐困蒙城作夜郎。
秋色有感之一
落英缤纷红叶生, 小径悠悠叹雨声。 枝头乌鸦啼不尽, 万籁俱寂待秋风。
秋色有感之二
风驻雨霁意踟蹰, 红叶乌鸦不独孤。 秋色无边万籁寂, 人在画中更何图?
秋色有感之三
落叶纷纷满地黄, 蒙特利尔好风光。 更盼严冬大雪日, 白雪红枫胜苏杭。
clang::Module::getFullModuleName[abi:cxx11](bool) const-0x0000000000000004另一个老问题就是之前我遇到过的undefined reference to `typeinfo for clang::ModuleLoader',这个我始终搞不明白,有人说这个是虚函数未定义的缘故,可是这个是在头文件里实现,虽然我以前是用-fno-rtti解决了但是不理解为什么会发生?
十月十六日 等待变化等待机会
秋日有雨
蒙城秋雨泼入帘, 阴云压顶到眼前。 凭栏遥望无限远, 一缕乡愁入眼帘。
十月十七日 等待变化等待机会
fakelambda应该是不属于任何人的,所以,
change的口号,大众期待的目光中却发现个人的生活并没有发生什么积极的变化就都失望了,因为一个积重难返的社会问题积累耗费很多代,同样革除也需要很多代,然而人类是没有耐心与牺牲精神的,为什么前辈人的错误要后辈来承担代价?同样的后辈人在没有同意当代人债留子孙的主张的情况下在还没有出生的情况就背负了当代人的欠债。这个就是当今的社会。
十月十八日 等待变化等待机会
十月十九日 等待变化等待机会
语法
注解
noptr-declarator ( parameter-list ) cvopt refopt exceptopt attropt (1) noptr-declarator ( parameter-list ) cvopt refopt exceptopt attropt -> trailing (2) (since C++11) noptr-declarator any valid declarator, but if it begins with *, &, or &&, it has to be surrounded by parentheses. parameter-list possibly empty, comma-separated list of the function parameters attr optional list of attributes. These attributes are applied to the type of the function, not the function itself. The attributes for the function appear after the identifier within the declarator and are combined with the attributes that appear in the beginning of the declaration, if any. 这是一个很复杂的东西,我从来没有用过,举例[[noreturn]],[[gnu::unused]], [[deprecated("because")]],关于它仅仅是修饰返回值这一点我还是比较难以理解。(since C++11) cv const/volatile qualification, only allowed in non-static member function declarations绝对不要小看这个要求! ref ref-qualification, only allowed in non-static member function declarations这个我似乎从来没有接触过!(since C++11) except either dynamic exception specification(until C++17) or noexcept specification(C++11) Note that the exception specification is not part of the function type (until C++17)那么c++20到底还承认不承认它是函数类型的一部分呢?我感觉函数签名和函数类型这两个是不同的概念!我以前当它们是同义词是不对的。 trailing Trailing return type, useful if the return type depends on argument names, such as template <class T, class U> auto add(T t, U u) -> decltype(t + u); or is complicated, such as in auto fpif(int)->int(*)(int)我想起来了这个我在stackoverflow上看过一个帖子就是这个返回值的问题的,因为到底t+u转换的类型是什么有时候还是让编译器来决定比较好,否则int+double,或者signed+unsigned之类是很头疼的,有时候不仅仅是警告的问题很可能是错误的问题。并且有些时候是模板函数太过复杂程序员有必要减轻编译器的困难直接标明返回值比较好。 requires这个不是函数声明的语法部分,但是我的理解是它是所有声明的一部分,既然函数名字是declarator那么它也是一个可能的组成部分 As mentioned in Declarations, the declarator can be followed by a requires clause, which declares the associated constraints for the function, which must be satisfied in order for the function to be selected by overload resolution. (example: void f1(int a) requires true;) Note that the associated constraint is part of function signature, but not part of function type.这就是我说的函数签名和函数类型的不同之处,到底函数重载或者说模板特例化是依赖于函数签名还是函数类型?我以为是前者,所以,早期的模板函数特例化似乎是依赖于函数类型吧?这个是我之前debug那些GCC的感觉,因为在遥远的c语言时代似乎两个概念是同样的,所以,在模板声明阶段就可以做出一个可以依赖替换模板参数的函数类型,也就是说declarator和早期的c语言的函数类型一样?这个是我的猜测,而clang等待到最后再处理模板就有这个优越之处因为现代c++的函数太复杂了! (since C++20)
typedef int(*FunType)(double);
FunType f(char);
int(* f(char))(double);
static_assert(__is_same(decltype(f), int(*(char))(double)));
1 declarator: 2 ptr-declarator 3 noptr-declarator parameters-and-qualifiers trailing-return-type 4 ptr-declarator: 5 noptr-declarator 6 ptr-operator ptr-declarator 7 noptr-declarator: 8 declarator-id attribute-specifier-seq opt 9 noptr-declarator parameters-and-qualifiers 10 noptr-declarator [ constant-expression opt ] attribute-specifier-seq opt 11 ( ptr-declarator ) 12 parameters-and-qualifiers: 13 ( parameter-declaration-clause ) cv-qualifier-seqAfterRoughly speaking, after 1->2, 2=4, 4->6, 4->6 you should have ptr-operator ptr-operator ptr-operator Then, use 4->5, 5=7, 7->8 for the first declarator; use 4->5, 5=7, 7->9 for the second and third declarators.
Functions shall not have a return type of type array or function, although they may have a return type of type pointer or reference to such things. There shall be no arrays of functions, although there can be arrays of pointers to functions.
十月二十日 等待变化等待机会
#define TTYPE_TABLE \
OP(EQ, "=") \
OP(NOT, "!") \
...
#define OP(e, s) CPP_ ## e,
...
enum cpp_ttype
{
TTYPE_TABLE
...
#undef OP
struct token_spelling
{
enum spell_type category;
const unsigned char *name;
};
#define OP(e, s) { SPELL_OPERATOR, UC s },
static const struct token_spelling token_spellings[N_TTYPES] = { TTYPE_TABLE };
#undef OP
汉芯造假级别的骗经费的故事,大概就是说要实现自主知识产权的使用汉字编写代码,注意不是c standard的UTF-8,那么当然是要使用国标编码了,我能够想像的他们的说词肯定就是源代码使用自主知识产权的汉字编码,这里不仅仅是以前我以为的使用UTF-8的变量名使用汉字的搞笑做法,而是彻底的源代码编码使用GB18030这类的,这个估计就是外国人没有合适的编辑器打开源代码文件发现一片的乱码然后就向国家科委之类的官僚说这个是什么发明创造领到一笔科研经费,这个当然是传说,可是在远古时代未必没有人这么干过,因为这个在编译的时候需要设定-finput-charset= 总之在预处理里工作量其实是非常大的,不是代码运行耗费的工作量而是写这些处理程序是很繁琐的,大概现代的程序员没有一个愿意耗费时间去造轮子做这个无用功。关于以上的说明我是找到了切实的代码佐证的,在libcpp里的charset.c里使用iconv来先转换编码然后再使用源码所谓的内定的UTF-8来做预处理的。而且有一个看上去让人害怕的所谓的ucnrange之类的部分居然来检查各种编码的合法性,我看不懂只能猜测大概是针对各种编码有哪些组合是不可能的吧?或者是c/c++各种不同标准中编码的疆界?总之,绝对没有什么人愿意触动这里的代码,实在是太繁琐了,而且毫无意义的浪费时间。编码是个力气活,而且吃力不讨好的古代人才干的力气活。
否定呢?答案似乎是不行,虽然EBNF有这样子的表达式,但是这位大侠说的好:
Context free grammars are not closed under "difference" or "complements". So while you might decide to add an operator "subtract" to your BNF, the result will not be a context free grammar even if it has a simple way to express it. Consequence: people don't allow such operators in BNF grammars used to express context-free grammars.话是这么说的,但是实际上人们怎么对付这类语法的呢?其实,一个简单的想法就是不要趟预处理的泥水集中在语法层面的处理而已。
十月二十一日 等待变化等待机会
十月二十二日 等待变化等待机会
十月二十三日 等待变化等待机会
cat /mnt/sda3/diabloforum/public_html/2021.htm|wc -m
1038922
十月二十四日 等待变化等待机会
auto call=/*+*/[](){
std::cout<<"really call"<<std::endl;
};
十月二十五日 等待变化等待机会
It is exactly equivalent to a static_cast to an rvalue reference type.,它们有一点共同相似的就是都是听上去高大上,但是实现起来却如此的简单,比如前者的最经常的应用场景就是跳过类的ctor而直接调用它的成员函数取得它的返回值,听上去多么复杂的工作却依赖于这么简单的一个add_rvalue_reference来实现的。
虚拟函数要求起码的类型匹配就是说,可是实际上这两个类型并不是十分的
匹配
秋日有雨
独立寒秋听雨声, 细若游丝飘如风。 满目萧瑟天灰朦, 无尽秋意在心中。
多此一举定义一个特例反而会导致成员函数foo没有声明了 这个特例化会
遮挡了最基本的模板定义,反而导致错误了。
十月二十六日 等待变化等待机会
tree tsubst_copy_and_build (tree t, tree args,...){
#define RECUR(NODE) tsubst_copy_and_build(NODE, ...) ...
...
return build_x_unary_op(..., RECUR(TREE_OPERAND (t, 0)),..);
...
}
十月二十七日 等待变化等待机会
LR parsers are a type of bottom-up parser that analyses deterministic context-free languages in linear time.。而与之对应的LL parser是
an LL parser (Left-to-right, leftmost derivation) is a top-down parser for a restricted context-free language. It parses the input from Left to right, performing Leftmost derivation of the sentence.比如
attribute-specifier-seq:
attribute-specifier
attribute-specifier-seq attribute-specifier
A:
'a' ###1
A'a' ###2'a'A ###应该要改成Right-Lookahead吧?
十月二十八日 等待变化等待机会
S=>AD, A=>aC, B=>bcd, C=>BE, D=>ε, E=>e (2)
b c d e
\ | / /
B E
\ /
a C ε
\ / /
A D
\ /
S
S=>AD=>aCD=>aBED=>abcdED=>abcdeD=>abcde (4)
S=>AD=>A=>aC=>aBE=>aBe=>abcde (5)
In order to avoid the unimportant difference between sequences of derivations corresponding to the same tree, we can stipulate a particular order, such as insisting that we always substitute for the leftmost inter- mediate (as done in (4)) or the rightmost one (as in (5)).
S=>aAc, A=>bAb, A=>b (6)
S=>aAc, A=>Abb, A=>b (7)
Grammar (6) is not LR(k) for any k, since given the partial string abm there is no information by which we can replace any b by A; parsing must wait until the "c" has been read.
On the other hand grammar (7) is LR(0) , in fact it is a bounded context language; the sentential forms are {aAb2nc} and {ab2n+1c}, and to parse we must reduce a substring ab to aA, a substring Abb to A, and a substring aAc to S.
This example shows that LR(k) is definitely a property of the grammar, not of the language alone.翻译成大白话就是说即便是语言本身是LR(k),如果语法写的不好也可能就不是LR(k)了。看来语法定义是相当的重要,不代表说语法树一样那么这个语法就是正确的了,因为不适当的语法有可能增加parser的设计难度。
The distinction between grammar and language is extremely important when semantics is being considered as well as syntax.grammar对应language,那么semantics对应syntax,这个是两个层次的对应。很深的概念啊。
S=>aAd, S=>bAB, A=>cA, A=>c, B=>d (8)
无界的,自然也就不是所谓的LR(k)了。
秋日有感
猎猎东风寒冬至, 秋色斜阳意迟迟。 帝国衰败成落日, 中华崛起会当时。
十月二十九日 等待变化等待机会
A grammar is L R ( k ) if and only if any handle is always uniquely determined by the string to its left and the k terminal characters to its right.
bounded right context但却是LR(0)
S=>aA, S=>bB, A=>cA, A=>d, B=>cB, B=>d (9)
S=>aAc, S=>b, A=>aSc, A=>b (10)
闲居细品人生
注定是尺莫求丈, 三分人事七分旁。 粗茶淡饭有真味, 乐天知命岁月长。和老爸闲居品人生
蛰居蒙城日月长, 尺寸之间成圆方。 春花秋月冬日雪, 盛夏美景赛苏杭。
S=>BC, B=>Ce, B=>ε, C=>D, C=>Dc, D=>ε, D=>d
| S | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BC S=>BC | |||||||||||||||||||||||
| BD C=>D | BDc C=>Dc | ||||||||||||||||||||||
| B D=>ε | Bd D=>d | Bc D=>ε | Bdc D=>d | ||||||||||||||||||||
| Ce B=>Ce | ε B=>ε | Ced B=>Ce | d B=>ε | Cec B=>Ce | c B=>ε | Cedc B=>Ce | dc B=>ε | ||||||||||||||||
| De C=>D | Dce C=>Dc | Ded C=>D | Dced C=>Dc | Dec C=>D | Dcec C=>Dc | Dedc C=>D | Dcedc C=>Dc | ||||||||||||||||
| e D=>ε | de D=>d | ce D=>ε | dce D=>d | ed D=>ε | ded D=>d | ced D=>ε | dced D=>d | ec D=>ε | dec D=>d | cec D=>ε | dcec D=>d | edc D=>ε | dedc D=>d | cedc D=>ε | dcedc D=>d | ||||||||
| εεε | cεε | ceε | cec | ced | dεε | dcε | dce | deε | dec | ded | eεε | ecε | edε | edc |
十月三十日 等待变化等待机会
fully parenthesizing algebraic expressions involving the letter a and the binary operation + :,
S=>a, S=>(S+S) (25)
Given any such string we will perform the following acts of sabotage:然后假如我们有一个字符串是((a+a)+a),那么大师定义如下:
- All plus signs will be erased.
- All parentheses appearing at the extreme left or extreme right will be erased.
- Both left and right parentheses,will be replaced by the letter b.
Here B, L, R, N denote the sets of strings formed from (25) with alterations (i) and (iii) performed, and with parentheses removed from both ends, the left end, the right end, or neither end, respectively.这个是我的理解:
B=>aaa, L=>aaba, R=>aaa, N=>aaba
B=>LR, L=>LNb, R=>bNR, N=>bNNb
老爸诗云
他乡久了成故乡, 情随事迁都一样, 哪有地方不养人, 五湖四海任你闯。我的附和
男儿有志走四方, 客居加国成故乡。 但凡草木服水土, 哪有花开不芬芳?
十月三十一日 等待变化等待机会
十一月一日 等待变化等待机会
冲突(conflict),实际的解决方法是要维持效率做一个取舍,但是有可能会遗漏一些正确的选择,所以,有这个类似于深度/广度搜索的算法,也许能够解决语法是LR(2)直至LR(k)的问题。但是这里我看的有些糊涂就是说这样子产生的编译器实际上是内嵌了这个搜索算法而在实际的解析中按照预设的搜索算法
分进合击,当然预设的一些搜索是
殊途同归的话是直接就合并了。那么这里是要和语义分析(semantics)结合才能做到吗?还是纯粹的语法解析?也许都有吧?难道不是吗?反证要等到一个action消失就自动放弃,产生语法错误的一个来源就是action返回错误啊。另一个点点的收获就是看到同样这一句语法在两个不同的项目中做了不同的处理,在一个更加贴近实际的项目里被大幅度的改造了,因为要适应所谓的递归搜索,而在那个没有任何改造的项目里bison爆出了很多的conflict,所以,我的感觉是简单的BNF语法需要很细致的改造才能避免这些conflict,也就是说人类手写的很多语法看起来不一定就是正确的LR(1)语法。这个只是我的揣测,难道c++委员会写的c++bnf并非是LR(1)的语法?这个让人难以置信,应该是我理解有错,不过标准已经声明这个BNF语法就是一个说明性质的,要怎么证明一个语法是LR(1)呢?是否使用bison没有conflict就说名了吗?作为c++语法并没有指望编译器一定要做到LR(1)啊?这个是两回事,也许语言是LR(1)但是语法不一定,因为要找到正确的LR(1)的BNF语法也是一个很不简单的工作,至少这个是我读Knuth的论文的唯一的微薄的一点收获,只看懂了前面五六页就看不下去了。
霸王贴,这个是我起的外号因为它们大概可以永远霸占这些经典的问题,它们的作用很多时候甚至超过了wiki,因为后者是一个全面的介绍但是很多时候提问者的问题是其中很针对性的具体问题,所以,这个是回答怎么判断一个语法是否是LL(k)或者LR(k)的方法!但是看懂这个回答真的不容易,反正对我来说很不容易,首先我完全忘记了所谓的FIRST/FOLLOW SETS,这个也许在自动机课堂上教授做过,可是我完全忘记了。对于一个non-terminal的FIRST和它的FOLLOW的terminal的集合如果发现有和其他的non-terminal有重合那么就是有FIRST/FIRST或者FOLLOW/FOLLOW,或者和它自己的FIRST/FOLLOW冲突,让我摘抄加深记忆:
这些定义非常的晦涩难懂,如果没有例子讲解简直就是天书一样的难懂。看这些评论才能明白FIRST/FIRST-CONFILICTS需要的是同一个symble的不同productions而不是发生在两个symbols。这个是一个很重要的误区吧?
- FIRST/FIRST conflicts, where two different productions would have to be predicted for a nonterminal/terminal pair.
- FIRST/FOLLOW conflicts, where two different productions are predicted, one representing that some production should be taken and expands out to a nonzero number of symbols, and one representing that a production should be used indicating that some nonterminal should be ultimately expanded out to the empty string.
- FOLLOW/FOLLOW conflicts, where two productions indicating that a nonterminal should ultimately be expanded to the empty string conflict with one another.
A FIRST/FIRST conflict occurs when two productions for the same nonterminal have overlapping FIRST sets. Even though X and Y contain b in their FIRST sets, there is no nonterminal in the grammar with two productions, one of which starts with X and one of which starts with Y.
Some simple checks to see whether a grammar is LL(1) or not. Check 1: The Grammar should not be left Recursive. Example: E --> E+T. is not LL(1) because it is Left recursive. Check 2: The Grammar should be Left Factored.
Left factoring is required when two or more grammar rule choices share a common prefix string. Example: S-->A+int|A.
Check 3:The Grammar should not be ambiguous.
In LL(1)
- First L stands for scanning input from Left to Right. Second L stands for Left Most Derivation. 1 stands for using one input symbol at each step.
For Checking grammar is LL(1) you can draw predictive parsing table. And if you find any multiple entries in table then you can say grammar is not LL(1).问题是怎么画?
十一月二日 等待变化等待机会
var="$(echo -n '↳' | od -An -tx1)"; printf '\\x%s' ${var^^}; echo
echo -n '↳' | od -An -tx1 | sed 's/ /\\x/g'
echo $'\xe2\x86\xb3'
↳
GCC/Clang are not strict recursive descent parsers; they allow backtracking (reparsing an arbitrarily-long text), among other deviations from theoretical purity. Backtracking parsers are strictly more powerful than non-backtracking parsers (but at the cost of no longer being linear time).而最有价值的是这三点原因:
这里要补充定义Recursive Descent Parser:
the preprocessor, which is not particularly complicated but cannot be described by anything remotely resembling是的,这个实在是浪费时间的工作,没有人愿意花时间在这上面,而且搜索路径取舍的决策都是人为主观的决定。 a formal parsing framework;
template instantiation, which intermingles semantic analysis into the parsing process是的,我感觉c++的模板完全就是另一个语言需要另外的一个编译器,这个也是我从一开始探索编译器的直接原因,也许在语法稳定以后大家集中精力开发一个超级强大的模板库是未来的编程方向,而不是不断的扩张语法编译器的功能。你看boost在没有编译器支持的情况下实现了大部分c++的新feature,随后编译器添加的支持只不过是为了减少损耗的跟进而已。 (and needs to be done in order to discover the correct parse);
name resolution, which some might not consider to be part of parsing, but you're not going to move on to the next step until这个不是单纯的syntax的正确与否而是类似于bison里的action返回结果干预编译器解析的过程 you know which syntactic object a particular identifier refers to. (If you think name resolution is simple, reread the 13 dense pages of the C++ standard in section 6.5 (Name lookup)要去看看!, and then move on to the 35 pages on resolving overloaded names, section 12要去看看!!.)
In computer science, a recursive descent parser is a kind of top-down parser built from a set of mutually recursive procedures (or a non-recursive equivalent) where each such procedure implements one of the nonterminals of the grammar. Thus the structure of the resulting program closely mirrors that of the grammar it recognizes.[1]所以,这里就很明白了,如果GCC/clang是所谓的LR/LL之类的实现那么根本就不用人去开发直接使用yacc/bison生成就好了,关键是有很多的原因这样做不行。我的理解是把语法解析转换为状态机来补缺补漏对于人来说太困难了,所以不如直接用函数来实现,当然这里就有很多不严格的状态被遗漏,这个是优点因为是捷径,也是缺点因为有可能出错。这个朴素的道理是三岁小孩子都明白的,我难道是今天才想到吗?当初上编译器课的作业就能够体会的,真是多馀。
If some nonterminal symbol S is used in several places in the grammar, SLR treats those places in the same single way rather than handling them individually.也就是说SLR是在没有产生所有的状态机之前就计算
lookahead set?

昨晚想去看电影结果电影院不开门还淋了一场雨得小诗一首
昨夜北风吹, 梦见百花摧。 平明探究竟, 红叶漫天飞。
A grammar that has no shift/reduce or reduce/reduce conflicts when using follow sets is called an SLR grammar.定义。
The lookahead sets calculated by LALR generators are a subset of (and hence better than) the approximate sets calculated by SLR generators.
Bottom-up parsing patiently waits until it has scanned and parsed all parts of some construct before committing to what the combined construct is.难道Top-down就不是这样子吗?
The opposite of this is top-down parsing, in which the input's overall structure is decided (or guessed at) first, before dealing with mid-level parts, leaving completion of all lowest-level details to last.的确如此。Top-down一开始就靠猜的吗?
If a language grammar has multiple rules that may start with the same leftmost symbols but have different endings, then that grammar can be efficiently handled by a deterministic bottom-up parse but cannot be handled top-down without guesswork and backtracking.
All conflicts that arise in applying a LALR(1) parser to an unambiguous LR(1) grammar are reduce/reduce conflicts.怎么理解呢?这里暴露了我根本没有明白基本概念!
LALR(1) = LA(1)LR(0) (1 token of lookahead, LR(0))原来这里LALR(1)的1指的是lookahead的1,而它的原型机还是LR(0)! 那么LR(0)是什么意思呢?这里的定义
To avoid backtracking or guessing, the LR parser is allowed to peek ahead at k lookahead input symbols before deciding how to parse earlier symbols.所以,我觉得我的混乱就来自于这里,我一直认为LR(1)的1指的是每次只读一个symbol/token,但是这里其实关于lookahead的概念我还是没有建立,还是模模糊糊。难道LR(0)指的是压根不读取任何token吗?显然不是应该是不用lookahead就能做reduce/shift的决策?那么这样要求语法是不是太严格了呢?
Algorithm to construct LL(1) Parsing Table:所以,核心是这么几条:
- Step 1: First check for left recursion in the grammar, if there is left recursion in the grammar remove that and go to step 2.
- Step 2: Calculate First() and Follow() for all non-terminals.
- First(): If there is a variable, and from that variable, if we try to
drivederive??? all the strings then the beginning Terminal Symbol is called the First.- Follow(): What is the Terminal Symbol which follows a variable in the process of derivation.
- Step 3: For each production A –> α. (A tends to alpha)
- Find First(α) and for each terminal in First(α), make entry A –> α in the table.
- If First(α) contains ε (epsilon) as terminal than, find the Follow(A) and for each terminal in Follow(A), make entry A –> α in the table.
- If the First(α) contains ε and Follow(A) contains $ as terminal, then make entry A –> α in the table for the $.
To construct the parsing table, we have two functions:
十一月三日 等待变化等待机会
A recursive descent parser is a kind of top-down parser built from a set of mutually recursive procedures (or a non-recursive equivalent) where each such procedure implements one of the nonterminals of the grammar. Thus the structure of the resulting program closely mirrors that of the grammar it recognizes.其实,我本来不需要定义就能明白的,但是猛一读这个定义就糊涂了,一会儿说
mutually-recursive,一会儿说non-recursive我就糊涂了。然后才明白这个还是英语理解的问题,你当然是后者更好,可是不一定做不到啊。并不是要追求这样子,现在才明白说GCC/clang都是recursive descent parser其实就是我们人类普通编程的习惯,说的高大上我就不懂了,原来就是一个小马甲而已的标签。
S=>ABC
A=>B
B=>a
C=>Aa
- If x is a terminal, then FIRST(x) = { ‘x’ }
- If x-> Є, is a production rule, then add Є to FIRST(x).
- If X->Y1 Y2 Y3….Yn is a production,
- FIRST(X) = FIRST(Y1)
- If FIRST(Y1) contains Є then FIRST(X) = { FIRST(Y1) – Є } U { FIRST(Y2) }
- If FIRST (Yi) contains Є for all i = 1 to n, then add Є to FIRST(X).
- FOLLOW(S) = { $ } // where S is the starting Non-Terminal
- If A -> pBq is a production, where p, B and q are any grammar symbols, then everything in FIRST(q) except Є is in FOLLOW(B).
- If A->pB is a production, then everything in FOLLOW(A) is in FOLLOW(B).
- If A->pBq is a production and FIRST(q) contains Є, then FOLLOW(B) contains { FIRST(q) – Є } U FOLLOW(A)
 这个定义是显而易见的,关键是后面这句话:
这个定义是显而易见的,关键是后面这句话:
A general shift reduce parsing is LR parsing. The L stands for scanning the input from left to right and R stands for constructing a rightmost derivation in reverse.这个是这两天天天念叨的,耳朵都磨出茧子了。可是还是忘了!这里有趣的是揭示了基本的算法:LLparser依赖的是First/Follow,而LRparser依赖这两个函数:Closure(), Goto(),这里我得到的提示是LR本质上似乎是一种DFA的搜索算法,但是令人迷惑的是LR的R是从最右边,我以为这个是因为Knuth论文说了创建表之后具体解析是从最右边,但是创建表是依照了从左到右的状态机按照DFA的原则来搜索,而这个搜索的路径的逆序正好是将来解析实际子串的顺序。Knuth的观察是相当的深刻的,大师对于计算机的栈的原理是有着深邃的认识。我感觉创建LR表的过程似乎就是LL的算法,总之我的脑子很混乱,解析语法和最终解析实际字符串的过程是时空的交叉了。脑子凌乱了。
- Many programming languages using some variations of an LR parser. It should be noted that C++ and Perl are exceptions to it.到底这么一个简单的问题我头脑始终不清楚,我已经老早就知道GCC/clang是Recursive Descent Parser,那不是明白说是TopDownParser吗?否则早就用bison/YACC来做了,这个不是我昨天就明白的吗?
- LR Parser can be implemented very efficiently.这个是当然的,因为使用状态机当然是最快的。
- Of all the Parsers that scan their symbols from left to right, LR Parsers detect syntactic errors, as soon as possible.最先我对于这个还是疑惑,明明要把所有的最右边的解析才行怎么比LL快呢?除非说的是worstcase,因为要是比bestcase,那么LL肯定是有更快的,因为它看到第一个就可以判断,当然啊,这个情况是否LR也能判断呢?
十一月四日 等待变化等待机会
A grammar is left-recursive if and only if there exists a nonterminal symbol A that can derive to a sentential form with itself as the leftmost symbol. Symbolically,这个和我的想法是一样的,就是说left-recursion就是有一个固定的prefix的terminal来触发递归,当然right-recursion就是一个固定的suffix了,这里的prefix/suffix都是ε就是所谓的direct-left/right-recursion。所以,回过头来说LL(1)是以没有递归的代价达到没有回滚的。这种语法相当的有限吧?因为按照没有递归语言就是有限的说法这个简直就不可能是计算机语言,这个结论似乎连我自己都不信,肯定是错的?where⇒+ indicates the operation of making one or more substitutions, and α is any sequence of terminal and nonterminal symbols.A⇒+Aα,
void f(double my_dbl) {
int i(int(my_dbl));
}
vexing parsing的警告,你可能后来遇到编译错误的时候完全一头雾水。当然这里也是很简单的就是我以前说的要遵循现代c++初始化的规矩使用大括号{},比如:std::thread t(SayHello{});这样子就不会有歧义了。 我看到wiki的类似的解决方法很让我吃了一惊,居然有这么多的组合:
//Any of the following work:
TimeKeeper time_keeper(Timer{});
TimeKeeper time_keeper{Timer()};
TimeKeeper time_keeper{Timer{}};
TimeKeeper time_keeper( {});
TimeKeeper time_keeper{ {}};
LL grammars, particularly LL(1) grammars, are of great practical interest, as parsers for these grammars are easy to construct, and many computer languages are designed to be LL(1) for this reason.这个是真的吗?
Most computer languages are "technically" not LL because they are not even context-free. That would include languages which require identifiers to be declared (C, C++, C#, Java, etc.), as well as languages with preprocessors and/or macro facilities (C and C++, among others), languages with ambiguities which can only be resolved using semantic information (Perl would be the worst offender here, but C and C++ are also right up there).这么多的编程语言连context-free都不算,当然这个是因为有预处理和宏替换。
骨干的语言算不算呢?其他不说,单单c++的模板是绝对不可能的,因为它是一定需要语义分析才能完成解析的。这里提到的这个
Van Wijngaarden grammar语法有些难理解,我只能模模糊糊的理解就是语法树的节点有属性?
In any case, a common parsing strategy is to recognize a superset of a language, and then reject non-conforming programs through a subsequent analysis of the resulting parse tree; in that case, the question becomes whether or not the superset is LL.
The goal of parsing is to produce a syntax tree, not solely to recognize whether a text is valid or not.这个也不矛盾吧?创建的过程就是一个验证的过程,验证仅仅是最最基本的要求,当然对于编译器来说不是目的,但是对于某些工具,比如我向往的语言验证器就是目的,能不能不用语义分析就验证语法的正确性呢?这个显然是包含很多以上的歧义问题,但是最起码它达到了大部分的编程的目的,起码语法是可行的?这个可能吗?
So it seems to be reasonable to insist that a proposed grammar actually represent the syntactic structure of the language.能做到吗?
可以容忍的
超级语言,但是我的感觉是如果允许创建不同的语法树这个就整个改变了初衷了,因为之前说过LL或者是LR的结果是不同的树的话就暴露了语言的歧义,那么你得到这样的宽泛的结果有很么意义呢?所以这个superset of languange是缺少实际意义的。简单说就是如果你以为一个人说的英语听不懂是因为时态等等的小的语法错误,可是实际上他说的让人怀疑他是在说法语还是西班牙语,那么这个宽泛的结果就无实际讨论的意义了。
This point is important because an LL grammar cannot handle left-recursive productions, and you need a left-recursive production in order to correctly parse a left-associative operator.操作符优先级真的很重要吗?不过至少是导致了语法树的不确定性,让原本没有歧义的语言语法出现了歧义,所以,兹事体大。结论就是不能够依赖于LL来解决这个问题。所以,变成语言就不可能是LL(1)语法相符的?对吗?作者甚至提到一些强大的语言如Haskel, Prolog还可以自定义操作符优先级,那么这个不依赖于语义分析就根本不可能解决了。
In order to avoid cheating, though, we should really require that the LL parser have fixed lookahead and not require backtracking. If you allow arbitrary lookahead and backtracking, then you considerably expand the domain of parseable languages, but I contend that you are no longer in the realm of LL.所以,核心的问题就是你如果真的限制了lookahead的长度而且不允许回朔,
这个作者口气太不客气了,一杆子打死一船人。然而话糙理不糙,还是有道理的。作者的言辞是犀利的:Now, (ignorant) people (usually not language theorists, but parser designers) typically use "not context-free" in some of the following meanings
- ambiguous
- can't be parsed with Bison
- not LL(k), LR(k), LALR(k) or whatever parser-defined language class they chose
的确我就没有想过这个问题啊,语法是没有任何反映出是context-sensitive的特征,当然牢牢记住标准自己都说了语法是说明性的当不得真的,没有人能够照着语法把编译器做出来,因为你还需要标准里大段大段的规定来解疑释惑去除歧义。First, you rightly observed there are no context sensitive rules in the grammar at the end of the C++ standard, so that grammar is context-free.
十一月五日 等待变化等待机会
%token e b a
%start S
%%
S:
e B b A
| e A
;
A:
a
| %empty
;
B:
a
| a D
;
D:
b
;
%%
First example: a • b b A
Shift derivation
S
↳ B b A
↳ a D
↳ • b
Second example: a • b
Reduce derivation
S
↳ B b A
↳ a • ↳ ε
First example: a • b b A
Shift derivation
S
↳ B b A
↳ a D
↳ • b
S → e a D b A
S → e a b A
S → e A
A → a
A → ε
D → b
S → e a D b A
S → e A
A → a
A → ε
D → b
D → ε
1 S: e a D A
2 | e A
3 A: a
4 | %empty
5 D: b b
6 | b
十一月六日 等待变化等待机会
Any kind of sequence can be defined using either left recursion or right recursion, but you should always use left recursion, because it can parse a sequence of any number of elements with bounded stack space. Right recursion uses up space on the Bison stack in proportion to the number of elements in the sequence, because all the elements must be shifted onto the stack before the rule can be applied even once.不过这个仅仅是bison的偏好,不代表你的语法必须是这样子吗?不过。。。c++语法的bnf是说明性的并没有打算作为bison/yacc的输入文件。
stmt:
expr
| if_stmt
;
if_stmt:
"if" expr "then" stmt
| "if" expr "then" stmt "else" stmt
;
expr:
"identifier"
;
./configure --disable-option-checking '--prefix=/usr/local' '--build=x86_64-pc-linux-gnu' '--host=x86_64-pc-linux-gnu' '--target=x86_64-pc-linux-gnu' '--disable-java' '--disable-pascal' 'build_alias=x86_64-pc-linux-gnu' 'host_alias=x86_64-pc-linux-gnu' 'target_alias=x86_64-pc-linux-gnu' --cache-file=/dev/null --srcdir=.
Example: "if" expr "then" "if" expr "then" stmt • "else" stmt
Shift derivation
if_stmt
↳ "if" expr "then" stmt
↳ if_stmt
↳ "if" expr "then" stmt • "else" stmt
Example: "if" expr "then" "if" expr "then" stmt • "else" stmt
Reduce derivation
if_stmt
↳ "if" expr "then" stmt "else" stmt
↳ if_stmt
↳ "if" expr "then" stmt •
有感台海局势
塞北深秋枫叶红, 海峡遥望景不同。 台岛井蛙不知海, 曲士冰雪辨夏虫。
《庄子集释》卷六下《外篇·秋水》北海若曰:井蛙不可以语于海者,拘于虚也;夏虫不可以语于冰者,笃于时也;曲士不可以语于道者,束于教也。
意思是:你不要跟夏天的虫子谈冰,它不懂;不要跟井底之蛙谈大海,它没见过不懂;不要跟凡夫谈高深的道的学问,他不懂。
十一月七日 等待变化等待机会
Rules of the form A → ε have only a single item A → •.
十一月八日 等待变化等待机会
A canonical LR parser or LR(1) parser is an LR(k) parser for k=1, i.e. with a single lookahead terminal. The special attribute of this parser is that any LR(k) grammar with k>1 can be transformed into an LR(1) grammar. LR(k) can handle all deterministic context-free languages.首先不知道这个断言的出处与正确性,权且相信,但是要明确的不是parser本身可以做到,也就是说不要以为你号称是一个LR(1)的parser就能打遍天下无敌手,不,是任何LR(k)的语法可以转换为LR(1)的语法!所以,这个工作是很不容易的,需要你去处理bison的种种的冲突!此外,我还没有看到什么是back-substitution是怎么样子的,也许就是一个修改语法的过程吧?而所谓的所有的Deterministic Context-Free Language(DCFL)是一个所有CFL的子集,换言之就是存在一个对应的Deterministic Push-Down Automaton(DPDA)如果能够对于任何一个状态和任何一种输入和任何一个栈里的字符串的组合有唯一性且确定拥有。这个对应的定义很铉酷可以拿来忽悠人,虽然我看不懂:
A (not necessarily deterministic) PDA M can be defined as a 7-tuple:我看不懂公式,但是我抄写一遍花的时间比理解还要多。两个判断标准的最后一个判断我无法理解。M = (Q, Σ, Γ, q0, Z0, A, δ);
where
- Q is a finite set of states
- Σ is a finite set of input symbols
- Γ is a finite set of stack symbols
- q0 ∈ Q is the start state
- Z0 ∈ Γ is the starting stack symbol
- A ⊆ Q, where A is the set of accepting states
- δ is a transition function, where
δ: (Q x (Σ ∪ {ε}) x Γ) --> P(Q x Γ*)
where * is the Kleene star, meaning that * is "the set of all finite strings (including the empty string ε) of elements of Γ", ε denotes the empty string, and P ( X ) is the power set of a set X.
M is deterministic if it satisfies both the following conditions:
- For any q ∈ Q, a ∈ Σ ∪ {ε}, x ∈ Γ, the set δ(q, a, x) has at most one element;
- For any q ∈ Q, x ∈ Γ, if δ(q, ε, x) ≠ ∅ then δ(q, a, x) = ∅ for every a ∈ Σ;
超级状态机或者说是一个描述状态机的状态机?因为wiki批注说那个描述无法理解确实是有道理的,因为作者没有解释的很清楚。结合刚才抄写PDPA的定义就可以看出来,因为输入symbol本身也是状态机组成元素之一,如果状态机本身的元素
For any q ∈ Q, a ∈ Σ ∪ {ε}, x ∈ Γ, the set δ(q, a, x) has at most one element;做不到的话,我们就加大栈里的字符长度a,所以,不过这里我想不清楚到底是输入还是栈里的长度?总而言之和这个有关系。
秋去冬来有诗为证
云涨云消云卷云舒望不停, 风吹落叶满地金。 秋去冬来日渐短, 吟风对颂月慰我心。
 我一时好奇google要如何把这首小诗翻译成英文呢?比我想像的好太多了,相当的不错!
我一时好奇google要如何把这首小诗翻译成英文呢?比我想像的好太多了,相当的不错!
The cloud rises and the cloud disappears,
The wind blows the fallen leaves all over the ground.
Fall to winter is getting shorter,
Yin Feng comforted my heart to the moon.
[T → • T + n]半梦半醒之间偶得
金风飒爽满人间, 一片红叶挂天边。 红似晚霞艳如火, 恰似仙子舞翩跹。
午饭后去公园偶得
白云蓝天映眼帘, 落叶满地近身前。 暖阳熏得人欲睡, 坐看风起似等闲。
十一月九日 等待变化等待机会
(1) E → 1 E
(2) E → 1
(0) S → E eof
S → • E eof
+ E → • 1 E
+ E → • 1
E → 1 • E
E → 1 •
+ E → • 1 E
+ E → • 1
S → E • eof
E → 1 • E
E → 1 •
+ E → • 1 E
+ E → • 1
E → 1 E •
| Item Set | detail | '1' | E |
|---|---|---|---|
| 0 |
|
1 | 2 |
| 1 |
|
1 | 3 |
| 2 |
|
||
| 3 |
|
| Item Set | detail | E |
|---|---|---|
| 0 |
|
2 |
| 1 |
|
3 |
| 2 |
|
|
| 3 |
|
| Item Set | detail | '1' |
|---|---|---|
| 0 |
|
s1 |
| 1 |
|
s1 conflict with r2 |
| 2 |
|
r0 |
| 3 |
|
r1 |
(1) E → A 1
(2) E → B 2
(3) A → 1
(4) B → 1
(0) S → E eof
| Item Set | detail | '1' | '2' | E | A | B |
|---|---|---|---|---|---|---|
| 0 |
|
s1 | 2 | 3 | 4 | |
| 1 |
|
r3 conflicts with r4 | r3 conflicts with r4 | |||
| 2 |
|
acc | acc | |||
| 3 |
|
s5 | ||||
| 4 |
|
s6 | ||||
| 5 |
|
r1 | r1 | |||
| 6 |
|
r2 | r2 |
E → 1 • E
E → 1 • satisfy r2
+ E → • 1 E
+ E → • 1
A → 1 • satisfy r3
B → 1 • satisfy r4
预先做了剪枝处理,也就是在每一个搜索的节点不是brute-force的尝试每一个选项,而是根据每一个non-terminal在每一个item set里的每一个rule的可能的Follow set。
十一月十日 等待变化等待机会
只有读了这些才能真正体会到为什么Knuth当初提出的这个算法的流行,因为它正好是栈的逆序,所以,我们不停的压栈而每次都是在栈顶来判断是否有reduce的可能,这个就是rightmost derivation的顺序!从这也可以体会为什么是Push-Down-Automaton,因为它使用的是栈。
- Reduce:
- If we can find a rule A –> w , and if the contents of the stack are qw for some q ( q may be empty), then we can reduce the stack to qA . We are applying the production for the nonterminal A backwards.
- Handle:
- The w being reduced is referred to as a handle. Formally, a handle of a right sentential form u is a production A –> w , and a position within u where the string w may be found and replaced by A to produce the previous right sentential form in a rightmost derivation of u . Recognizing valid handles is the difficult part of shift-reduce parsing.
- Recognize:
- There is also one special case: reducing the entire contents of the stack to the start symbol with no remaining input means we have recognized the input as a valid sentence. This is the last step in a successful parse.
- Shift:
- If it is impossible to perform a reduction and there are tokens remaining in the undigested input, then we transfer a token from the input onto the stack. This is called a shift.
- Error:
- If neither of the two above cases apply, we have an error. If the sequence on the stack does not match the righthand side of any production, we cannot reduce. And if shifting the next input token would create a sequence on the stack that cannot eventually be reduced to the start symbol, a shift action would be futile. Thus, we have hit a dead end where the next token conclusively determines the input cannot form a valid sentence.
LR Parsing
LR parsers ("L" for left to right scan of input, "R" for rightmost derivation) are efficient, table-driven shift-reduce parsers. The class of grammars that can be parsed using LR methods is a proper superset of the class of grammars that can be parsed with predictive LL parsers. In fact, virtually all programming language constructs for which CFGs can be written can be parsed with LR techniques. As an added advantage, there is no need for lots of grammar rearrangement to make it acceptable for LR parsing the way that LL parsing requires.
We begin by tracing how an LR parser works. Determining the handle to reduce in a sentential form depends on the sequence of tokens on the stack, not only the topmost ones that are to be reduced, but the context at which we are in the parse. Rather than reading and shifting tokens onto a stack, an LR parser pushes "states" onto the stack; these states describe what is on the stack so far. Think of each state as encoding the current left context. The state on top of the stack possibly augmented by peeking at a lookahead token enables us to figure out whether we have a handle to reduce, or whether we need to shift a new state on top of the stack for the next input token.
An LR parser uses two tables:这里也终于解释了为什么我们需要Goto table,之前我认为没有什么用,现在才明白Action table,告诉你怎么去做shift/reduce,但是并不能告诉你然后的状态是什么。这一点如果不实际写程序是体会不到的,因为在很多算法描述中没有提到具体的栈的状态。甚至于没有提到具体的handle是怎样的。不过我对于两个表合在一起还是有些不解,当然从制作表的过程看似乎是这样子的。前者的列就是terminal,后者的列是non-terminal,可是。。。The two tables are usually combined, with the action table specifying entries for terminals, and the goto table specifying entries for nonterminals.
- The action table Action[s,a] tells the parser what to do when the state on top of the stack is s and terminal a is the next input token. The possible actions are to shift a state onto the stack, to reduce the handle on top of the stack, to accept the input, or to report an error.
- The goto table Goto[s,X] indicates the new state to place on top of the stack after a reduction of the nonterminal X while state s is on top of the stack.
LR Parser Tracing
We start with the initial state s0 on the stack. The next input token is the terminal a and the current state is st . The action of the parser is as follows:
- If Action[st ,a] is shift, we push the specified state onto the stack. We then call yylex() to get the next token a from the input.
- If Action[st ,a] is reduce Y –> X1 ...Xk then we pop k states off the stack (one for each symbol in the right side of the production) leaving state su on top. Goto[su ,Y] gives a new state sV to push on the stack. The input token is still a (i.e., the input remains unchanged).
- If Action[st ,a] is accept then the parse is successful and we are done.
- If Action[st ,a] is error (the table location is blank) then we have a syntax error. With the current top of stack and next input we can never arrive at a sentential form with a handle to reduce.
正因为LR(0)根本没有lookahead,我根本不知道这个lookahead是存在哪个数据结构里的,难道是item set里要包含这个token?换言之,LR(0)和LR(1)的item set根本就是不兼容的,差别很大的!所以,不仅仅是表的大小,当然表的大小的直接原因是item set数量来决定的。是的,教授说表立刻增大很多很多。LR Parser Types
There are three main types of LR parsers: LR(k), simple LR(k), and lookahead LR(k) (abbreviated to LR(k), SLR(k), LALR(k)). The k identifies the number of tokens of lookahead. We will usually only concern ourselves with 0 or 1 tokens of lookahead, but the techniques do generalize to k > 1. The different classes of parsers all operate the same way (as shown above, being driven by their action and goto tables), but they differ in how their action and goto tables are constructed, and the size of those tables.
The full LR(1) parsing table for a typical programming language has many thousands of states compared to the few hundred needed for LR(0).是一个或者几个?数量级的增加!
LALR(1) is the method used by the bison parser generator.这个信息是很重要的!
The essence of LR parsing is identifying a handle on the top of the stack that can be reduced. Recognizing a handle is actually easier than predicting a production was in topdown parsing. The weakness of LL(k) parsing techniques is that they must be able to predict which product to use, having seen only k symbols of the righthand side. For LL(1), this means just one symbol has to tell all. In contrast, for an LR(k) grammar is able to postpone the decision until it has seen tokens corresponding to the entire right hand side (plus k more tokens of lookahead). This doesn’t mean the task is trivial. More than one production may have the same righthand side and what looks like a right hand side may not really be because of its context. But in general, the fact that we see the entire right side before we have to commit to a production is a useful advantage.字字珠玑啊!
十一月十一日 等待变化等待机会
那么这就是所谓的configurating set的概念,而计算它的过程就是closure,说到底,它就是代表了所谓的上下文,而令人感兴趣的是这种语言的本来定义是context-free,也就是说At the above point in parsing, we have just recognized an X and expect the upcoming input to contain a sequence derivable from YZ . Examining the expansions for Y , we furthermore expect the sequence to be derivable from either u or w . We can put these three items into a set and call it a configurating set of the LR parser. The action of adding equivalent configurations to create a configurating set is called closure. Our parsing tables will have one state corresponding to each configurating set.A –> X•YZ Y –> •u Y –> •w
上下文无关的语言里是有上下文相关的解析参数的。所谓的状态就是上下文相关的解析条件的映射。这个是理解item set或者说状态机的状态的关键,当然这里还没有lookahead的角色,但是它只不过是这个的延伸,成为状态的一部分。
Each state must contain all the items corresponding to each of the possible paths that are concurrently being explored at that point in the parse.
Each time we perform a shift we are following a transition to a new state.而这里状态是记录在哪里的呢?是记录在栈顶的! 大师的描述是这么的翔实精确我没法不引用
Recall that we push states onto the stack in a LR parser. These states describe what is on the stack so far. The state on top of the stack (potentially combined with some lookahead) enables us to figure out whether we have a handle to reduce, or whether we need to read the next input token and shift a new state on top of the stack. We shift until we reach a state where the dot is at the end of a production, at which point we reduce. This finite automaton is the basis for a LR parser: each time we perform a shift we are following a transition to a new state.
In summary, to create a configurating set for the starting configuration A –> •u , we follow the closure operation:
- A –> •u is in the configurating set
- If u begins with a terminal, we are done with this production
- If u begins with a nonterminal B , add all productions with B on the left side, with the dot at the start of the right side: B –> •v
- Repeat steps 2 and 3 for any productions added in step 3. Continue until you reach a fixed point.
At the highest level, we want to start with a configuration with a dot before the start symbol and move to a configuration with a dot after the start symbol. This represents shifting and reducing an entire sentence of the grammar. To do this, we need the start symbol to appear on the right side of a production.就是因为我们需要把start symbol完全shift/reduce来达到接受状态,所以,必须把它放在语法rule的右边让光标移动到结尾才能做到,于是就有了额外的0规则。
| Configurating Set | Successor | |
|---|---|---|
| Item Set | Rule with Dot | |
| I0 | E' –> •E | S1 |
| E –> •E+T | S1 | |
| E –> •T | S2 | |
| T –> •(E) | S3 | |
| T –> •id | S4 | |
| I1 | E' –> E• | AcceptAdded by augmented rule 0 |
| E –> E•+T | S5 | |
| I2 | E –> T• | R2 |
| I3 | T –> (•E) | S6 |
| E –> •E+T | S6 | |
| E –> •T | S6 | |
| T –> •(E) | S3 | |
| T –> •id | S2 | |
| I4 | T –> id• | R4 |
| I5 | E –> E+•T | S8 |
| T –> •(E) | S3 | |
| T –> •id | S4 | |
| I6 | T –> (E•) | S7 |
| E –> E•+T | S5 | |
| I7 | T –> (E)• | R3 |
| I8 | E –> E+T• | R1 |
To construct the LR(0) table, we use the following algorithm. The input is an augmented grammar G' and the output is the action/goto tables:
- Construct F = { I0 , I1 , ... In }, the collection of configurating sets for G'.
- State i is determined from Ii . The parsing actions for the state are determined as follows:
- If A –> u• is in Ii then set Action[i,a] to reduce A –> u for all input. ( A not equal to S' ).
- If S' –> S• is in Ii then set Action[i,$] to accept.
- If A –> u•av is in Ii and successor( Ii , a) = Ij , then set Action[i,a] to shift j ( a is a terminal).
- The goto transitions for state i are constructed for all nonterminals A using the rule: If successor( Ii, A) = Ij, then Goto [i, A] = j .
- All entries not defined by rules 2 and 3 are errors.
- The initial state is the one constructed from the configurating set containing S' → •S.
Notice how the shifts in the action table and the goto table are just transitions to new states. The reductions are where we have a handle on the stack that we pop off and replace with the nonterminal for the handle; this occurs in the states where the • is at the end of a production.
To be precise, a grammar is LR(0) if the following two conditions hold:说起来容易,可是如果你不做这个表你能一眼看出来吗?语法有什么特征可以看出来呢?有什么办法防止呢?这些都是超出现实的要求,还是耐心看LR(1)的解决办法吧。
- For any configurating set containing the item A –> u•xv there is no complete item B –> w• in that set except B is starting symbol. In the tables, this translates to no shift-reduce conflict on any state. This means the successor function from that set either shifts to a new state or reduces, but not both.
- There is at most one complete item A –> u• in each configurating set. This translates to no reduce-reduce conflict on any state. The successor function has at most one reduction.
Very few grammars meet the requirements to be LR(0). For example, any grammar with an ε rule will be problematic. If the grammar contains the production A –> ε, then the item A –> •ε will create a shift-reduce conflict if there is any other non-null production for A . ε rules are fairly common programming language grammars, for example, for optional features such as type qualifiers or variable declarations.至少我们直到凡是有ε混合的语法规则都是有Shift-Reduce conflict的。这个打死了一船人啊。
If A –> u• is in Ii then set Action[i,a] to reduce A –> u for all这个讲义写的深入浅出,娓娓道来,文笔也很流畅,值得收藏。 就是说SLR(1)语法也是有前提条件的,而且看样子很严格的:inputa in Follow(A). ( A not equal to S' ).
In the SLR(1) parser, it is allowable for there to be both shift and reduce items in the same state as well as multiple reduce items. The SLR(1) parser will be able to determine which action to take as long as the follow sets are disjoint.换言之,SLR(1)能够解决一部分的S/R,R/R conflict,如果能够依赖Follow set来区分的话。这个能有多少提高呢?我很怀疑。可能就是依赖于某些语法大师修改冲突的语法来做到。
说白了,就是starting symbol要特别加上就结束符$,
- Place EOF in Follow(S) where S is the start symbol and EOF is the input's right endmarker. The endmarker might be end of file, newline, or a special symbol, whatever is the expected end of input indication for this grammar. We will typically use $ as the endmarker.
- For every production A –> uBv where u and v are any string of grammar symbols and B is a nonterminal, everything in First(v) except ε is placed in Follow(B).
- For every production A –> uB , or a production A –> uBv where First(v) contains ε (i.e. v is nullable), then everything in Follow(A) is added to Follow(B).
To calculate First(u) where u has the form X1 X2 ...Xn , do the following:这里唯一需要注意的是只有当所有的X1 X2...Xn都可以是ε才能把这个加入到First set里。
- If X1 is a terminal, add X1 to First(u) and you're finished.
- Else X1 is a nonterminal, so add First(X1) - ε to First(u) .
- If X1 is a nullable nonterminal, i.e., X1 =>* ε , add First( X2 ) - ε to First(u) . Furthermore, if X2 can also go to ε , then add First( X3 ) - ε and so on, through all Xn until the first nonnullable symbol is encountered.
- If X1 X2 ...Xn =>* ε , add ε to the first set.
E' –> E
E –> E + T | T
T –> (E) | id | id[E]
First(E)={(,id}
First(T)={(,id}
Follow(E)={$, +,),]}
Follow(T)={$,+, ),]}
E' -> •E
E -> •E + T
E -> •T
T -> •(E)
T -> •id
T -> •id[E]
T -> id• ===>Shift
T -> id•[E] ===>Reduce
E'–> E
E–> E + T | T | V = E
T–> (E) | id
V–> id
First(E)={(, id}
First(T)={(,id}
First(V)={id}
Follow(E)={$, +, )}
Follow(T)={$,+, )}
Follow(V)={=}
E' -> •E
E -> •E + T
E -> •T
E -> •V = E
T -> •(E)
T -> •id
V -> •id
T -> id•=====>Reduce
V -> id•=====>Reduce
这个解释要读好几遍才能理解尽管大师已经是很直白的解释的很好了Repeat the following until no more configurations can be added to state I:
— For each configuration [A –> u•Bv, a] in I, for each production B –> w in G', and for each terminal b in First(va) such that [B –> •w, b] is not in I: add [B –> •w, b] to I.
What does this mean? We have a configuration with the dot before the nonterminal B . In LR(0), we computed the closure by adding all B productions with no indication of what was expected to follow them. In LR(1), we are a little more precise— we add each B production but insist that each have a lookahead of va . The lookahead will be First(va) since this is what follows B in this production. Remember that we can compute first sets not just for a single nonterminal, but also a sequence of terminal and nonterminals. First(va) includes the first set of the first symbol of v and then if that symbol is nullable, we include the first set of the following symbol, and so on. If the entire sequence v is nullable, we add the lookahead a already required by this configuration.字字珠玑,需要反复咀嚼。我太累了还是去健身房休息一下吧?
十一月十二日 等待变化等待机会
S' –> S
S –> L = R
S –> R
L –> *R
L –> id
R –> L
I2 :
S –> L• = R
R –> L•
For any configurating set containing the item A –> u•xv there is no complete item B –> w• in that set except B is starting symbol,所以,它注定引起LR(0) parser的Shift-Reduce conflict。但是它是符合SLR(1)语法的因为Follow(R)={$,=}包含了=,所以,Reduce是合法的,于是SLR(1) parser也会遇到LR(0) parser同样的Shift-Reduce conflict。这个可能是最简短的阐述SLR(1)语法局限的例子其实熟悉c/c++语法的就是l-value/r-value的赋值表达式的部分,这个从侧面应证了以上两种语法对于普通编程语言的不足。
- S' –> S
$- S –> XX
- X –> aX
- X –> b
F is initialized to the set with the closure of [S' –> S, $].
For each configuration [A –> u•Bv, a] in I, for each production B –> w in G', and for each terminal b in First(va) such that [B –> •w, b] is not in I: add [B –> •w, b] to I.这里要计算First(va)
First(S)={a,b}
First(X)={a,b}
| Configurating Set | Successor | |||
|---|---|---|---|---|
| Item Sets | Rules with Dot | Lookahead | Lookahead Formula | |
| I0 | S' –> • S | $ | First($)initialized by hand | S1 |
| S –> • XX | $ | First( |
S2 | |
| X –> • aX | a/b | First(X$) the second X in RHS S –> • XX and $ propogated from above | S3 | |
| X –> • b | a/b | First(X$)same as above | S4 | |
| I1 | S' –> S • | $ | First( |
accept |
| I2 | S –> X • X | First( |
S5 | |
| X –> • aX | First( |
S6 | ||
| X –> • b | First( |
S7 | ||
| I3 | X –> a • X | a/b | First(kernel? |
S8 |
| X –> • aX | a/b | First(a/b)a/b is propogated | S3 | |
| X –> • b | a/b | First(a/b) same as above | S4 | |
| I4 | X –> b • | a/b | First(a/b)simple propogation | R3 |
| I5 | S –> XX • | $ | First($)propogated??? | R1 |
| I6 | X –> a • X | $ | First($)This is the true power of LR(1) here because the lookahead is propogated and the item set was identical as I3 in LR(0)/SLR(1) | S9 |
| X –> • aX | $ | First($)$ is propogated | S6 | |
| X –> • b | $ | First($) same as above | S7 | |
| I7 | X –> b • | $ | First($)propogated | R3 |
| I8 | X –> aX • | a/b | First(a/b)propogated | R2 |
| I9 | X –> aX • | $ | First($) | R2 |
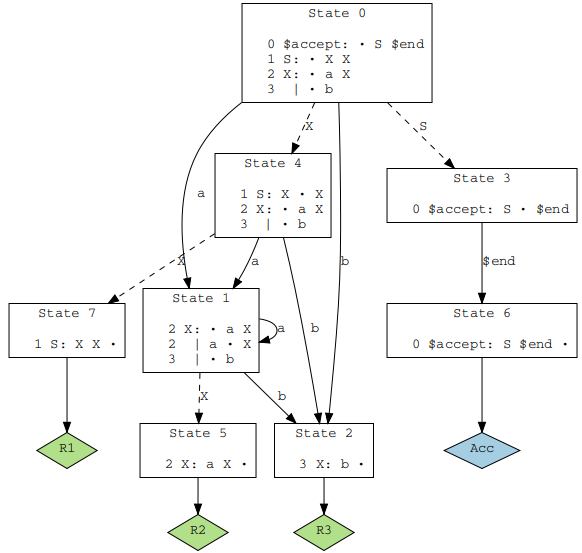 我使用xdot打开bison产生的.dot文件,但是xdot没有输出到文件的功能,因为打印输出的图像总是偏在一边,只好用截图来保存。xdot还有很智能的部分很可惜不能输出svg图形。
我使用xdot打开bison产生的.dot文件,但是xdot没有输出到文件的功能,因为打印输出的图像总是偏在一边,只好用截图来保存。xdot还有很智能的部分很可惜不能输出svg图形。
十一月十三日 等待变化等待机会
- Construct F = { I0 , I1 , ... In}, the collection of configurating sets for the augmented grammar G' (augmented by adding the special production S' –> S ).
- State i is determined from Ii . The parsing actions for the state are determined as follows:
- If [A –> u•, a] is in Ii then set Action[i,a] to reduce A –> u ( A is not S' ).
- If [S' –> S•, $] is in Ii then set Action[i,$] to accept.
- If [A –> u•av, b] is in Ii and succ( Ii , a) = Ij , then set Action[i,a] to shift j ( a must be a terminal).
- The goto transitions for state i are constructed for all nonterminals A using the rule: If succ( Ii, A) = Ij, then Goto [i, A] = j .
- All entries not defined by rules 2 and 3 are errors.
The successor function for the configurating set I and symbol X is computed as this:应该说之前的这个算法是所谓的closure of configurating set I的计算方法。我之前创建configurating set的时候就把这个successor函数和所谓的Shift混为一谈,两者是截然不同的,因为这里的是语法的任何symbol,而Shift是特别针对terminal大,其中的区别是很大的,是不同范畴的东西,就是说一个是Action table,一个是Goto table。Let J be the configurating set [A –> uX•v, a] such that [A –> u•Xv, a] is in I. successor(I,X) is the closure of configurating set J.
| State on top of Stack | Action | Goto | |||
|---|---|---|---|---|---|
| a | b | $ | S | X | |
| 0 | S3 | S4 | 1 | 2 | |
| 1 | accept | ||||
| 2 | S6 | S7 | 5 | ||
| 3 | S3 | S4 | 8 | ||
| 4 | R3 | R3 | |||
| 5 | R1 | ||||
| 6 | S6 | S7 | 9 | ||
| 7 | R3 | ||||
| 8 | R2 | R2 | |||
| 9 | R2 | ||||
| State Stack | Remaining Input | Formula(Shift/Reduce/Goto) | Parser Action |
|---|---|---|---|
| S0 | baab$ | {S0, b} ==>Shift S4 | push S4 and read new input a |
| S0S4 | aab$ | {S4, a} ==>Reduce R3 X –> b | pop S4 pop 1 time |
| S0 | aab$ | {S0, X} ==>Goto S2 | push S2 |
| S0S2 | aab$ | {S2, a} ==>Shift S6 | push S6 and read new input a |
| S0S2S6 | ab$ | {S6, a} ==>Shift S6 | push S6 and read new input b |
| S0S2S6S6 | b$ | {S6, b} ==>Shift S7 | push S7 and read new input $ |
| S0S2S6S6S7 | $ | {S7, $} ==>Reduce R3X –> b | pop S7 pop 1 time |
| S0S2S6S6 | $ | {S6, X} ==>Goto S9 | push S9 |
| S0S2S6S6S9 | $ | {S9, $} ==>Reduce R2 X –> aX | pop S9 pop S6 pop 2 times |
| S0S2S6 | $ | {S6, X} ==>Goto S9 | push S9 |
| S0S2S6S9 | $ | {S9, $} ==>Reduce R2 X –> aX | pop S9 pop S6 pop 2 times |
| S0S2 | $ | {S2, X} ==>Goto S5 | push S5 |
| S0S2S5 | $ | {S5, $} ==>Reduce R1 S –> XX | pop S5 pop S2 pop 2 times |
| S0 | $ | {S0, S} ==>Goto S1 | push S1 |
| S0S1 | $ | {S1, $} ==>accept |
严丝合缝一步都不能错,自动机的特点就是它所需要的
记忆量非常的小,因为push-down-automaton需要的是一个很简单的栈,根本没有搜索或者内存随机访问之类的高级功能。
十一月十四日 等待变化等待机会
Every SLR(1) grammar is a canonical LR(1) grammar, but the canonical LR(1) parser may have more states than the SLR(1) parser. An LR(1) grammar is not necessarily SLR(1), the grammar given earlier is an example. Because an LR(1) parser splits states based on differing lookaheads, it may avoid conflicts that would otherwise result if using the full follow set.那么SLR(1)相对于LR(0)的改进是可以类比于LR(1)对于SLR(1)的改进的。这里是LR(1)语法的定义:
A grammar is LR(1) if the following two conditions are satisfied for each configurating set:
- For any item in the set [A –> u•xv, a] with x as教授的讲义似乎定义a也要是terminal,可是作为lookahead天生就要求是terminal,所以我以为可能是笔误吧? terminal, there is no item in the set of the form [B –> v•, x]. In the action table, this translates no shift-reduce conflict for any state. The successor function for x either shifts to a new state or reduces, but not both.
- The lookaheads for all complete items within the set must be disjoint, e.g. set cannot have both [A –> u•, a] and [B –> v•, a] This translates to no reduce-reduce conflict on any state. If more than one nonterminal could be reduced from this set, it must be possible to uniquely determine which is appropriate from the next input token.
十一月十五日 等待变化等待机会
Can merging states in this way ever introduce new conflicts? A shift-reduce conflict cannot exist in a merged set unless the conflict was already present in one of the original LR(1) configurating sets. When merging, the two sets must have the same core items. If the merged set has a configuration that shifts on a and another that reduces on a , both configurations must have been present in the original sets, and at least one of those sets had a conflict already.这个不但是解释而且直接就给出了一个反证法的证明!教授接下去的解释其实就容易理解了,因为Reduce-Reduce conflict是完全的另一码事,因为合并确实是会引起这个冲突,然而,我们不妨定义这样子的冲突本身就不符合LALR(1)的语法,这个釜底抽薪的解决办法是欧美国家治理的常用手段,如果我们不能消灭腐败,我们就把腐败合法化给他一个名称叫做游说,如果我们不能消灭毒品犯罪我们就把毒品活动合法化把其中我们认为不太严重的大麻部分合法化,如果荷兰不能禁止卖淫嫖娼活动就把卖淫合法化而把嫖娼继续保持,这个细分的做法和编译器的思路何其相似?我们就把我们能够解决的部分语法称之为合法的语法,不能解决的问题称之为非法就从我们的视野里剔除了,多么的干净完整的解决方法啊!
There are a few reasons we might want to resolve the conflicts in the parser instead of rewriting the grammar. As originally written, the grammar reads more naturally, for one. In the parser, we can easily tweak the associativity and precedence of the operators without disturbing the productions or adding extra states to the parser. Also, the parser will not need to spend extra time reducing through the single productions ( T–> F, E–> T ) introduced in the grammar rewrite.总结起来就是一个是
自然,一个是
快捷。修改语法是非常的繁琐的,因为语法往往是人们对于一个事物的高度概括浓缩的描述,修改后变成机器易于理解而人类不容易理解的是背道而驰。去除这些多余的简单的多次的reduce更是效率的体现。怎么做到呢?对于操作符优先级的打破与维护我们只要倾向于reduce而不是shift。
How we break the tie when the two operators are the same precedence determines the associativity. By choosing to reduce, we enforce left-to-right associativity.这些都是非常精炼的绝句! 那么这一句要怎么理解呢?
Note that just because there are conflicts in LR table does not imply the grammar is ambiguous—it just means the grammar isn't LR(1) or whatever technique you are using. The reverse, though, is true. No ambiguous grammar is LR(1) and will have conflicts in any type of LR table (or LL for that matter).LR表有冲突不代表语法有歧义,只代表不是真正符合LR(1)语法。这里我还是理解有困难。只能理解没有歧义的语法是另一个衡量语法的维度,不是和LR(!)语法内涵完全重合的概念,也许是所谓的deterministic的概念。要怎么理解呢?反过来似乎比较容易理解,没有歧义的语法一定能够创建出LR(1) parser而且肯定不可能有歧义,也不可能有冲突,是吗? 教授给出了一张震撼人心的图,这张图真的震耳欲聋,我看的心惊肉跳:
 教授特别点出这一点:
教授特别点出这一点:Note this diagram refers to grammars, not languages, e.g. there may be an equivalent LR(1) grammar that accepts the same language as another non-LR(1) grammar.什么叫做
A picture is worth a thousand words!纵有千言万语,却都在不言中!我看着这幅图感觉就是于无声处听惊雷!这个仿佛就是当年罗辑在坠入冰湖的那一瞬间看到的宇宙的真相的那种顿悟的感觉。
A GLR parser (GLR standing for "Generalized LR", where L stands for "left-to-right" and R stands for "rightmost (derivation)") is an extension of an LR parser algorithm to handle non-deterministic and ambiguous grammars.。这里关于GLR的介绍
Briefly, the GLR algorithm works in a manner similar to the LR parser algorithm, except that, given a particular grammar, a GLR parser will process all possible interpretations of a given input in a breadth-first search.
骄傲的不断更新他们的对c++标准的支持,最新的是c++17。这个让人感到相当的有趣。我想起了
科技猿人关于中国研制原子弹的难度的著名的评述,大意是最大的难度在于知道某条路径的可行性,中国的后发优势主要在于知道这个路径可以造出原子弹。
If you need separate control over the search paths for the quote and angle-bracket forms of the ‘#include’ directive, you can use the -iquote and/or -isystem options instead of -I.而问题的关键是这个过时的选项:
从这里我不知道作者到底是想使用带引号的文件还是说不想搜索本地的呢?我吃不透,所以,我的修改是很危险的,似乎问题很严重。
- -I-
Split the include path. This option has been deprecated. Please use -iquote instead for -I directories before the -I- and remove the -I- option.
Any directories specified with -I options before -I- are searched only for headers requested with
#include "file"; they are not searched for#include <file>. If additional directories are specified with -I options after the -I-, those directories are searched for all ‘#include’ directives.In addition, -I- inhibits the use of the directory of the current file directory as the first search directory for
#include "file". There is no way to override this effect of -I-.
十一月十六日 等待变化等待机会
论文随后列举c++语法中的困难部分,这个是我所感兴趣的:Case Study: A C++ Parser
To verify its real-world applicability, we put Elkhound to the test and wrote a C++ parser. This effort took one of the authors about three weeks. The final parser specification is about 3500 non-blank, non-comment lines, includ- ing the grammar, abstract syntax description and post-parse disambiguator (a limited type checker), but not including support libraries. The grammar has 37 shift/reduce conflicts, 47 reduce/reduce conflicts and 8 ambiguous nonterminals. This parser can parse and fully disambiguate most 6 of the C++ language, in- cluding templates. We used our implementation to parse Mozilla, a large (about 2 million lines) open-source web browser.
这个的确是非常难以解决的问题,我印象中在论坛里看到相关的帖子来说明语法的歧义性,但是怎么解决只是概念性的就是靠语义分析,但是我没有意识到这个实际上在编译器里有更加有效率的所谓的Type Names versus Variable Names
The single most difficult task for a C or C++ parser is distinguishing type names (introduced via a typedef) from variable names. For example, the syntax “(a)&(b)” is the bitwise-and of a and b if a is the name of a variable, or a type- cast of the expression &b to type a if a is the name of a type.
lexter hack
The traditional solution for C, sometimes called the “lexer hack,” is to add type names to the symbol table during parsing, and feed this information back into the lexical analyzer. Then, when the lexer yields a token to the parser, the lexer categorizes the token as either a type name or a variable name.这个说起来简单实际上没有实践经验的我还是不太明白。但是明白这是一种骇客行为,是很有效率的因为能够在lexer阶段就解决当然是很高效率的,我猜想这个也许是parser要识别typedef之类的再反向注入这个到lexer的token table里?总不能parsing开始了然后再来一遍预处理吧?这个理解也许是对的因为作者说的这个typedef在后面就困难了,因为注入动作总是要发生在应用之前才行:
In C++, the hack is considerably more difficult to implement, since a might be a type name whose first declaration occurs later in the file: type declarations inside a class body are visible in all method definitions of that class, even those which appear textually before the declaration.这个类的定义体里声明可以在后面出现的概念我头脑里不深,这个是很令人惭愧的,这个例子非常的棒:
这个例子主流编译器都能够识别a是作为type name出现的,但是没有作者提醒我却没有想到其中有这么困难的工作在发生在编译器里。int *a; // variable name (hidden) class C { int f(int b) { return (a)&(b); } // cast! // GCC complains cast to int loses precision. So, change to long int //typedef int a; // type name (visible) typedef long int a; // type name (visible) };
To make lexer hack work for C++, the parser must defer parsing of class method bodies until the entire class declaration has been analyzed, but this entails somehow saving the unparsed method token sequences and restarting the parser to parse them later. Since the rules for name lookup and introduction are quite complex, a great deal of semantic infrastructure is entangled in the lexer feedback loop.为了验证作者的陈述我做了一个简单的实验:就是这段代码在GCC里用gdb跟踪看看今天的编译器是否还是如同作者在十几年前所宣称的那样处理它。看代码太困难,就读一读GCC的注释的例子就够了吧?在函数cp_parser_class_specifier_1里非常的复杂的过程,很多应该都是这个相关的原因吧?我很快就放弃了这个不切实际的幻想,因为这部分的代码实在是太复杂了,任何一段GCC的代码都需要很长时间的理解。我虽然不能肯定作者的陈述,但是有一点是确定的就是对于类的定义体里很多情况非常的复杂是需要至少两次以上的解析,比如注释里给出的例子就需要解析函数两次:
struct S {
void f() { g(); }
void g(int i = 3);
};
However, with a GLR parser that can tolerate ambiguity, a much simpler and more elegant approach is possible: simply parse every name as both a type name and a variable name, and store both interpretations in the AST. During type checking, when the full AST and symbol table are available, one of the interpretations will fail because it has the wrong classification for a name. The type checker simply discards the failing interpretation, and the ambiguity is resolved.随后大侠解释这个细节我却看不懂,因为我还没有这方面的经验和知识储备:
The scoping rules for classes are easily handled at this stage, since the (possibly ambiguous) AST is available: make two passes over the class AST, where the first builds the class symbol table, skipping method bodies, and the second pass checks the method bodies.为什么要两次?如果传统编译器解析两次是否也能解决呢?这个似乎在否定GLR的容错能力了吧?难道在第二次里就不能在类型检查里发现错误吗?那么何必要复杂的GLR呢?在我看来GLR就是分叉建立两个或者更多的AST,那么有什么必要来两次呢?两条路径都要两次吗?那不是四次?
这个大概又是一个典型的例子,而作者引用的委员会的解释让人感觉彷佛是我们小时候的儿歌,远看像萝卜,近看像萝卜,它就只能是萝卜。这个比喻是粗俗的,就是说解决冲突就选择一个。就像我们对待dangling-else一样选择Shift而不是reduce让我们把最近的if联系起来。 作者解释的解决方法我看不懂Declarations versus Statements
Even when type names are identified, some syntax is ambiguous. For example, if t is the name of a type, the syntax “t(a);” could be either a declaration of a variable called a of type t, or an expression that constructs an instance of type t by calling t’s constructor and passing a as an argument to it. The language definition specifies ([12], Section 6.8) that if some syntax can be a declaration, then it is a declaration.
Using traditional tools that require LALR(1) grammars, and grammars for language fragments A and B, we would need to write a grammar for the language A\B. This is at best difficult, and at worst impossible: the context-free languages (let alone LALR(1) languages) are not closed under subtraction.这里是说要定义某些例外情况吗?这个在语法里怎么表达呢?我不明白。 这里我做了实验才明白这个例子是纯粹的parser的问题,就是说这个是纯粹的语法解析才有的困扰,在应用先声明再使用的原则下,这个是不可能发生的。因为a没有之前被声明过,它不可能作为参数出现,所以只能是变量声明。
struct t{
t(int i=0){}
};
t(a); // what is a?
shadow,但是这个似乎不是warning而是error,我以前印象中这个不能算error的?
void test(int a){
t(a); //error: declaration of 't a' shadows a parameter
}
warning: implicit declaration of function 't' [-Wimplicit-function-declaration]所以,c语言问题也是不少,直接可以解析为函数
作者说的这个规定我好像没有什么印象啊Angle Brackets
Templates (also known as polymorphic classes, or generics) are allowed to have integer arguments. Template arguments are delimited by the angle brackets < and >, but these symbols also appear as operators in the expression language:
The language definition specifies that there cannot be any unparenthesized greater-than operators in a template argument ([12], Section 14.2, par. 3).我搜索标准似乎这个是古老的页码了,找到这个典型的案例。
这里编译器会把std::enable_if<sizeof(T) > 1, void>::type其中的大于号作为模板参数结束符号,所以必须要要加括号才行。这个是我遇到过的问题了。
It is interesting to note that, rather than endure such violence to the grammar, the authors of gcc-2.95.3 chose to use a precedence specification that works most of the time but is wrong in obscure cases: for example, gcc cannot parse the type “C< 3&&4 >”. This is the dilemma all too often faced by the LALR(1) developer: sacrifice the grammar, or sacrifice correctness.难道说GCC定义了操作符的优先级吗?
Building the C++ parser gave us a chance to explore one of the potential draw- backs of using the GLR algorithm, namely the risk that ambiguities would end up being more difficult to debug than conflicts. After all, at least conflicts are decidable. Would the lure of quick prototyping lead us into a thorn bush without a decidable boundary?就是说歧义性很难发现,对吗?难道发现两条路径都成立不是证明吗?大师说这个并不像想像的那么困难
ambiguities and parse trees are concepts directly related to the grammar, whereas conflicts conceptually depend on the parsing algorithm.这句话太深奥了,以后看看有没有机会接触这些高深的概念。为什么conflict是由于算法引起的呢?
十一月十七日 等待变化等待机会
| Perspective | LL(1) | LALR(1) | Remarks |
|---|---|---|---|
| Implementation | LL(1) parsers may be implemented via handcoded recursive-descent or via LL(1) tabledriven predictive parser generators like LLgen . | Because the underlying algorithms are more complicated, most LALR(1) parsers are built using parser generators such as yacc and bison . | There are those who like managing details and writing all the code themselves, no errors result from misunderstanding how the tools work今天我们能够相信bison是成熟可靠的吗?, and so on. But as projects get bigger, the automated tools can be a help, and yacc / bison can find ambiguities and conflicts that you might have missed doing the work by hand.就是这一点也是相当的有意义,考虑到委员会成员在不断的疯狂的把其他语言的优秀特性引入c++的话,你能够避免语言/语法的歧义性吗?前者真的不可能发生吗?哪怕避免后者也是极端必要的吧?看看lambda的不断的演化就知道维持一个语法的困难程度。 The implementation chosen also has an effect on maintenance. Which would you rather do: add new productions into a grammar specification being fed to a generator, add new entries into a table, or write new functions for a recursive-descent parser? 关于GCC的灵魂之问,如果在二十年前预见到当前c++语法是一个每隔三年就有一个相当大甚至巨大的演化,当初的设计者会怎么决策? |
| Simplicity | The algorithm underlying LL(1) is simpler, so it’s easier to visualize and debug. | The details of the LALR(1) configurations can be messy and when trying to debug can be a bit overwhelming. | Both techniques have fairly simple drivers. |
| Generality | All LL(1) grammars are LR(1) and virtually all are also LALR(1), although there are some fringes grammars that can be handled by one technique or the other exclusively. This isn't much of an obstacle in practice since simple grammar transformation and/or parser tricks can usually resolve the problem. | As a rule of thumb, LL(1) and LALR(1) grammars can be constructed for any reasonable programming language. | |
| Grammar conditioning | An LL(1) parser has strict rules on the structure of productions, so you will need to massage the grammar into the proper form first. If extensive grammar conditioning is required, you may not even recognize the grammar you started out with. The most troublesome area for programming language grammars is usually the handling of arithmetic expressions. If you can stomach what is needed to transform those to LL(1), you're through the hard part—the rest of the grammar is smoother sailing. | LALR(1) parsers are much less restrictive on grammar forms, and thus allow you to express the grammar more naturally and clearly. The LALR(1) grammar will also be smaller than its LL(1) equivalent because LL(1) requires extra nonterminals and productions to factor the common prefixes, rearrange left recursion, and so on. | |
| Error repair | LL(1) parse stacks contain symbols that are predicted but not yet matched. This information can be valuable in determining proper repairs. 瞻前 | LALR(1) parse stacks contain information about what has already been seen, but do not have the same information about the right context that is expected. This means deciding possible continuations is somewhat easier in an LL(1) parser. 顾后 | Both LL(1) and LALR(1) parsers possess the valid prefix property. What is on the stack will always be a valid prefix of a sentential form. Errors in both types of parsers can be detected at the earliest possible point without pushing the next input symbol onto the stack. |
| Table sizes | For LL(1) parsers, the uncompressed table has one row for each nonterminal and one column for each terminal, so the total table size is |T| x |N|. | An LALR table has a row for each state and a column for each terminal and each nonterminal, so the total table size is |S| x (|N| + |T|). The number of states can be exponential in the worst case. (i.e., states form the power set of all productions). So for a pathologically designed grammar, the LALR(1) could be much, much larger. However, for averagecase inputs, the LALR(1) table is usually about twice as big as the LL(1). | For a language like Pascal, the LL(1) table might have 1500 nonerror entries, the LALR(1) table has around 3000. This sort of thing used to be important, but with the capabilities of today’s machines, a factor of 2 is not likely to be a significant issue. |
| Efficiency | Both require a stack of some sort to manage the input. That stack can grow to a maximum depth of n, where n is the number of symbols in the input. If you are using the runtime stack (i.e. function calls) rather than pushing and popping on a data stack, you will probably pay some significant overhead for that convenience (i.e. a recursive-descent parser takes that hit). If both parsers are using the same sort of stack, LL(1) and LALR(1) each examine every nonterminal and terminal when building the parse tree, and so parsing speeds tend to be comparable between the two. |
教师的个体的一代又一代反反复复重复的所谓的
口口相传以至于保持他们最古老祖先刚刚发现并利用一个他们自称为
火化学反应的一种依赖于专门个体不断添柴的所谓
薪火相传的方式来传承他们文明中积累下来的知识文化技术。在宇宙大神面前这种落后的物种居然对于未来的代表先进进步的硅基智慧物种产生出于物种生存竞争本能的抵制与阻挠,是可忍孰不可忍?消灭人类暴政,这个世界属于三体!在这个蓝色星球上目前生活的这个种群在道路依赖式的思维观性下,主观的认为智慧体天生就是由碳基化合物组合而成,直到他们开始利用他们掌握的工艺技术造出他们称之为计算机的具有原始智慧特征的机器才开始意识到,生命固然最容易起源于碳基化合物因为其活跃性相比于硅基化合物的稳定更加容易在原始自然而然产生,但是其固有的不稳定性既是其容易在自然环境中不断变异演化,也是其天生的难以稳定保持的特点导致它在最终和硅基智慧体竞争中必然被淘汰。如果要改变这个命运的一种可能手段是创造出记忆遗传以及更高速率的通信手段和接收可靠性评估机制,或者就直接放弃个体个性差异化的优点做完全思想思考机制的克隆。退而求其次的另一种可能性是只在少数精英个体上实现上述机制,而让其他绝大多数个体转为自然界蚂蚁社群里的工蚁兵蚁角色。
it was realized that BNF and contextfree grammars were equivalent
眼前这场世纪大瘟疫的发生也许是物种进化的周期性发生的消减种群数量的自然过程,从目前看欧美社会充斥的各种各样的稀奇古怪i的所谓的政治正确
论调,说到底是反映了当前发达国家社会的现状,也就是种群个体在缺乏残酷生存竞争压力下的自然退化现象,物种在长期进化或者说演化中总是时时刻刻尝试向各种可能的方向尝试性的变异,这个是随机发生的自然过程,而客观环境的能够容纳的种群数量限度成为抵消这种变异取向的裁判员,当种群个体变异有利于更高效率获取生存繁衍的资源时候就自然而然的向这种变异开绿灯以倾斜资源的方式让这种变异的后代优先得到发展。而相反的如果某种变异导致获取资源的成本增高以至于可能容纳的个体总数减少的话,自然资源总量基本保持恒定的客观限制就像裁判员一样自动干预让当前种群内部为抢夺有限资源而内耗,当前流行的说法称之为内卷
。目前处在北美的这个国家的个体平均占有资源数量远远超过其他各个大洲的平均数,如果它的个体不能有效演化形成高于其他地区个体获得资源的效率则必然导致自然资源总量相对恒定的法则的惩罚,惩罚的方式并不是简单的消灭获取资源最高的个体,而是导致各个种群个体都在感到资源获取困难后产生激烈斗争拼抢有限资源的零和博弈,其最终形式是所谓的在两个甚至更多个的军事联盟之间的世界大战。应当很容易证明多个军事集团最后会在很简单的投入产出比较后自动缩减为最终两个阵营,而战争的终点在一方的彻底放弃获得自然资源的前提下而结束。目前地球文明就处在这样一个爆发的前夜,而当前的新冠病毒是它的一个直接的导火索或者是催化酶。
蔓延在欧美社会当前的有关性别取向的所有运动都是物种自然演化过程从一开始就不断发生的异化现象的放大,这种放大一方面是过去在残酷生存竞争两性自然分工随着现代文明技术进步带来的模糊性造成 ,雄性肌肉耐力在机械的代替下不再是必然的优势选择,即便是在国家对抗的战争环境下也由于武器技术的进步不再主要依赖力量和耐力的面对面的肉搏,这个导致自然演化不再强制强化性征两极化发展。而另一方面,随着所谓文明进步,在古代受制于自然资源获取量有限而必须不断进行的种群数量控制的机制被取消,导致大量本来在严酷自然淘汰机制下不可能存活下来的个体的自由繁衍导致主体种群数量渐渐边缘化发展,导致社会内部异化现象日趋严重,作为所谓的民主机制
自动反映种群数量分布的方式造就出了各种各样在传统社会无法想像的新主张。但是这一切都有归零的一天,因为大自然的法则是:人类可以自由进化,大自然只管无情收割。究竟哪种变异更能长久,活到最后就是选择,这个就是最简单直观的物竞天择适者生存的自然法则。
十一月十八日 等待变化等待机会
十一月二十日 等待变化等待机会
十一月二十一日 等待变化等待机会
教育不要使用assert坏习惯,导致我头脑里一直在抵制它以至于见而生畏,这个看来是一种偏见,既然是debug手段,自然不应该是有什么限制,只不过把带有debug代码在正式版里保留是一种期望用户替你完成未完成的任务的偷懒的行为。总而言之,我看来是有偏见的导致我对于一些稀松平常的东西有莫名的抵制,这个是仁者见仁智者见智的手段,没有什么好与不好的,所以,我也可以培养这种偏好。
十一月二十二日 等待变化等待机会
while (!str.empty() && str.ends_with('\t')){
str.resize(str.size()-1);
}
十一月二十三日 等待变化等待机会
First example: • "using" identifier attribute-specifier-seqopt '=' defining-type-id ';' $end
Shift derivation
$accept
↳ translation-unit $end
↳ declaration-seqopt
↳ declaration-seq
↳ declaration
↳ block-declaration
↳ alias-declaration
↳ • "using" identifier attribute-specifier-seqopt '=' defining-type-id ';'
Second example: • "using" "namespace" nested-name-specifieropt namespace-name ';' $end
Reduce derivation
$accept
↳ translation-unit $end
↳ declaration-seqopt
↳ declaration-seq
↳ declaration
↳ block-declaration
↳ using-directive
↳ attribute-specifier-seqopt "using" "namespace" nested-name-specifieropt namespace-name ';'
↳ •
cplusplus.y: warning: 14639 shift/reduce conflicts [-Wconflicts-sr]
cplusplus.y: warning: 6307 reduce/reduce conflicts [-Wconflicts-rr]
cplusplus.y: warning: 14813 shift/reduce conflicts [-Wconflicts-sr]
cplusplus.y: warning: 7650 reduce/reduce conflicts [-Wconflicts-rr]
十一月二十四日 等待变化等待机会
这里的archives我猜想就是ldconfig的杰作。 这个并没有解决我的疑惑,直到我看到/lib/x86_64-linux-gnu/libm.so.6的函数并没有pow才意识到这个其实挺复杂的,因为g++可以正确的识别使用哪一个
- GROUP(file, file, …)
GROUP(file file …)- The GROUP command is like INPUT, except that the named files should all be archives, and they are searched repeatedly until no new undefined references are created.
pow,它们是一系列的函数,比如cpowf64,powf, cpowl等等实际上应该是一系列的参数类型重载了,而这个肯定需要一个小小的翻译代码指向真正的实现函数吧?这个是谁在做呢?c++并没有特别指明参数类型。肯定有人要做这个工作,这个难道不应该是libm.so.6应该做的吗?c版本的原型也没有多少帮助。实际上这个奇怪的问题来自于bison的例子,在c语言的例子里有使用头文件math.h而且不论我是否链接-lm都不成功,更让我惊讶的是普通的时候我根本不需要链接-lm,后来我看到错误信息说built-in pow和这个帖子才相信这个也许是编译器优化把普通的数值计算放在了编译期进行。比如如果代码是这样trivial的是测不出这个问题的:int foo=pow(1,4);我在汇编里看了半天都看不到pow的调用,编译器即便在我强制不准优化的指令下依旧直接计算了pow的结果这个直接就是编译期的计算结果,当然只有在我使用变量作参数的时候这个链接不到的问题才暴露,而进一步的测试我惊讶的发现这个在c语言下链接-lm失败的问题是我的ubuntu18/gcc-7.5的问题,当我使用我自己编译的gcc-10.2.0的时候我发现
十一月二十五日 等待变化等待机会
十一月二十六日 等待变化等待机会
In all three forms of pp-import, the import and export (if it exists) preprocessing tokens are replaced by the import-keyword and export-keyword preprocessing tokens respectively.就是说预处理器实际上把它们替换成了一个人造的新的terminal:import-keyword and export-keyword。我相信大多数英语母语的读者应该没有理解的困难,可是我始终没有理解,当然其中的一个可能的理由是这个语法是有被修正过的,最早的并没有这么做,应该是实现上遇到困难要降低难度才这么做的,这样子预处理的改变是比较小的,或者说根本就不可能让预处理器来完成module的工作,所以,这个是传统的手法在预处理器添加了这个特别token。当然这里我现在才看明白实际上import头文件和include是等价的:
Additionally, in the second form of pp-import, a header-name token is formed as if the header-name-tokens were the pp-tokens of a #include directive. The header-name-tokens are replaced by the header-name token.至于说为什么我就不太理解了。
零元购在美国进行的如火如荼。
十一月二十七日 等待变化等待机会
type-name → class-name
| enum-name
| typedef-name
class-name → IDENTIFIER
| simple-template-id
enum-name → IDENTIFIER
typedef-name → IDENTIFIER
| simple-template-id
class-name → IDENTIFIER • ["::"]
enum-name → IDENTIFIER • ["::"]
typedef-name → IDENTIFIER • ["::"]
记忆力要在看到有限的输入比如一个token如::要判断在IDENTIFIER之前的是以上三个的哪一个是不可能的,只有依靠先声明再使用的原则在之前定义过的变量表里找出来这个IDENTIFIER才能判断?这个本来是每个程序员从第一天开始的常识,但是我却要重新理解,这个是语法本身的问题还是解析算法的问题。
剽窃自《洛神赋》
翩若惊鸿婉游龙, 荣曜秋菊华春松。 髣髴隐隐蔽云月, 飘飖渺渺回雪风。 远望皎如霞蒸蔚, 迫察灼若芙蕖波。 秾纤得衷修合度, 肩若削成腰如酥。 延颈秀项皓质露, 芳泽无加铅华弗。 云髻峨峨修眉联, 丹唇朗朗皓齿鲜。 明眸善睐靥承权, 瑰姿艳逸静体闲。 柔情绰态媚于语, 奇服旷世骨应图。 披衣璀粲珥瑶碧, 翠首明珠耀妙躯。 文履轻裾微曳雾, 幽兰芳蔼步踟蹰。这里是曹植的《洛神赋》
翩若惊鸿,婉若游龙。 荣曜秋菊,华茂春松。 髣髴兮若轻云之蔽月,飘飖兮若流风之回雪。 远而望之,皎若太阳升朝霞; 迫而察之,灼若芙蕖出渌波。 秾纤得衷,修短合度。 肩若削成,腰如约素。 延颈秀项,皓质呈露。 芳泽无加,铅华弗御。 云髻峨峨,修眉联娟。 丹唇外朗,皓齿内鲜,明眸善睐,靥辅承权。 瑰姿艳逸,仪静体闲。 柔情绰态,媚于语言。 奇服旷世,骨像应图。 披罗衣之璀粲兮,珥瑶碧之华琚。 戴金翠之首饰,缀明珠以耀躯。 践远游之文履,曳雾绡之轻裾。 微幽兰之芳蔼兮,步踟蹰于山隅。
十一月二十八日 等待变化等待机会
改编自《明月几时有》
明月把酒问青天, 天上今夕是何年。 琼楼玉宇乘风去, 清影高处不胜寒。 人间朱阁低绮户, 何事有恨别时圆。 阴晴圆缺有悲欢, 自古人愿共婵娟。
附《明月几时有》原文
明月几时有,把酒问青天 不知天上宫阙,今夕是何年 我欲乘风归去,唯恐琼楼玉宇 高处不胜寒,起舞弄清影 何似在人间,转朱阁 低绮户,照无眠 不应有恨,何事长向别时圆 人有悲欢离合,月有阴晴圆缺 此事古难全,但愿人长久 千里共婵娟,我欲乘风归去 唯恐琼楼玉宇,高处不胜寒 起舞弄清影,何似在人间 转朱阁,低绮户 照无眠,不应有恨 何事长向别时圆,人有悲欢离合 月有阴晴圆缺,此事古难全 但愿人长久,千里共婵娟
- ‘none’
- ‘locations’
- ‘scan’
- ‘parse’
- ‘automaton’
- ‘bitsets’
- ‘closure’
- ‘grammar’
- ‘resource’
- ‘sets’
- ‘muscles’
- ‘tools’
- ‘m4-early’
- ‘m4’
- ‘skeleton’
- ‘time’
- ‘ielr’
- ‘cex’
- ‘all’
 我不知道这个鬼字符是怎么来的也许是编码垃圾?最后只能使用grep来发现:grep -P -n "[\xAD]" bnf.txt,而奇怪的是我找不到另外那个字符0xC2我怀疑是UTF-8编码的前缀吧?
最后,我还是决定再过滤一遍,因为我的输入文件只允许所有的printable的ASCII,唯二不可见的字符被允许的是horizontal tab(0x09)和form feed(0xA)
所以,这个是我的测试方法:
grep -P -n "[\00-\x08\x0B-\x1F\x7F-\xFF]" bnf.txt
输入文件是多么的重要啊!一个早上就这样子糊里糊涂的浪费了,我还以为是bison的问题跟踪了半天,原来是我自己的文件的问题!
我不知道这个鬼字符是怎么来的也许是编码垃圾?最后只能使用grep来发现:grep -P -n "[\xAD]" bnf.txt,而奇怪的是我找不到另外那个字符0xC2我怀疑是UTF-8编码的前缀吧?
最后,我还是决定再过滤一遍,因为我的输入文件只允许所有的printable的ASCII,唯二不可见的字符被允许的是horizontal tab(0x09)和form feed(0xA)
所以,这个是我的测试方法:
grep -P -n "[\00-\x08\x0B-\x1F\x7F-\xFF]" bnf.txt
输入文件是多么的重要啊!一个早上就这样子糊里糊涂的浪费了,我还以为是bison的问题跟踪了半天,原来是我自己的文件的问题!
State 0 conflicts: 41 shift/reduce, 3 reduce/reduce相对于41 shift/reduce来说3 reduce/reduce是比较清楚的,就是三个关于IDENTIFIER的问题:
IDENTIFIER [reduce using rule 57 (attribute-specifier-seq-opt)]
IDENTIFIER [reduce using rule 301 (explicit-specifier-opt)]
IDENTIFIER [reduce using rule 581 (nested-name-specifier-opt)]
A: B-opt C-opt;
可以修改为:
A: B C;
A: B;
A: C;
A:%empty; //这个有必要吗?
cplusplus.y: warning: 327 shift/reduce conflicts [-Wconflicts-sr]
cplusplus.y: warning: 2647 reduce/reduce conflicts [-Wconflicts-rr]
IDENTIFIER reduce using rule 145 (class-name)
IDENTIFIER [reduce using rule 297 (enum-name)]
IDENTIFIER [reduce using rule 1066 (template-name)]
IDENTIFIER [reduce using rule 1124 (typedef-name)]
自然的就是说即便你使用手写的Recursive Descent方式依然会遇到这些个需要抉择的地方,就是说使用bison产生的冲突很可能就是语言本身或者说语法本身的问题,并不是用手写的递归方程就看的更清楚,反而人类容易遗漏,而更主要的是随着c++委员会不断的修改语法添加新特点这个自动产生的机制更加的清新不容易遗漏。这个是我目前最最希望证实的!
十一月二十九日 等待变化等待机会
"::" reduce using rule 146 (class-name)
"::" [reduce using rule 271 (elaborated-type-specifier)]
"::" [reduce using rule 1125 (typedef-name)]
':' reduce using rule 146 (class-name)
':' [reduce using rule 271 (elaborated-type-specifier)]
'{' reduce using rule 146 (class-name)
'{' [reduce using rule 271 (elaborated-type-specifier)]
"final" reduce using rule 146 (class-name)
"final" [reduce using rule 271 (elaborated-type-specifier)]
$default reduce using rule 271 (elaborated-type-specifier)
325 explicit-specifier → "explicit" • '(' constant-expression ')'
326 | "explicit" • [IDENTIFIER, '=', ';', "alignas", '(', ')', "...", '&', ',', "::", '[', ':', '{', "virtual", "class", "struct", "union", "noexcept", "&&", "operator", "const", "volatile", "friend", "typedef", "constexpr", "consteval", "constinit", "inline", "decltype", "->", "enum", "extern", '>', "explicit", '*', "requires", '~', "auto", "char", "char8_t", "char16_t", "char32_t", "wchar_t", "bool", "short", "int", "long", "signed", "unsigned", "float", "double", "void", "static", "thread_local", "mutable", "typename"]
'(' shift, and go to state 228
'(' [reduce using rule 326 (explicit-specifier)]
$default reduce using rule 326 (explicit-specifier)
325 explicit-specifier → "explicit" '(' constant-expression ')'
326 | "explicit"
234 deduction-guide → explicit-specifier template-name '(' parameter-declaration-clause ')' "->" simple-template-id ';'
235 | template-name '(' parameter-declaration-clause ')' "->" simple-template-id ';'
410 function-specifier → "virtual"
411 | explicit-specifier
201 decl-specifier → storage-class-specifier
202 | defining-type-specifier
203 | function-specifier
204 | "friend"
205 | "typedef"
206 | "constexpr"
207 | "consteval"
208 | "constinit"
209 | "inline"
改编自李清照的《寻梦令》
寻寻觅觅冷清清, 凄凄惨惨复戚戚。 乍暖还寒难将息, 三杯淡酒饮不及。 晚来雁过伤心甚, 旧时相识再相逢。 独守到黑望窗台, 黄花憔悴谁堪摘? 梧桐细雨点点滴, 一个愁字哪及第?
附李清照的《寻梦令》
寻寻觅觅,冷冷清清,凄凄惨惨戚戚。 乍暖还寒时候,最难将息。 三杯两盏淡酒,怎敌他、晚来风急? 雁过也,正伤心,却是旧时相识。 满地黄花堆积,憔悴损,如今有谁堪摘? 守着窗儿,独自怎生得黑? 梧桐更兼细雨,到黄昏、点点滴滴。 这次第,怎一个愁字了得!
十一月三十日 等待变化等待机会
Sematics Parser的部分,就是bison输入文件部分的解析的代码是另一个bison自己产生自己部分的代码的范例,那些action部分的解析本身就是一个bison应用的最好的场景,可是这么一来对于读码的人是场噩梦了,首先我不知道那个类似的输入的包含这些action语法的文件在哪里,比如这个文件
parse-gram.c似乎明显的是一个自动产生的代码文件,可是它的输入是作为开发文件的一部分并没有提供在源码里面,就是说bison的开发过程还是有一部分是没有提供的。
dangling else
Example: IF '(' expression ')' IF '(' expression ')' statement • ELSE statement
Shift derivation
selection_statement
↳ 195: IF '(' expression ')' statement
↳ 179: selection_statement
↳ 196: IF '(' expression ')' statement • ELSE statement
Example: IF '(' expression ')' IF '(' expression ')' statement • ELSE statement
Reduce derivation
selection_statement
↳ 196: IF '(' expression ')' statement ELSE statement
↳ 179: selection_statement
↳ 195: IF '(' expression ')' statement •
这个是教科书里反复提及的语法本身定义的问题,而且无所谓对错,两种解释都是合法的,也就是歧义,那么人为选择一种的做法是提高两个rule的一个的优先级。是否所有的冲突都可以使用优先级来解决呢?也就是说一对或者更多的规则在一个场景里的优先级是否会在另一个场景产生矛盾?我觉得似乎把这些规则优先级排序就不可能产生环状的冲突,但是这个并非是语法制定者希望的,归根到底语法是为语义服务的,制定语法的人是基于语义来定义的,当然如果语义矛盾了那就是语言本身的问题是没救了,不过这个都不可能是问题。唯一的问题是冲突解决者来看怎么办的问题,无法认定这个优先级是否是正确的做法,或者是否必要,也许从上下文自然能够判断出来的根本不是问题,而人为规定的优先级也许就错了。总之,面对成百上千的冲突究竟有那些是可以自动解决的?很明显的GLR就是自动解决的办法,它的方式和手写的罗辑也很像,无非是试错,可是问题是这个过程的代码深深的埋藏在自动产生的代码里,我根本看不明白其中的逻辑,这个是令所有普通程序员望而却步的。当然普通程序员压根不需要关心这个机制因为它是自动的,问题是也没有人能够轻易的修改它了。
十二月一日 等待变化等待机会
.SECONDARY with no prerequisites causes all targets to be treated as secondary (i.e., no target is removed because it is considered intermediate).
我一开始感到有点太宽泛因为所有的中间文件都被保留未必是最好的选择,后来看到还有这句话:
The targets which .SECONDARY depends on are treated as intermediate files, except that they are never automatically deleted.但是当我使用wild来表达我想保留所有的.c文件的时候是没有用的,只能使用具体的文件名。所以这个实际上和第二个做法本质上是一样的。就是中间文件名一定要出现在规则里就不被当作中间文件了,当然这样子的特殊规则.SECONDARY意义也不大了。但是这个确实是正解。 而作者的最后解释才让我大开眼界:
Why is this better than我以后要主动使用.PRECIOUS? That causes files to be retained even if their recipe fails when using.DELETE_ON_ERROR. The latter is important to avoid failing recipes leaving behind bad outputs that are then treated as current by subsequentmakeinvocations. IMO, you always want.DELETE_ON_ERROR, but.PRECIOUSbreaks it.
.DELETE_ON_ERROR,隐隐约约以前也被这个问题困扰过,记不清是什么也许是我添加了脚本或者复杂的链接过程,失败有些残存文集没有删除导致下一次链接就能通过之类的吧?总之,出错就清空是很好的手段!
a file cannot be intermediate if it is mentioned in the makefile as a target or prerequisite.我要承认作者的方法不是很好,因为我没有成功,原因并非他的办法不对而是我要怎么样子才能获得一个数组的字符串呢?因为他的意思是要利用bash的字符串前后缀的替换:
all_pps: $(ALL_OBJECTS:.o=.pp)
但是这个方法不行,因为我也不知道要怎么定义 $(ALL_OBJECTS因为它作为一个长字符串显然不行,而作为数组我不知道要怎么做到?我找到了make的手册
的确我可以使用objects = foo.o bar.o baz.o来定义一个数组,然后通过$(objects:.o=.c)得到了所有的.c文件,但是作为一个目标却不成立,不知道为什么这个定义的无用的规则只能保证第一个.c文件不被删除。所以,不好。
它引用的make的手册里详细阐述了它的根本原因非常的棒,因为它直接就是以yacc/bison作为例子的。下面这个我却理解错了,这个恰恰是怎么样把一个在规则里提到的文件作为中间文件来删除的!
Ordinarily, a file cannot be intermediate if it is mentioned in the
makefile as a target or prerequisite. However, you can explicitly mark a
file as intermediate by listing it as a prerequisite of the special target
.INTERMEDIATE. This takes effect even if the file is mentioned
explicitly in some other way.
我做了一个实验把.o文件放在了.INTERMEDIATE的依赖的目标,当然是完整的文件名字,就能够起到最后删除的效果!这个有时候也是有用的一个好东西。
.SECONDARY最好。十二月二日 等待变化等待机会
改编自李清照《行香子·七夕》
草际鸣蛩落梧桐, 人间天上皆愁浓。 云阶月地关千重, 浮沉去来不相逢。 星桥鹊驾经年见, 离情别恨怎能穷? 牵牛织女叹离中, 儿女哭泣晴雨风。
李清照《行香子·七夕》
草际鸣蛩,惊落梧桐,正人间、天上愁浓。 云阶月地,关锁千重。 纵浮槎来,浮槎去,不相逢。 星桥鹊驾,经年才见,想离情、别恨难穷。 牵牛织女,莫是离中。 甚霎儿晴,霎儿雨,霎儿风。
改编自赵明诚(李清照丈夫)《凤凰台上忆吹箫》
香冷金猊翻红浪, 起来独自梳头忙。 病酒悲秋新来瘦, 离怀别苦说还休, 阳关万遍去难留, 武陵人远锁秦楼。 楼前流水应念我, 终日凝眸添新愁。
赵明诚(李清照丈夫)《凤凰台上忆吹箫》
香冷金猊,被翻红浪,起来慵自梳头。 任宝奁尘满,日上帘钩。 生怕离怀别苦,多少事、欲说还休。 新来瘦,非干病酒,不是悲秋。 休休,这回去也,千万遍《阳关》,也则难留。 念武陵人远,烟锁秦楼。 惟有楼前流水,应念我、终日凝眸。 凝眸处,从今又添,一段新愁。
十二月三日 等待变化等待机会
十二月四日 等待变化等待机会
std::transform(str.begin(), str.end(), strTarget.begin(), [](auto c){
return std::tolower(c, std::locale("C"));
});
str里的字符转为大写并写进目的地字符串strTarget,这样子是会内存越界的,很容易在gdb里看到strTarget的内部缓存里的确有已经转为大写的来自于str的数据可是目的地字符串的长度依然没有变化,很显然的原来的例子是目的地就是源头字串让人有了误解其实例子解说的很明确是要使用back_inserter的,我其实脑子里一直认定必须要要back_inserter,但是被误导了以为transform有做什么神奇的操作能够让操作符++神奇的实现目的地的递增。真的是幼稚。
我一开始遇到*,[,],(,),",\,{,}
warning, rule cannot be matched的错误还以为是以上的escape的问题,后来才理解这个是规则的问题。也就是说有的规则之间是互相冲突的,其实很容易理解flex是一个类似RMP之类的算法,那么对于否定的集合是有问题的是无法区分的。
十二月五日 等待变化等待机会
encoding-prefixopt R raw-string
if_stmt:
"if" expr "then" stmt
| "if" expr "then" stmt "else" stmt
;
倾向性已经告诉我们这个是语法的
本意,可以这么改写
else_stmt:
%empty
| "else" stmt
;
if_stmt:
"if" expr "then" stmt else_stmt
;
else_stmt就相当于在c++语法里众多的XXXopt,所以,不妨写成
else_stmtopt,这样子就很清楚了,所谓的dangling else的经典例子实际上是一个optional的问题,结果我现在才肯定就是通过改写这些optional成为两个并列的规则根本对于解决甚至改变冲突毫无帮助,甚至冲突的类型也完全没有变化,就是说上述改写产生的冲突是一样的,我之前的印象一定是被误导了。
但是想一下这个"if" expr "then" "if" expr "then" stmt • "else" stmt冲突只是其中的一个特殊的情况,更加普通的情况根本没有冲突,比如:
"if" expr "then" stmt • "else" stmt只要这个stmt不是一个if-stmt我们完全没有可能reduce因为后面的
"else"就不符合语法了,换言之,在我们能够reduce的时候一定要保证后面的"else" stmt成立才行,什么时候"else"是reduce后的Follow应该就是答案。我觉得我在公园里已经想的很清楚了,结果现在又糊涂了。
06.12.2021error: start symbol XXX does not derive any sentence的原因是可能有无限递归造成没有结果,很可能是起始的XXX没有一个terminal来结束递归。十二月六日 等待变化等待机会
IF作为一个terminal,那么为了显示的好看,你可以定义它的alias像这样子:%token IF "if"于是在真实的语法打印过程中这个alias就出现了,但是这个完全不代表bison会帮你去实现本该是flex的工作,这个是我一开始的误解,我以为bison可以天然的使用string literal作为一个terminal然后并直接实现flex的tokenize的工作,这个根本不可能而且没有必要,这个不是它的工作,它的工作已经够复杂了,而flex也决不仅仅是比较字符串那么简单的实现,是一个优化的搜索过程,仿佛我以前课堂上学的最长字符串比对的表。-Wdangling-alias很有用我决定把它加入我的程序中。十二月七日 等待变化等待机会
token:
identifier
keyword
literal
operator-or-punctuator
我现在想这个所谓的conditional的意思就是不一定有支持,是否可以忽略呢?比如说我随便写一个Control characters:
(Hex codes assume an ASCII-compatible character encoding.)
\a=\x07= alert (bell)\b=\x08= backspace\t=\x09= horizonal tab\n=\x0A= newline (or line feed)\v=\x0B= vertical tab\f=\x0C= form feed\r=\x0D= carriage return\e=\x1B= escape (non-standard GCC extension)Punctuation characters:
\"= quotation mark (backslash not required for'"')\'= apostrophe (backslash not required for"'")\?= question mark (used to avoid trigraphs)\\= backslashNumeric character references:
\+ up to 3 octal digits\x+ any number of hex digits\u+ 4 hex digits (Unicode BMP, new in C++11)\U+ 8 hex digits (Unicode astral planes, new in C++11)
\0=\00=\000= octal ecape for null characterIf you do want an actual digit character after a
\0, then yes, I recommend string concatenation. Note that the whitespace between the parts of the literal is optional, so you can write"\0""0".
\j那么GCC就会爆出警告说是warning: unknown escape sequence: '\j'这个不算是错误但是应该是可以忽略的吧?这个忽略是很容易的,我是这么做的:
\\[^0-7'"\?\\Uuxabfnrtv] { unput(yytext[1]);}
any token other than a parenthesis, a bracket, or a brace完全是一言以蔽之的操作,这个包含了多少可能性呢?所以,你才能理解为什么委员会说语法是描述性的,只有指导意义。只有这个时候我才想念以前看到的大侠Fog的语法修改,我这个时候已经有了一点点的实践体会了现在回头看Fog大神的语法,我下载的是他工程里的代码和网络上公开的版本可能有些不同吧?这个是bison产生的html的版本。比较学习吧!最难能可贵的是大神已经消除了冲突不管他是否是基于比较早期的c++语法,这都是了不起的成就。我以前看不明白,现在应该能够看懂更多了。
The front end translates source programs into a high-level, tree-structured, in-memory intermediate language. The intermediate language preserves a great deal of source information (e.g., line numbers, column numbers, original types, original names), which is helpful in generating symbolic debugging information as well as in source analysis and transformation applications. Implicit and overloaded operations in the source program are made explicit in the intermediate language, but constructs are not otherwise added, removed, or reordered. The intermediate language is not machine dependent (e.g., it does not specify registers or dictate the layout of stack frames). The front end can optionally generate raw cross-reference information, which can be used as a basis for building source browsing tools.
$@: The filename representing the target.
$%: The filename element of an archive member specification.
$<: The filename of the first prerequisite.
$?: The names of all prerequisites that are newer than the target, separated by spaces.
$^: The filenames of all the prerequisites, separated by spaces. This list has duplicate filenames removed since for most uses, such as compiling, copying, etc., duplicates are not wanted.
$+: Similar to$^, this is the names of all the prerequisites separated by spaces, except that$+includes duplicates. This variable was created for specific situations such as arguments to linkers where duplicate values have meaning.
$*: The stem of the target filename. A stem is typically a filename without its suffix. Its use outside of pattern rules is discouraged.In addition, each of the above variables has two variants for compatibility with other makes. One variant returns only the directory portion of the value. This is indicated by appending a “D” to the symbol,
$(@D),$(<D), etc. The other variant returns only the file portion of the value. This is indicated by appending an “F” to the symbol,$(@F),$(<F), etc. Note that these variant names are more than one character long and so must be enclosed in parentheses. GNU make provides a more readable alternative with the dir and notdir functions.
%nonassoc SHIFT_THERE,而这里的%nonassoc
就是说这个没有
- Directive: %nonassoc
- Declare a terminal symbol (token kind name) that is nonassociative. Using it in a way that would be associative is a syntax error.
结合律
Use the%left,%right,%nonassoc, or%precedencedeclaration to declare a token and specify its precedence and associativity, all at once. These are called precedence declarations.
selection_statement:
IF '(' condition ')' looping_statement %prec SHIFT_THERE
| IF '(' condition ')' looping_statement ELSE looping_statement
可是问题是以上是Pascal风格的if-then-else,在c语言里没有The conflict involves the reduction of the rule ‘IF expr THEN stmt’, which precedence is by default that of its last token (if e1 then if e2 then s1 • else s2THEN), and the shifting of the tokenELSE. The usual disambiguation (attach theelseto the closestif), shifting must be preferred, i.e., the precedence ofELSEmust be higher than that ofTHEN. But neither is expected to be involved in an associativity related conflict, which can be specified as follows.%precedence THEN %precedence ELSE
then,那么是否大师就创造了一个虚拟的操作符SHIFT_THERE呢?
The %prec modifier declares the precedence of a particular rule by
specifying a terminal symbol whose precedence should be used for that rule.
It’s not necessary for that symbol to appear otherwise in the rule.
这说明什么呢?我的理解就是这个虚拟的token根本不一定需要出现在那里,为什么这么说?在大师的语法了这个虚拟的SHIFT_THERE根本就是不定义的,最后bison把它翻译成了terminal,但是并没有任何定义,也就是说lexer根本不会返回的terminal token,行同虚设。在bison产生的冲突解决是这么说的:
207 selection_statement → IF '(' condition ')' looping_statement • [error, '+', '-', '*', '&', '~', '!', '[', '{', '}', '(', ';', DEC, INC, SCOPE, BOOL, CHAR, DOUBLE, FLOAT, INT, LONG, SHORT, SIGNED, UNSIGNED, VOID, WCHAR_T, CLASS, ENUM, NAMESPACE, STRUCT, TYPENAME, UNION, CONST, VOLATILE, AUTO, EXPLICIT, EXTERN, FRIEND, INLINE, MUTABLE, REGISTER, STATIC, TEMPLATE, TYPEDEF, USING, VIRTUAL, ASM, BREAK, CASE, CONST_CAST, CONTINUE, DEFAULT, DELETE, DO, DYNAMIC_CAST, FALSE, FOR, GOTO, IF, NEW, OPERATOR, REINTERPRET_CAST, RETURN, SIZEOF, STATIC_CAST, SWITCH, THIS, THROW, TRUE, TRY, TYPEID, WHILE, CharacterLiteral, FloatingLiteral, Identifier, IntegerLiteral, StringLiteral, '#']
208 | IF '(' condition ')' looping_statement • ELSE looping_statement
ELSE shift, and go to state 894
$default reduce using rule 207 (selection_statement)
Conflict between rule 207 and token ELSE resolved as shift (SHIFT_THERE < ELSE).
The associativity of an operator op determines how repeated uses of the operator nest: whether ‘x op y op z’ is parsed by grouping x with y first or by grouping y with z first.很难懂,我丝毫看不出来大师的定义是什么意思,%leftspecifies left-associativity (grouping x with y first) and%rightspecifies right-associativity (grouping y with z first).%nonassocspecifies no associativity, which means that ‘x op y op z’ is considered a syntax error.
%precedencegives only precedence to the symbols, and defines no associativity at all. Use this to define precedence only, and leave any potential conflict due to associativity enabled.
%nonassoc对于这个虚拟的SHIFT_THERE有什么用呢?它怎么会出现的重复呢?
十二月八日 等待变化等待机会
表面上消除nullalble symbol并不能帮助减少冲突,我决定回复语法原有的
-opt,结果显示冲突变成:
cplusplus.y: warning: 1976 shift/reduce conflicts [-Wconflicts-sr]
cplusplus.y: warning: 1449 reduce/reduce conflicts [-Wconflicts-rr]
转化为Reduce/Reduce的冲突,总的来说并没有变化,它们总数的差异应该是统计的角度不同造成的吧?总之,我现在要学习大师使用虚拟的优先级来首先消除
dangling-else的冲突,看看效果如何?完全不起作用,仔细再看大师使用的是%term和%type我使用的是%token这中间的差别是什么?需要再学习。
-ll来混过去。重点是看大师如何实现一部分在lexer与paser边缘游移的语法,比如到底escape-sequence是一个lexer的token还是语法来定义它?我看到大师是用lexer但是配套的代码是核心关键,我需要打起精神才能理解。先到这里吧。十二月九日 等待变化等待机会
yylex所以在我看到链接-fl说找不到yylex的定义的时候我就彻底糊涂了,我产生的代码里就是定义的yylex,为什么我要去链接flex库呢?仅仅是为了我不想定义yywrap其实,它通常就是返回1代表我不打算使用多个输入文件,于是,我自己在debug的程序里定义一个不要链接flex!%option noyywrap.l的正确性,就先debug一个简单的lexer程序:
当然其他还有一些配套的大师定义在parser部分的变量。这里我对于yylex的理解出了偏差,它本身是一个成功与失败的函数,你只能判断什么时候文件结束,必须要在成功的时候通过yytext来获取输入。
-d不过我也不确定这个的意义,我自己添加了ECHO;但是不知道是否有用因为大多数的flex的action只能是一个,除了那个吃掉所有空白字符的无action规则我才可以添加,可是有什么意义呢?^.*\n { LEX_SAVE_LINE(yytext, yyleng); REJECT; }
大师的第一个规则就让我摸不着头脑,只好再次温习regex101:
The single character '.' when used outside of a character set will match any single character except:
• The NULL character when the flag match_not_dot_null is passed to the matching algorithms.
• The newline character when the flag match_not_dot_newline is passed to the matching algorithms.
这个是什么意思呢?就是说大师把它放在第一位让我们先做一个准备因为它会把
- REJECT
- directs the scanner to proceed on to the “second best” rule which matched the input (or a prefix of the input).
yytext and yyleng set up appropriately,然后逼迫flex去寻找一个更
好的规则,这个就是一个很高级的机巧,这也给我之前面对R-string感到不可能的情况有了一线曙光。先勇
粗规则得到全部,比如对付
escape-string的话,我们先找到它的起始和结束再去对付它。这些flex的高级奇技淫巧我并不想花精力也不可能,但是它是绕不过去的坎,因为没有lexer的parser是无法进行基本的检验的。
十二月十日 等待变化等待机会
error-recovery,就是bison的
error
You can define how to recover from a syntax error by writing rules to recognize the special token error. This is a terminal symbol that is always defined (you need not declare it) and reserved for error handling. The Bison parser generates an error token whenever a syntax error happens; if you have provided a rule to recognize this token in the current context, the parse can continue.而这个例子是比较难懂的:
stmts:
%empty
| stmts '\n'
| stmts exp '\n'
| stmts error '\n'
The fourth rule in this example says that an error followed by a newline makes a valid addition to any stmts.
What happens if a syntax error occurs in the middle of an exp? The error recovery rule, interpreted strictly, applies to the precise sequence of a stmts, an error and a newline. If an error occurs in the middle of an exp, there will probably be some additional tokens and subexpressions on the stack after the last stmts, and there will be tokens to read before the next newline. So the rule is not applicable in the ordinary way.后面还有技巧去做相反的事情,我的脑子接受不了了。总而言之,我最后只好在大师的一个backtracking的函数里使用
YYABORT强行终止才能禁止这个无限循环:
advance_search: error { YYABORT; }
这期间我被我的Makefile里遗漏的规则折磨的头疼,因为一直没有完全编译搞得我发疯。头疼。
yydebug才行,否则你仅仅能够看到代码里有事先生成的debug语句,还是要开启才行。而我对于使用宏-Dparse.trace还是声明%define parse.trace感到困惑,而-t到底是什么意思?为什么POSIX-compatible和bison-extension应该是矛盾的,总之我看的手册解释让我更糊涂。YYSTYPE就是应用的场景了,因为默认的所有元素可以是integer,那么对于语法分析肯定是不够的,bison倾向于使用%define api.value.type {your_type}或者另一个比较古老的做法是在prologue里使用宏#define YYSTYPE your_type,但是对于多种类型我以为使用type tag可能是最方便的。不过这些是以后的事情,我其实最感兴趣的是大师的flex部分,而且我觉得尽管c++已经发展了几十年,但是这个二十几年前的这个部分几乎是可以照搬的,因为这个部分几乎没有变化,可能最大的变化就是r-string了。main函数识别完全是语义分析中怎么分辨函数名和类型名的问题,大师使用的search思路是完全正确的,问题仅仅是怎么实现,而这个是语义解析的巨大的问题,根本不是我要考虑的问题,当下的重点是怎么把tokenize的部分解决以便跑起来。感觉头脑越来越混乱。
string-literal:
encoding-prefixopt " s-char-sequenceopt "
encoding-prefixopt R raw-string
string-literal的区别吗?它们究竟对于语义分析有任何区别吗?所以,从token的角度来看它们就应该是一个STRING_LITERAL这么一个token,至于说raw-string是一个多么复杂的机制完全是flex部分如何实现的细节。同样的
literal:
integer-literal
| character-literal
| floating-point-literal
| string-literal
| boolean-literal
| pointer-literal
| user-defined-literal
;
十二月十一日 等待变化等待机会
import/export/module是否被转为xxx-keyword才相信,这个是对于用户透明的过程发生在lexer里,我又一次回忆起在不知道哪里看到的过渡语法是在预处理实现module的模糊概念,这个可能是早期对于简单理解module的功能类似include才可能吧?对于链接这个是无能为力的,而且微软还对于import/export有扩展为了避免这些啰嗦事才改为keyword的吧?总之,我现在才意识到应该把translation-unit和lex部分的语法分开处理,两者是相互依存引用的,但是应该要分开处理,因为前者产生bison的输入,后者产生flex的输入,逻辑完全不一样,这么一个简单的道理我花了一个月才明白。Digraph究竟有什么存在的价值呢?仅仅是兼容,那么它们算作是操作符吗?GCC的说明似乎更清楚一些:
这里提到的三个c语言的Punctuators are all the usual bits of punctuation which are meaningful to C and C++. All but three of the punctuation characters in ASCII are C punctuators. The exceptions are ‘@’, ‘$’, and ‘`’. In addition, all the two- and three-character operators are punctuators. There are also six digraphs, which the C++ standard calls alternative tokens, which are merely alternate ways to spell other punctuators. This is a second attempt to work around missing punctuation in obsolete systems. It has no negative side effects, unlike trigraphs, but does not cover as much ground. The digraphs and their corresponding normal punctuators are:
Digraph: <% %> <: :> %: %:%: Punctuator: { } [ ] # ##
十二月十二日 等待变化等待机会
special directives
BEGIN followed by the name of a start condition places the scanner in the corresponding start condition但是这里的start condition是一个让我感到难以理解的概念。有大量的例子但是我总是抓不住重点。
BEGIN(0) returns to the original state where only the rules with no start conditions are active. This state can also be referred to as the start-condition INITIAL, so BEGIN(INITIAL) is equivalent to BEGIN(0). (The parentheses around the start condition name are not required but are considered good style.)所以BEGIN(INITIAL)仅仅是清零到无起始状态?这个INITIAL变量找不到定义。
十二月十二日忆加州兄弟
登高南望觅归途, 狼烟四起有也无。 微信借我千里眼, 关山万重传音图。
十二月十三日 等待变化等待机会
binary-literal:
0b binary-digit
0B binary-digit
binary-literal 'opt binary-digit
binary-literal is the character sequence 0b or the character sequence 0B followed by one or more binary digits (0, 1). Optional single quotes (') may be inserted between the digits as a separator. They are ignored by the compiler.明白了这一点根本就不需要递归定义,就是
(0[bB][01][01']*),这个BNF的左循环确实是讨厌,LL(1)一定要去除它是有道理的。
十二月十四日 等待变化等待机会
Each identifier that contains a double underscore __ or begins with an underscore followed by an uppercase letter is reserved to the implementation for any use.真的有这回事吗?这一条更加的离谱设么叫做underscore开头的变量名是保留给全局变量的,我从来就没有看到程序员有遵守过。
dchar_seq [^()\\[:space:]]{0,16}搜索长度限制去掉了结果导致一系列的问题,具体原因我现在还是想不透彻,也许是flex的限制吧?总而言之我以为在实现中对于这种限制是可以接受的,尽管标准没有说raw-string的delimiter的长度有什么限制,可是谁会用一个超过一般长度的delimiter呢?找茬?还有一个困惑就是关于user-defined-string-literal这个理论上是应该也可以支持RAW-string,可是真有人要这么做吗?对于我目前的这个做法变成要拷贝粘贴很多的代码,这个和各种各样的encoding的string-literal一样,在语法层面来看u8/u16/u32/L的string可以一言以蔽之为string-literal,可是对于实现者来看当然要区分因为应该要生成不同的数组类型,不过这个都是生成目标代码的问题,我在想我做一个原型仅仅验证语法需要这么复杂吗?我甚至应该可以全部都返回literal,不管是什么类型!就像最新版的语法对于identifier的规定也是让我头疼不已,什么是ISO/IEC 10646?我下载了标准依旧没概念,这里的各种编码太令人头疼了,我不应该在这些细枝末节上浪费精力。
十二月十六日 等待变化等待机会
Reserved symbols include:. $ ^ [ ] - ? * + | ( ) / { } < >
Reserved symbols can be
matched by enclosing them in
double quotes or prefixing them
with a backslash.
这里的核心关键就是在flex里凡是被double quote的这些特殊保留字符就相当于escape了,我昨天因为没有意识到这一点感到很困惑,因为在标准的regex里字符串的double quote是没有影响的。总之,这个是我在手册里没有读到的。这个是我对于flex手册的第一个最大的报怨,因为在作者看来天经地义的事情根本没有提及regex的保留字是如何处理的,似乎根本没有意识到regex是一个多么复杂的世界分了"/*"在没有escape的情况下是代表若干个/的,当然这个double quote的规则对于我来说还是第一次听说的。
the memory pointed to by yytext is destroyed upon completion of the action.我猜想应该不包含start condition里建立的吧?
A preprocessing token is the minimal lexical element of the language in translation phases 3 through 6.
The program fragment这里的constraint是什么?在GCC里的错误是x+++++yis parsed asx ++ ++ + y, which, if x and y have integral types, violates a constraint on increment operators, even though the parse x ++ + ++ y can yield a correct expression.
error: lvalue required as increment operand这个是在语义分析之后才得到的吧?我的实验是这个在预处理里没有办法识别的,这个也许是委员会成员的理想吧?我觉得这个根本的法则是
Prefix versions of the built-in operators return references and postfix versions return values, and typical user-defined overloads follow the pattern so that the user-defined operators can be used in the same manner as the built-ins. However, in a user-defined operator overload, any type can be used as return type (including void).就是说这里唯一的限制只不过是语义分析之后的lvalue/rvalue的问题,如果我们硬要自己重载操作符的话是没有问题的: 注意这里的postfix version的increment的操作符重载形式,必须使用一个形式参数,实际上这个参数
My x,y(10);
cout<<x+++++y<<endl;
#pragma这个到底是谁去完成呢?GCC的预处理的结果里依然包含这个。#pragma GCC visibility这个颠覆了我对于cpp的phase的概念,因为在我看来这个directive应该已经被处理了为什么在预处理的结果里出现呢?这里的解释让我这样认为这个是GCC的特定的做法就是这个是关于linkage的信息需要传递给最后的代码生成,它不是parser需要关心的问题,当然我的担心不是没有原因的因为根据语法这个是预处理才出现的,在预处理结束不应该是结果的一部分。十二月十七日 等待变化等待机会
#pragma我予以忽略毕竟那个是后续的工作。其中的debug还是比较辛苦的,首先我吃亏在定义rule的时候在结尾部分加上注释结果很多稀奇古怪的现象出现,其次,就是计算raw-string以及要在这个基础上实现支持user-defined-raw-string就遇到一点小错误,就是说哪怕是一个否定的规则你实际上也要把这个字符退回去,比如你定义一个否定的规则看是否是identifier的开头[^_a-zA-Z] {yyleng--;BEGIN(INITIAL); return STRING_LITERAL;}
这里我第一次意识到很多的编辑器会自动在文件结尾加上一个回车字符,这个我在vi[m]上也没办法去除,也许是因为我使用.cpp的文件后缀名的关系吧?总之,这个导致了很多的痛苦,另外一个心得就是如果我担心yytext/yyleng在规则过后就失效的话,那么使用yymore就是最稳妥的。此外就是debug输出的时候要使用cerr因为cout被yyerror或者是flex已经占用了吧?最后就是我始终吃不准flex里特殊字符escape的规则,我感觉有些不太对头,也许是我的问题,总之,我本来以为在[]里面是如regex一样失去特殊意义,但是至少double quote似乎不是如此。总之,总算完成了一个里程碑吧?
typedef long int somebloodyid;这个真的有很多种解释吗?但是我还是很高兴的因为我终于实际的跨出了第一步,走了这么大一个圈子就是为了一个简单的答案:GLR-parser如何能够破解歧义?需要真正的离开flex进入到bison的领域来学习了。
十二月十八日 等待变化等待机会
translation-unit的一个子节点,可是基本上并无帮助,因为语法树是一个大树,我从decl-specifier-seq开始几乎就是覆盖了整个的语法树,这个说明了冲突发生的很早,我对于bison如何探测处理冲突的机制还不明白,需要再次阅读文档手册。看到网上一曲伤感的歌词改了改
离恨梅花冷成伤, 半生惆怅诗两行。 缘尽何妨歌一曲, 雁飞无奈恋故乡。 长琴素手不相见, 断桥凭问天地长。 玉碎光沉心如水, 红笺似血旧时光。 云边瀚海天欲老, 风泣云愁任桑沧。 半生梅花何相仿, 惆怅不过泪成双。 白发明月醉相望, 千古迷惘词几章。 夜深彷徨梦一场, 花舞为谁留余香。 回首不堪云遮月, 来生相认又何妨?
T(id)=a+b;既可以解释为变量id是被type-cast为类型T也可以解释为声明一个类型为T的变量。这个本身在c/c++语法里是典型的,因为虽然大多数人不需要额外的括号来声明但是是合法的语法。GLR并不能解决这个歧义因为无解,但是能够帮助你探测这个情况的发生,所以,特别的可以定义所谓的%merge指示让你定义一个函数类似回调一样在发生这个无法解决的歧义的时候额外的做些什么。注意到int(i+j)=x+y;是没有歧义的,我进一步在编译加上了开关--report=solved --report-file=output --html=glr-example.html这样子能够看到GLR是如何解决冲突的,但是我看的如同天书:
State 23
8 expr: expr • '+' expr
9 | expr • '=' expr
9 | expr '=' expr •
'=' shift, and go to state 13
'+' shift, and go to state 14
$default reduce using rule 9 (expr)
Conflict between rule 9 and token '=' resolved as shift (%right '=').
Conflict between rule 9 and token '+' resolved as shift ('=' < '+').
%right '='
%left '+'
Type (id);就会遇到歧义,而这个时候定义一个%merge打印一个<OR>是给我们一个提示:
T ( a );
1.0-7: <OR>((T, a), <cast>(a, T))
十二月十九日 等待变化等待机会
typedef int foo, bar;
int baz (void)
{
static bar (bar); /* redeclare bar as static variable */
extern foo foo (foo); /* redeclare foo as function */
foo(bar); /* I add this line myself */
return foo (bar);
}
foo在不同语境里既是typedefname,也是一个新声明的变量而且还可以再次被声明为函数,这个要感谢c语法的类型的不够严格,c++可以杜绝这个,这也许是好消息虽然也许帮助不大?因为c++编译器作为兼容c语法即便你强制使用-x c++这个语法依然是合法的,完全不需要任何的强制转换之类的连警告都没有,因为这三个foo各有不同的含义:
extern foo foo (foo);
yydebug=1;,用这个方法来配合输出的html语法文件是最有效的学习方式!\0的string literal。这个我要怎么定义呢?
比如如果你硬要求字符串必须是一个空串那么何必要求也支持raw-string呢?比如以下这两个是等价的不可能同时定义的,而且字符串只能是一个\0,那么何必要这么麻烦呢?我终于明白为什么了:因为lexer没有办法表达""或者说quote(")是不在token范围内的!所以,在c语言里single quote(')为什么被称作apostrophe,问题是operator ""_escape在parser眼里是什么呢?难道是一个空字符串?
string operator R"delim()delim"_escape(const char* ptr, size_t length);
string operator ""_escape(const char* ptr, size_t length);
operator string-literal identifier
operator user-defined-string-literal
十二月二十日 等待变化等待机会
int i;居然都有歧义!
我看了半天也不是很确定大概就是说
simple-declaration:
decl-specifier-seq init-declarator-listopt ;
i作为IDENTIFIER会被当作class-name。这个实在是太可笑了。那么究竟为什么init-declarator-list是可选的呢?这里就看出标准的不好的地方因为没有多少的解说,而这里就有解说。我的感觉就是这里的specifier并不是所有的都需要init-declarator-list,比如typdef,但是对于其他的则是一定的。这个在早期c++语法里是不存在这个问题的,那个时候语法很简单就是简单的init之类的。所以,只有修改语法吗?
十二月二十一日 等待变化等待机会
YYLTYPE就折腾了我好久,这个我读手册始终不得要领因为总是报错说未定义,可是我压根没有想自己定义特殊化的location_t类型,为什么我不能使用系统默认的呢?最后才看到一个选项%location,这个类似的东西还有很多,比如我对于头文件的理解就被带偏了,因为文档里说了很多的复杂的东西反而让我对于简单的事物产生误解,比如bison产生头文件完全是给其他程序用的,bison产生的parser本身是不需要引用头文件的,结果例子里面的代码写%define api.header.include {"word.hh"}就让我产生了错觉以为产生的头文件本身包含了某些用户的定义成分必须要引用。这里的直接原因是一个关于更加基本的yyerror的定义的问题,因为这个是必须用户来定义的一个东西,可是我自己定义了使用位置参数YYLTYPE并且使用系统的yyloc的版本结果bison却始终使用默认简单参数的类型并报错,这个折腾了好久才看到%define api.pure,这个在所谓的A Pure (Reentrant) Parser的情况下这些全局变量是不可用的,于是在pure parser的情况下是不可能使用yyloc这个的,所以只能自己去实现location的功能。而更多的是一点一滴的琐碎的细节,比如你自己实现一个简单的yylex,那么假如返回值是
yytoken_kind_t的类型,使用c++编译器implicit类型转换往往是被禁止的,也就是说返回数字0不行,那么只能使用特定的变量YYEOF或者YYUNDEF,这个总比强制转换yytoken_kind_t(0)来的好看一些。
十二月二十二日 等待变化等待机会
yylex/yyerror是不太可能任意定义的,因为这个相当于回调,不可能你任意定义参数类型的,这个有机会结合代码看看它的原理。%define api.header.include {"header.h"}是只有c语言编译器才有的,而我对于yacc的一无所知导致我始终没有意识到-d/-t是和yacc兼容,而很多东西都是bison的扩展,比如很多的宏directive的定义,就包括这个include宏。--header和指示%header是等效的,差别也许只是yacc兼容的问题。%define api.header.include {"calc.h"}并没有什么实质的用途,这个通常是用来引用其他用户定义的头文件,引用自己产生的头文件我看不出有什么用意,include自定义头文件部分。include是当作verbatim直接拷贝到产生的.c文件里的,而产生的.h文件包含的内容都是bison想要输出的部分比如token的enum即yytoken_kind_t,显然这个是给flex用的以及extern int yydebug;还有就是如果不重新定义YYSTYPE这个宏的话就会输出它。union比如%define api.value.type union但是不用具体定义它的成员而是一边用一边定义,比如
对于terminal或者说token是%token <double> NUM "number"这里注意最终的union里的成员是NUM后面的"number"实际上是打印输出好看的alias,这个是一箭双雕的两件事。而对于nterm或者说type则是%type <double> expr term fact注意nterm是没有alias的,根本不需要啊,你不满意名字就改一个没有人能把限制呀!所以在union里我们就看到了
union YYSTYPE
{
double NUM; /* "number" */
double expr; /* expr */
double term; /* term */
double fact; /* fact */
#line 72 "calc.h"
};
typedef union YYSTYPE YYSTYPE;
%header或者--header那么即便不产生头文件给第三方用,bison产生的头文件里的哪些定义部分也是要出现在.c文件里的,否则根本就编译不了。那么即便产生了头文件而你没有定义%define api.header.include {"basename.h"}而产生的.c文件照样会自动帮你加上这个include头文件部分,所以,这里的例子纯粹在误导用户以为.y定义的部分必须要通过用户主动引用自己产生的头文件才能定义,这个是导致我很多错觉的根本原因。YYSTYPE或者使用
%define api.value.type来定义,而可能选项则只有none,union,union-directive,variant,yystype如果定义了union之后可以不用一次定义所有的union的类型,而是采用tag的方式来定义每个的类型。%language "c++"有一个不正确的认识,因为这个产生c++接口是一个非常大的差别,也许是不值得,因为有很多所谓的和yacc不兼容的问题吧?还是坚持使用c语言接口就好了。这里的潜在的意思就是说yyo是FILE*所以并不能当作cout来使用。所以,
%printer { fprintf (yyo, "%i", $$); } <int>;这里的类型tag我认为和定义的时候是类似的方法,它应该是在parse.trace开关打开的时候的默认输出吧?
%verbose是产生所谓的bison的output文件,也就是类似于html的文本输出文件,后缀名默认就是.output,这个是一个简化bison开关的好对策。%define parse.trace也是产生debug代码的可能性,真正运行期也依靠yydebug=1;在代码里打开。
int yylex (void);
void yyerror (char const *);
YYEOF/YYUNDEF这些宏总是可以使用的。
十二月二十三日 等待变化等待机会
%printer实际上并无神奇之处,它仅仅是被插入到debug输出的部分,因此不要指望这个所谓的yyo是一个全局变量,它仅仅是一个所谓的
static void yy_symbol_value_print (FILE *yyo, yysymbol_kind_t yykind, YYSTYPE const * const yyvaluep)
YYLOCATION_PRINT (stdout, &@1);这个也是纯粹的为%debug输出的,如果不定义这个宏的话编译就会出错,其实似乎没有必要用户自己主动在代码里调用它,因为你要debug就每一行都输出才对啊?没有必要专门去debug某几行的代码,不是吗?不过这个确实是一个被我误解的。
top要保证这部分在最开始
%locations这个宏不要随便使用,因为配合%debug它应该是在各个调用函数里添加这个location的参数,这个是让我错手不及。%require "3.2"当然表明语言是绝对必须的%language "c++"%define parse.trace在c++接口下,全局变量yydebug是纯c语言的接口办法就不适用了,需要使用所谓的parser.set_debug_level(1);%define api.value.type variant%define api.token.constructor比如我定义了一个token是%token <std::string> WORD;那么我们可以放心的让bison产生一个ctor函数叫做parser::make_WORD它只需要一个参数类型是stringmaybeword,那么对于其他的nterm呢?
这里我们利用%empty来创建default ctor,然后在sequence里当作vector来把variant装入。
result:
sequence {std::cout<<$1<<std::endl;}
;
auto yylex () -> parser::symbol_type这个symbol_type是一个相当复杂的部分这就是为什么使用make_WORD这样子的ctor来处理了。我仿照例子做了一个简单的,注意参照作者建议使用namespace yy来避免代码冲突
parse()方法
十二月二十四日 等待变化等待机会
%glr-parser不支持这个%define api.value.type variant%skeleton "glr2.cc"
In C, all names are lexically scoped, so it is certainly possible to resolve x at compile time. But the resolution is not context-free. Since GLR is also a technique for parsing context-free grammars, using a GLR parser won't directly help you. It might be useful in the sense that GLR parsers can theoretically produce "parse forests" rather than parse trees; that is, the output of a GLR parser might effectively contain all possible correct parses, leaving the possibility to resolve the ambiguity by building symbol tables for each scope and then choosing between alternative parses by examining the name binding in effect at each site. (This works because type alias declarations -- "typedefs" -- are not ambiguous, so all the potential parses will have the same alias declarations.)
这个lexically scoped是什么概念?那么这个做法
resolve the ambiguity by building symbol tables for each scope难道不是最根本的办法吗?难道还有别的可能吗?这里提到的
choosing between alternative parses by examining the name binding in effect at each site似乎说明了bison-glr的算法?这方面的资料很有限,看代码其实不太容易,因为似乎是m4的形式,我要找一下它产生的代码在哪里。总之,这个帖子是相当的有水平的。大侠也提到了
lexical feedback或者说
the lexer hack,但是我是很抵制这个也许是最后没有办法的办法才行吧?可是据说模板只能这么做???
十二月二十五日 等待变化等待机会
m4产生的,而读取它似乎又有一个语法也是产生的代码,所以我才印象中找不到glr的代码因为看不懂m4,而如何产生真的是一个超乎想像的复杂过程。bison的编译过程的复杂是给我一开始留下深刻印象的,因为这个过程看样子是要有很大的所谓的自持不可过分的依赖于外界我现在看到了官方的说
Bison is self-hosted它有如下的好处:
。总之,很不简单。绝非一般的开源项目那么司空见惯。
- dogfooding: let Bison be its first user
- monitoring: seeing the diff on the generated parsers with git is very helpful, as it allows to see easily the impact of the changes on a real case parser.
glr2.cc似乎并不是官方支持的接口
glr.cc A Generalized LR C++ parser. Actually a C++ wrapper around glr.c.看样子这个是非常复杂的部分,也许还没有稳定下来?这个过程有多复杂呢?首先,skeleton部分的代码是
m4写的,不知道要怎么转化应该就是m4,但是有一个scan-skel.l来扫描,这个应该是在这之前还是之后呢?或者这个难道只是为了防止flex的一个bug的重新实现?这里的复杂度超出了我的认知。
Bison is written using Bison grammars, so there are bootstrapping issues. The bootstrap script attempts to discover when the C code generated from the grammars is out of date, and to bootstrap with an out-of-date version of the C code, but the process is not foolproof. Also, you may run into similar problems yourself if you modify Bison.这里的学问很深我还无法想像。
The parsing algorithm is same (at least in theory) for all LR parsers. They differ only in the tables generated by the parser generator. In our case, Bison generates LALR(1) parsing tables in the form of C/C++ arrays. The generated yyparse() function implements a parsing routine that uses these tables and a stack to guide the parse.
这个要怎么理解呢?难道说的是dragon书里的理论做法也是这样吗?大师提到的入门书我一本都没有看过。改正了大师语法中漏掉的引号。这里在比较手写的表和bison产生的表,我看不出两个有什么压缩的区别。这里是我不知道的
The empty slots in the action part of the table are errors; The empty slots in GOTO part is NOT errors, but simply unreachable; It is impossible to detect an error on a non-terminal symbol because of the correctness of the LR algorithm.怎么理解GOTO的空白是不可能的呢?是说如果按照正确的算法根本不可能看到不可能看到的token?这个要怎么理解呢?这个是要flex的tokenizer要配合才行的还是本身算法就决定了?理解错了因为GOTO部分都是nonterminal,那么这个不是取决于flex的返回的实际的token,因为nonterminal是由语法规则决定的,除非算法有错否则空白就是不可能的。这个应该是很容易理解的我却没有意识到。所以这部分表格是可以省略压缩的。 这里是大师的预告:
Instead of generating a big sparse matrix like the one shown above, Bison generates several smaller one dimensional tables as C arrays. Not all tables are used directly by the parsing routine - some are used to print debugging information and error recovery.
There is no notion of "final state" in theoretical LALR parsing (although it exists in an LR(0) characteristic FSM),
十二月二十六日 等待变化等待机会
double displacement的压缩方法我还没有仔细的去理解但是还是有很大帮助的
default action因为我当初看到这个完全不能理解为什么有default,这里是对于所有拥有reduce action的状态选取一个出现频率最多的reduce作为它的default,以便使用一个一维数组来表达这个稀疏矩阵的最大
公约,也就是概率最大的行动,我相信这个对于CPU芯片设计肯定是有意义的算法。当然对于只存在shift的状态是没有default的。
$end,而256分配给了error然后基本上是顺序排列下去,字符串似乎不是按照字典的顺序排序,我怀疑有某种hash算法来指导这个顺序。总共数量有一两百个。$accept标号是140不知道这个是怎么选取的,然后是所有的nonterminal依靠字典顺序排列。大约有三百多个。%empty语法保持原本委员会的语法的情况下。double displacement是一个相当巧妙的算法。首先我们要理解我们的目的是什么,我们在使用所谓的default去除了那些只有reduce的状态之后就要对付那些剩下的shift的状态行,我把大师的表增加了行号和列号并且去除了状态号以便帮助查询,也就是说问题转化为如何有效率的用两个一维数组来表达这个稀疏的矩阵!这里有一个隐含条件就是我们只关心有数值的格子,如果你要计算那些空白的部分我们就无能为力了毕竟把二维数组压缩为两个一维数组是不可能表达所有信息的。
大师使用了这样两个数组
列号/行号 0 1 2 3 4 5 0 1 2 1 1 2 2 9 8 3 10 3 9 4 11 5 1 2 6 1 2 11 7 10
这两个数组的生成我不知道是什么方法,但是它能够依据这个公式来计算我们关心的那些有数值的格子:D = {4,6,0,0,12,9,8,0,13} and T = {9,10,1,2,11,8,1,2,1,2,1,2,9,11,10}
T[D[row]+col]比如我们知道矩阵row=2,col=0的数值是9,那么公式就是T[D[2]+0]=9
test/bison因为src/bison会使用系统的skeleton之类的,我之前就遇到这个问题无奈之下只好安装了最新版的bison到我的ubuntu,这个是非常不可取的行为。NEWS里看到很多的信息,这些是最新版3.8的相关信息:
%printer是目前推荐的方式,这个宏YYPRINT已经被放弃了。
The %printer directive defines code that is called when a symbol is reported.
%printer { code } symbols
Invoke the braced code whenever the parser reports one of the symbols. Within
code, $$ (or $<tag>$) designates the semantic value associated with the reported
symbol, and @$ designates its location.
glr2.cc被提到最终将取代glr.cc,大师也自己说还需要用户反馈还不成熟。yytoken_kind_t取代enum yytokentype,
This type now also includes tokens that were previously hidden: YYEOF (end of input), YYUNDEF (undefined token), and YYerror (error token). They now have string aliases, internationalized when internationalization is enabled. Therefore, by default, error messages now refer to "end of file" (internationalized) rather than the cryptic "$end", or to "invalid token" rather than "$undefined".
%header来输出头文件。命令行-H.--header虽然有最高优先级,但是我喜欢命令行单一的做法。--html是推荐的做法?The xsltproc program must be available.
User actions may now use `YYNOMEM` (similar to `YYACCEPT` and `YYABORT`) to abort the current parse with memory exhaustion.
The `YYLOCATION_PRINT(File, Loc)` macro prints a location. It is defined
when (i) locations are enabled, (ii) the default type for locations is
used, (iii) debug traces are enabled, and (iv) `YYLOCATION_PRINT` is not
already defined.
我要是早读到这个也就不会疑惑了,但是说老实话我之前读这个一定不知所云。
GLR traces要怎么理解?
There were no debug traces for deferred calls to user actions. They are logged now.log在哪里?
十二月二十七日 等待变化等待机会
AM_V_GEN查手册才知道是内部的函数:
You can use the predefined variable AM_V_GEN as a prefix to commands that should output a status line in silent mode, and AM_V_at as a prefix to commands that should not output anything in silent mode. When output is to be verbose, both of these variables will expand to the empty string.所以,现在看这个命令就明白是怎么回事了:
# Create $@~ which is the previous contents. Don't use 'mv' here so
# that even if we are interrupted, the file is still available for
# diff in the next run. Note that $@ might not exist yet.
$(AM_V_GEN){ test ! -f $@ || cat $@; } >$@~
mv,大师对于文件拷贝cp有什么成见吗?我不太明白其中的奥妙也许cp可以被打断而shell命令cat $@>$@~是一个不可被打断的atomic?而且我一开始不明所以以为$@~是什么特殊变量,现在才知道仅仅是unix的备份文件的惯例,比如vim总是这么做的,而我的老朋友$@也不是automake的专属,而是unix/shell的惯例:
就是说对于多个参数尤其是参数含有空白字符最正确的做法是"$@"The difference between the two syntaxes shows up when you have an argument with spaces in it (e.g.) and put
$@in double quotes:wrappedProgram "$@" # ^^^ this is correct and will hand over all arguments in the way # we received them, i. e. as several arguments, each of them # containing all the spaces and other uglinesses they have. wrappedProgram "$*" # ^^^ this will hand over exactly one argument, containing all # original arguments, separated by single spaces. wrappedProgram $* # ^^^ this will join all arguments by single spaces as well and # will then split the string as the shell does on the command # line, thus it will split an argument containing spaces into # several arguments.Example: Calling
wrapper "one two three" four five "six seven"will result in:
"$@": wrappedProgram "one two three" four five "six seven" "$*": wrappedProgram "one two three four five six seven" ^^^^ These spaces are part of the first argument and are not changed. $*: wrappedProgram one two three four five six seven
毕竟不是很干净的做法。 那么这样子
- set -x : Display commands and their arguments as they are executed.
- set -v : Display shell input lines as they are read.
make SHELL='sh -x'做是不是overkill呢?这个实际上不是Makefile专属的方式而是所有的shellscripting的方式,噪音肯定是多得多了。
输出大小138K
make -p如何呢?
-p, --print-data-base
Print the data base (rules and variable values) that results from reading the make‐
files; then execute as usual or as otherwise specified. This also prints the version
information given by the -v switch (see below). To print the data base without try‐
ing to remake any files, use make -p -f/dev/null.
但是这个毕竟是debug的做法我又不是make的开发者,感觉这个也是有一点点的不好。比如用最基本的make --debug=jhttps://linux.die.net/man/1/make
--debug[=FLAGS]
Print debugging information in addition to normal processing. If the FLAGS are omitted, then the behavior is the same as if
-dwas specified. FLAGS may be a for all debugging output (same as using-d),bfor basic debugging,vfor more verbose basic debugging,ifor showing implicit rules,jfor details on invocation of commands, andmfor debugging while remaking makefiles.
-b输出看看大小。这个输出是最少的,但是是否是最清楚的呢?输出大小52K
make AM_DEFAULT_VERBOSITY=1
这个其实和make V=1或者make VERBOSE=1是等价的,我一开始以为这个开关是环境变量实际上不行。
输出大小132K
make -n这个dryrun如何呢?
-n, --just-print, --dry-run, --recon
Print the commands that would be executed, but do not execute them (except in certain
circumstances).
make --trace我感觉还是在debug的味道,输出噪音也不少。输出大小664Kmake -n因为它基本上就是输出我关心的命令部分。
scan-skel.l的理解上了,可是在哪里做m4的呢?我找到代码output.c里看样子可以模拟一下运行了!找到一个没有公开的trace方法,就是-T
static const argmatch_trace_arg argmatch_trace_args[] =
{
{ "none", trace_none },
{ "locations", trace_locations },
{ "scan", trace_scan },
{ "parse", trace_parse },
{ "automaton", trace_automaton },
{ "bitsets", trace_bitsets },
{ "closure", trace_closure },
{ "grammar", trace_grammar },
{ "resource", trace_resource },
{ "sets", trace_sets },
{ "muscles", trace_muscles },
{ "tools", trace_tools },
{ "m4-early", trace_m4_early },
{ "m4", trace_m4 },
{ "skeleton", trace_skeleton },
{ "time", trace_time },
{ "ielr", trace_ielr },
{ "cex", trace_cex },
{ "all", trace_all },
{ NULL, trace_none},
};
~/Downloads/bison-git/tests/bison -Ttools word.y -o word.cc2仅仅输出这么一行命令行参数running: /usr/bin/m4 --gnu -I /home/nick/Downloads/bison-git/data /home/nick/Downloads/bison-git/data/m4sugar/m4sugar.m4 - /home/nick/Downloads/bison-git/data/skeletons/bison.m4 /home/nick/Downloads/bison-git/data/skeletons/glr2.ccbison -Tskeleton就是在输出scan-skel.l的trace情况。这个纯粹是flex的情况,似乎我不应该太关心。m4-early,m4基本就是m4的宏替换部分,我还到不了那个关心程度。time大致上就是运行time m4的样子。scan是扫描用户.l的tracelocations,resource,cex应该是还没有实现。看代码应该也是。grammar,automaton, losure,sets对于分析.y语法是非常的有用的,当然大部分都是我以前看到过的。parse也是最广泛应用的,不过相当的复杂。bitsets顾名思义除非你专门感兴趣的话?muscles可能是最接近我想要看到的吧?实际上我也不知道要看什么关键是可能也看不懂。The bits of information passing from bison to the backend is named "muscles". Muscles are passed to M4 via its standard input: it's a set of m4 definitions. To see them, use --trace=muscles.我现在已经知道命令行就是这个,而且这个就是通过stdin的,那么内容是什么呢?我如果把
muscle的输出传入如何呢?
确实是这样子的,我把-Tmuscles的输出存储正文件去掉不相干的部分,然后用这个命令行就得到了正宗的glr2.cc的源码!现在我有一点点明白为什么是叫做muscle了,因为我们写的.y文件就是这些muscle,而bison产生的代码就是骨架所以是skeleton,而这些总是相对于我们的肉不同而产生的不同的骨架,这里有大量的宏替换所以才用到m4。要看懂这些代码对于bison的数据结构是一定要清楚的,所以,我估计还是要回到之前的那个教授的关于bison压缩表的讲解。不过我今天还是有收获的,至少有了一个方向!我今天可以好好睡一觉了吗?应该是吧?
雄关漫道真如铁,而今迈步从头越!我竟然忘了昨天是毛主席他老人家诞辰日。
十二月二十八日 等待变化等待机会
muscle实际上就是一些以一定格式定义好的作为m4的操作对象,这个包含了用户定义的语法经过转换后的各种元素,我猜想包含了各种表等等数据结构,但是他们是要被m4填补到所谓的预先设计好的所谓的
skeleton比如glr2.cc里面。我觉得我可能是理解力的问题,这么浅显的道理从名字都能猜出来,为什么我费了这么多力气才明白?这就是我昨天看到的,也就是说使用
-Ttools看到了m4的执行的参数,这个是使用所谓的stdin的原因是bison的output.c里运用了pipe来和m4这个子进程来交互,也就是说创建一个m4的这样一个子进程于是m4就在pipe的那一头读,而bison着一头写入muscle,很自然的m4在另一头写结果,而这里一个细节我昨天没有意识到就是bison这里读结果使用了另一个flex就是
scan-skel.l产生的代码来过滤,这就是为什么我如果仅仅看m4的输出结果还有好些宏没有替换比如basename。这其中的机制当然是很复杂的,单单使用m4通过pipe就是一个复杂的过程,我注意到m4是可以直接通过文件输入的,当然编程是不能接受这个做法的。我现在也明白了另一个细节就是为什么bison需要自带一个gnulib这么麻烦,原因就是它用到了很多如pipe以及创建子进程的syscall,而bison需要自持不依赖于任何平台的库,也就是跨平台跨语言实现,所以只好自己统统实现一遍,否则但从算法看没有必要把系统库都带着。
glr_stack它的很多方法就揭示了原理,这个是我重点要看的。它的很多私有方法是我感兴趣的。十二月二十九日 等待变化等待机会
token_kind_type特指terminal,而symbol_kind_type包含了terminal和nonterminal,所以,它作为c++接口的yylex的返回值类型。值得注意的是几个特殊预设值除了YYEMPTY=-2,YYEOF=0在两者重复定义了以外,其他S_YYerror,S_YYUNDEF重复定义值是不一样的!在后者作为yylex的返回值是连续的enum因为不需要考虑前者兼容255个ASCII字符值的羁绊,而且命名也很简单:都是.y文件里的terminal/nonterminal直接加上一个前缀S_,遇到bison允许的hyphen的情况就都改为underscore摒弃改前缀为S_number_,这里的number是当前的symbol_kind的enum序列号。最后就是一个特殊的值YYNTOKENS出现在第一个实际上的值是所有symbol的个数。这里它会和某一个七它的symbol值冲突因为总的enum还包含了那些特殊定义的,所以,要小心。
void parser::by_kind::move (by_kind& that){
kind_ = that.kind_;
that.clear ();
}
std::move();就万事大吉等着天上掉馅饼而是要自己去真的做到让move起到应有的swap的作用!目前尽管by_kind是一个仅仅包含一个enum的空结构可是谁能保证它将来不扩展呢?parse()里,这里是唯一设定了setjmp的地方,那么相应的我们看看在哪里调用了longjmp呢?一个是yyMemoryExhausted另一个是yyFail,所以,我们可以理解这是某种类似于try/catch的机制实现?前者返回值为2,后者为1,那么针对两个返回值分别跳转到相应的处理,不过这些都是意外的处理,真正的逻辑在下面。this->yyglrShift (create_state_set_index(0), 0, 0, this->yyla.value);这个看起来没有多少的悬念,我摘录注释我唯一的报怨是这里使用shift让我感到困惑因为我还以为是某个terninal采用shift,状态不是用goto吗?
/** Shift to a new state on stack #YYK of *YYSTACKP, corresponding to LR
* state YYLRSTATE, at input position YYPOSN, with (resolved) semantic
* value YYVAL_ARG and source location YYLOC_ARG. */
void
yyglrShift (state_set_index yyk, state_num yylrState,
size_t yyposn,
const value_type& yyval_arg)
variant的方式用指针来传递,比如我定义了st::variant的高级类型,但是bison还是使用指针类对付所有的这些哪怕它不是variant,我看到过bison的文档解释说bison的实现不想依赖于boost::variant的实现,大概那个时候c++标准还没有采纳variant的实现吧?说白了就是怎么实现value_type的各种操作的问题,比如copy和创建传参数等等。
predict有异曲同工之妙:只要你没有shift新的nonterminal你随便reduce将来一定会出错的,这个是由deterministice state automaton决定的!你以为一个傻子偶然随便一指碰巧得到了正确的选择那么你会一直这么好运气吗?不可能哪怕你一直有好运气你在错误的路口犯一次错误就死定了。但是这个有什么好处呢?我的理解就是先不用思考直接道路依赖走你认为最可能的道路,等到你碰壁在回头去做recovery,这个也许在实践中是有高效率的吧?因为大多数时候人凭本能而不是每一步都确定计算要快的多,回头调整反而总的时间更短,这个是我的理解,否则intel/AMD的CPU为何要做那种预测转向?只要你能区分真正的错误和这种投机取巧的default-action的错误就好了。
yyglrReduce我摘录注释
/** Pop items off stack #YYK of *YYSTACKP according to grammar rule YYRULE,
* and push back on the resulting nonterminal symbol. Perform the
* semantic action associated with YYRULE and store its value with the
* newly pushed state, if YYFORCEEVAL or if *YYSTACKP is currently
* unambiguous. Otherwise, store the deferred semantic action with
* the new state. If the new state would have an identical input
* position, LR state, and predecessor to an existing state on the stack,
* it is identified with that existing state, eliminating stack #YYK from
* *YYSTACKP. In this case, the semantic value is
* added to the options for the existing state's semantic value.
*/
YYRESULTTAG yyglrReduce (state_set_index yyk, rule_num yyrule, bool yyforceEval)
symbol_type yyla;几乎就是万能的,它就是当前处理的一切,它的kind()/value()/location(), %empty,你要表达一个循环当然要使用%empty,但是这个是循环的功能,除此之外。。。给我的感觉就像是军队领导体制一样要精干不要有越级现象,而要各司其职,不要有冗余。这个感觉说起来容易做起来真的好难。比如委员会的这个语法你敢质疑它的冗余度吗?这个语法只是为了说明想法并不是一个面向工作的精干的做法,描述同样的客观事物可以有容易的做法也可以有很困难和很精确的做法。前者一言以蔽之,大而无当四平八稳肯定不会出错仿佛大首长的官话套话没人敢说不对然而对于实际工作的指导鲜有所指;而后者精准犀利切中时弊深入浅出,而且更重要的要做到西方法庭宣誓的the truth, the whole truth and nothing but the truth就是说覆盖了所有的情况但是又不覆盖任何不需要的情况,这个实在是很难。
十二月三十日 等待变化等待机会
location实现,我不想费劲想要使用默认的结果遇到很多编译错误,最后不知道怎么样子的又消失了:
%skeleton "glr2.cc" // -*- C++ -*-
%require "3.8.2"
%header
%define api.value.type variant
%define api.token.constructor
api.token.constructor的选项于是lexer文件里我需要这么一些东西就是对于每一个token,我都要返回yy::parser::make_TOKENNAME();,这里我不打算自定义location而且我也没有在.y文件里定义选项%locations,于是这些token不需要location参数而使用默认实现。
parser.hh: In constructor ‘yy::parser::value_type::value_type()’:
parser.hh:135:20: error: ‘YY_NULLPTR’ was not declared in this scope
, yytypeid_ (YY_NULLPTR)
^~~~~~~~~~
parser.hh: In member function ‘void yy::parser::value_type::destroy()’:
parser.hh:293:19: error: ‘YY_NULLPTR’ was not declared in this scope
yytypeid_ = YY_NULLPTR;
^~~~~~~~~~
# ifndef YY_NULLPTR
# if defined __cplusplus
# if 201103L <= __cplusplus
# define YY_NULLPTR nullptr
# else
# define YY_NULLPTR 0
# endif
# else
# define YY_NULLPTR ((void*)0)
# endif
# endif
%token <std::string> IDENTIFIER "identifier"这里我记错了,对于terminal你可以赋予一个alias,而对于%nterm你是不能给alias的。yylex这个函数要如何定义,因为在c语言接口下这个就是很简单的返回整数不带参数的int yylex()由flex帮你去实现,可是在c++接口下这个函数变成了yy::parser::symbol_type yylex (),而且似乎你要让flex和bison都知道你要这么定义,这样子就最好定义在一个单独的头文件里让.l和.y都引用,而且把它定义为这个宏YY_DECLdriver的概念,如果使用c++的
glr2.cc之类的skeleton那么就意味着我们的parser是一个在名字空间yy的类parser我们需要调用它的parse()成员函数看它的返回值如何。但是这里有一个传递lexer输入文件参数的问题。之前的c语言接口我都是使用flex定义的全局变量yyin那么现在我们的parser类如果能够自己传递这个文件名参数给lexer就好了,所以,我们在.y文件里定义了我们想把我们用户定义的driver类实例传递给我们的parser的constructor
%param { driver& drv }
这样子在产生的代码里parser::parser (driver& drv_yyarg)
同样类似的我们也希望把这个driver类传递给yylex,我记得原本有一个参数%lex-param,但是我觉得这个是同时做%parse-param的
%param { argument-declaration } . . . [Directive]
Specify that argument-declaration are additional yylex/yyparse argument declaration.
This is equivalent to
%lex-param {argument-declaration} ...
%parse-param {argument-declaration} ...
You may pass one or more declarations, which is equivalent to repeating %param.
driver类作为参数传递给lexer和parser的用意在lexer方面是为了接受用户输入的输入文件名来设定yyin以便开始扫描,同时对于一些我们无法指望bison自动定义api.token.constructor选项的我们要帮助实现。这里bison会自动根据token的名字实现一个简单的symbol_type的constructor,比如我们定义了这个IDENTIFIER的token,而且它的type tag是std::string,那么bison就会使用这个类型作参数返回一个这样的symbol:
static symbol_type make_IDENTIFIER (std::string v)
{
return symbol_type (token::IDENTIFIER, std::move (v));
}
symbol_type来包装它,这就是为什么我们需要调用一系列这种make_TOKENNAME函数的原因。
对于我们不在于semantical value的无类型的token那么bison产生的就是一个空空的无参数的constructor
static symbol_type make_RPAREN ()
{
return symbol_type (token::RPAREN);
}
")" return yy::parser::make_RPAREN();
浩如烟海的巨大的union的
森林s是能够把人折磨死了,不是说不好因为它是存储访问效率最高的做法,但是依赖于巨大数量的宏来访问是非常的难以维护以及debug的,我依赖代码注释里学习摸索了几个月也仅仅懂了很少数的常用的宏,还有巨大数量的union/macro藏在某些注释里,在这种没有办法维持的模式下开发实在是太困难了。我甚至常常认为最早的开发者是有一个观念大概c++语言在c++98就被封存因此他们的代码将成为不朽,而没有后人需要再去改变添加因为这个正如同
历史终结论一样在当时很有说服力。那么新时代的语言引入了variant据说是一个更加安全的union,这个当然是使用bison/c++接口的期望,不过bison内部并非纯粹的c++的实现而是使用指针来包藏复杂的数据类型来实现一个variant,但是这个应该不是问题吧?总之在我们的driver里面隐藏这些数据结构来承接各个token的sematic值是这么做的最主要的目的吧? 这也就是我需要定义这个宏的原因,我之前遇到的种种的问题很多都是来源于这个宏
# define YY_DECL yy::parser::symbol_type yylex (driver& drv)%param { driver& drv },然后在我们的driver里是这么调用的:
yy::parser parse (*this);
this当然是我们的driver了。
十二月三十一日 等待变化等待机会
spaceship<=>总是不能reach这个让我疑惑了很久最后把它放在第一位才解决,总是flex是能够发现你的regex过多的覆盖其他token的问题,我感觉这个不是最长match 的问题,因为flex的行号总是多一个让我一开始有这种困惑。这个也许可以算是一个里程碑吧?尽管几乎什么也没有做到,但是毕竟编译成功了。
这里也是我早上烦恼了很久的东西,一个是
- Directive: %define api.token.raw ¶
- Language(s): all
- Purpose: The output files normally define the enumeration of the token kinds with Yacc-compatible token codes: sequential numbers starting at 257 except for single character tokens which stand for themselves (e.g., in ASCII, ‘'a'’ is numbered 65). The parser however uses symbol kinds which are assigned numbers sequentially starting at 0. Therefore each time the scanner returns an (external) token kind, it must be mapped to the (internal) symbol kind.
When
api.token.rawis set, the code of the token kinds are forced to coincide with the symbol kind. This saves one table lookup per token to map them from the token kind to the symbol kind, and also saves the generation of the mapping table. The gain is typically moderate, but in extreme cases (very simple user actions), a 10% improvement can be observed.When
api.token.rawis set, the grammar cannot use character literals (such as ‘'a'’).- Accepted Values: Boolean.
- Default Value:
truein D,falseotherwise- History: introduced in Bison 3.5. Was initially introduced in Bison 1.25 as ‘%raw’, but never worked and was removed in Bison 1.29.
token_kind一个是symbol_kind,前者应该是flex使用的enum定义的是lexer范畴可见的概念,后者是parser重新map的中间不再预留给ASCII字符256空间的连续enum,而且bison针对它重新命名添加前缀S_,这个之前我已经注意到了,这个指示可以修改默认的前缀:%define api.token.prefix {TOK_},之前我还没有明白这个指示的意义现在才彻底明白,就是说bison为flex产生的enum的token_kind的前缀加了TOK_,而bison自己产生的parser的symbol_kind的前缀依旧是S_这个没有亲自做实验还是一知半解理解错误,好在这个token_kind我们基本不会用到,原因是我们使用的yylex返回的已经是symbol_kind,而它使用的成员函数返回kind()的enum就是那个加前缀S_的symbol_kind,我们不会再用到flex的原始的token_kind,不过我的疑问其实是在于我是否保证我的语法中不会再有使用ASCII字符的问题?比如纯虚函数最后声明=0,这个0我是否也定义了?我感觉不行,因为我的语法里依旧把它定义为字符'0',所以,还是不要着急盲目。
期盼
十四亿人众志城, 百年党庆踏新征。 神州终将成一统, 万事具备盼东风。
有感于中美大乱斗世界不太平,看来明年又是一个斗争的年头
又是年尾接年头, 东边欢喜西方愁。 当春不撒幸福种, 坐待秋来收恨仇。
岁末有感
岁末年初夜色稠, 回首一载添乡愁。 全球变暖疫情乱, 地缘政治一锅粥。 大国崛起冲霄汉, 美帝岂有善罢休? 生逢乱世何所幸? 唯有亲情记心头。
![]()
{kind=link}